One of my earlier blog posts, and the all time most popular one, was about how to make URL rewriting on IIS 7 work like IIS 6. While my method did provide a means to the goal, it’s humiliatingly far from what I should’ve done. Since the old post is still the most visited post on my blog I feel obligated to write a followup on how to do proper url rewriting in IIS 7.
The scenario
I’ll assume a completely vanilla IIS 7 setup, contrary to the old post, there’s no IIS tampering required.
I’ve setup a simple web application solution structure like so:
As in the original post my goal is to accept a URL like http://localhost/blog/2006/12/08/missing-windows-mobile-device-center and map it to the BlogPost.aspx file in the root of my application. During the rewrite process I want to make the year, month, day and title available for the BlogPost.aspx file in an easily accessible way.
Rewriting using Global.asax
The easiest way of rewriting URL’s is to add a new Global.asax file to the root of your solution. Now paste in the following code:
using System;
using System.Text.RegularExpressions;
using System.Web;
namespace IIS7UrlRewritingDoneProperly
{
publicclass Global : HttpApplication
{
// Runs at the beginning of each request to the serverprotectedvoidApplication_BeginRequest(object sender, EventArgs e)
{
// Match the specific blog post URL path as well as pull out variables in regex groups
Match m = Regex.Match(Request.Url.LocalPath, @"^/blog/(?<year>d{4})/(?<month>d{2})/(?<day>d{2})/(?<title>.*)/?$");
// If we match a blog posts URL, save the URL variables in Context.Items and rewrite to /BlogPost.aspxif (m.Success)
{
Context.Items["Title"] = m.Groups["title"].Value;
Context.Items["Year"] = m.Groups["year"].Value;
Context.Items["Month"] = m.Groups["month"].Value;
Context.Items["Day"] = m.Groups["day"].Value;
HttpContext.Current.RewritePath("/BlogPost.aspx");
}
}
}
}
Now all you need is a single change in your web.config file:
The web.config change basically does the same as adding the wildcard map in IIS6. It ensures ASP.NET will run our Application_BeginRequest function for all requests - both those that match .aspx files as well as those for static files.
Rewriting using an HttpModule
As an alternative to putting the rewriting logic into Global.asax, you might want to write it into a distributable HttpModule. If your URL rewriting functionality is common for multiple sites, generic or for any other reason may be usable on multiple sites, we don’t want to replicate the functionality in Global.asax.
If you added the Global.asax file from before, make sure you remove it again so it doesn’t conflict with the HttpModule we’re about to write. Add a new class project to the solution - I’ve called mine MyUrlRewriter. Add a reference to System.Web and add a single new class file to the project called UrlRewriter. Your solution should look like this:
Now paste the following code into the UrlRewriter.cs class file:
using System;
using System.Text.RegularExpressions;
using System.Web;
namespace MyUrlRewriter
{
publicclass UrlRewriter : IHttpModule
{
// We've got nothing to dispose in this modulepublicvoidDispose()
{ }
// In here we can hook up to any of the ASP.NET events we use in Global.asaxpublicvoidInit(HttpApplication context)
{
context.BeginRequest += new EventHandler(context_BeginRequest);
}
// This method does exactly the same as in Global.asaxprivatevoidcontext_BeginRequest(object sender, EventArgs e)
{
// Match the specific blog post URL path as well as pull out variables in regex groups
Match m = Regex.Match(HttpContext.Current.Request.Url.LocalPath, @"^/blog/(?<year>d{4})/(?<month>d{2})/(?<day>d{2})/(?<title>.*)/?$");
// If we match a blog posts URL, save the URL variables in Context.Items and rewrite to /BlogPost.aspxif (m.Success)
{
HttpContext.Current.Items["Title"] = m.Groups["title"].Value;
HttpContext.Current.Items["Year"] = m.Groups["year"].Value;
HttpContext.Current.Items["Month"] = m.Groups["month"].Value;
HttpContext.Current.Items["Day"] = m.Groups["day"].Value;
HttpContext.Current.RewritePath("/BlogPost.aspx");
}
}
}
}
Notice that the context_BeginRequest function is identical to the one we had in Global.asax, except we have to reference HttpContext.Current explicitly since it’s not implicitly available as in Global.asax.
Now add a reference from the original web application project to the MyUrlRewriter class project. Once this is done we just need to ensure our HttpModule is included in our web application by modifying the web.config:
At this point you should be able to run the website with the exact same URL rewriting functionality as we had before - though this time in a redistributable assembly called MyUrlRewriter.dll which can easily be included into any website by adding a single line to the section of the web.config file.
Not Invented Here Syndrome
If you have basic requirements to your URL rewriting solution you may often be able to settle with one of the many readymade HttpModules that you can simply plug into your application. IIS 7 also has a URL Rewrite Module that you can install and easily configure through the IIS manager.
On numerous occations I’ve had a need for synchronizing directories of files & subdirectories. I’ve used it for synchronizing work files from my stationary PC to my laptop in the pre-always-on era (today I use SVN for almost all files that needs to be in synch). Recently I needed to implement a very KISS backup solution that simply synchronized two directories once a week for offsite storing of the backup data.
While seemingly simple the only hitch was that there would be several thousands of files in binary format, so compression was out of the question. All changes would be additions and deletions - that is, no incremental updates. Finally I’d only have access to the files through a share so it wouldn’t be possible to deploy a local backup solution that monitored for changes and only sent diffs.
I started out using ViceVersa PRO with the VVEngine addon for scheduling. It worked great for some time although it wasn’t the most speedy solution given my scenario. Some time later ViceVersa stopped working. Apparently it was simply unable to handle more than a million files (give or take a bit). Their forums are filled with people asking for solutions, though the only suggestion they have is to split the backup job into several smaller jobs. Hence I started taking backups of MyShare/A, MyShare/B, etc. This quickly grew out of hand as the number of files increased.
Sometime later I was introduced to Robocopy.aspx). Robocopy ships with Vista, Win7 and Server 2008. For server 2003 and XP it can be downloaded as part of theWindows Server 2003 Resource Kit Tools.
Robocopy (Robust File Copy) does one job extremely well - it copies files. It’s run from the command line, though there has been made a wrapper GUI for it. The basic syntax for calling robocopy is:
You give it a source and a destination address and it’ll make sure all files & directories from the source are copied to the destination. If an error occurs it’ll wait for 30 seconds (configurable) before retrying, and it’ll continue doing this a million times (configurable). That means robocopy will survive a network error and just resume the copying process once the network is back up again.
What makes robocopy really shine is not it’s ability to copy files, but it’s ability to mirror one directory into another. That means it’ll not just copy files, it’ll also delete any extra files in the destination directory. In comparison to ViceVersa, robocopy goes through the directory structure in a linear fashion and in doing so doesn’t have any major requirements of memory. ViceVersa would initially scan the source and destination and then perform the comparison. As source and destination became larger and larger, more memory was required to perform the initial comparison - until a certain point where it’d just give up.
I ended up with the following command for mirroring the directories using robocopy:
/MIR specifies that robocopy should mirror the source directory and the destination directory. Beware that this may delete files at the destination.
/FFT uses fat file timing instead of NTFS. This means the granularity is a bit less precise. For across-network share operations this seems to be much more reliable - just don’t rely on the file timings to be completely precise to the second.
/Z ensures robocopy can resume the transfer of a large file in mid-file instead of restarting.
/XA:H makes robocopy ignore hidden files, usually these will be system files that we’re not interested in.
/W:5 reduces the wait time between failures to 5 seconds instead of the 30 second default.
The robocopy script can be setup as a simply Scheduled Task that runs daily, hourly, weekly etc. Note that robocopy also contains a switch that’ll make robocopy monitor the source for changes and invoke the synchronization script each time a configurable number of changes has been made. This may work in your scenario, but be aware that robocopy will not just copy the changes, it will scan the complete directory structure just like a normal mirroring procedure. If there’s a lot of files & directories, this may hamper performance.
Writing a calculator is a simple task - just add nine buttons labeled 1-9 and add a plus and minus button and we’re almost good to go. In this entry I’m going to write a calculator called SimpleCalc that does not have a GUI, instead it’ll take in an arbitrary expression and calculate the results of it. The input I’ll use as my immediate goal is the following:
25-37+2*(1.22+cos(5))*sin(5)*2+5%2*3*sqrt(5+2)
According to Google the result is -9.83033875. Some of the tricky subjects we’ll have to handle is operator precedence (multiplication before addition etc), nested expressions (2*1.22+cos(5) != 2*(1.22+cos(5))) and associativity (5+7 == 7+5 & 7-5 != 5-7 etc).
Parsing the input using SableCC
Before doing any calculations, we need to parse the input expression so we have an in-memory representation of the input. We need to have the input represented in the form of an abstract syntax tree that defines the order of operations and allows us to traverse the different parts of the expression individually. To perform this task, we’ll be using SableCC.
SableCC is a parser generator which generates fully featured object-oriented frameworks for building compilers, interpreters and other text parsers. In particular, generated frameworks include intuitive strictly-typed abstract syntax trees and tree walkers. SableCC also keeps a clean separation between machine-generated code and user-written code which leads to a shorter development cycle.
In short, SableCC can be used to automatically generate the parser code that’s used in any compiler, as well as in a lot of other cases where input needs to be parsed - like in this case. SableCC itself is written in Java by Etienne M. Gagnon and the source code is freely available.
The standard output from SableCC is Java code. Thus, the parser we’re about to generate will be made into a number of Java files that we can incorporate into our own source code and extend. As I’ll be writing the calculator in C#, I’d much prefer to work with C# source files directly, rather than having to port the Java output or call it by other means. Luckily Indrek Mandre has made a SableCC variant that’ll generate the parser in either Java, C#, C++, O’Caml, Python, C, Graphviz Dot or XML. All we need to do is to download the sablecc-3-beta.3.altgen.20041114 zip file from the frontpage of Indrek’s SableCC page. Once it’s downloaded and unpacked we’re able to run it, as long as Java is installed. First create a bat file with the following contents:
Make sure to replace my path with whatever path you’ve extracted the SableCC altgen package into. When we invoke SableCC from now on, we’ll do it through this bat file that I’ve chosen to call sablecc_altgen.bat, just to make the syntax simpler.
Defining the grammar
For SableCC to be able to generate our parser, we first need to define the language it should support. The way we do this is to define the language in the (E)BNFformat. I won’t be writing a generic tutorial on how to write grammers in SableCC as there’s already a number of good ones on the SableCC Documentation page, as well as one by Nat Pryce that’s not on the documentation page. Finally there’s also a mailing list, though the activity is limited.
We’ll start out by creating a new text file called simplecalc.sablecc, this is where we’ll be defining our SimpleCalc grammar. Furthermore I’ve created a new bat file called simplecalc_sable.bat with the following contents:
The above bat file will call the one we previously made. -d generated specifies the output directory name. -t csharp specifies the output source code type, C# in this case. The last argument is the name of the input sablecc file. From now on we can simply run simplecalc_sable to start the SableCC compilation process.
I’ll post the full simplecalc.sablecc file contents first, and then go through the specific sections one by one afterwards.
In the grammar we’re using 5 different sections, Package, Helpers, Tokens, Productions and Abstract Syntax Tree.
Package SimpleCalc;
The Package declaration simply defines the name of the overall package. If this is excluded (which is valid according to SableCC) our namesapces int he generated C# code will be blank and thus invalid.
Helpers
digit = ['0' .. '9'];
Helpers are basically placeholders you can setup and use throughout the SableCC file. They have no deeper meaning or functionality, it’s just a way to easily be able to express common code by its name. As we’ll be referring to digits multiple times it helps to define it as a helper instead of replicating [‘0’ .. ‘9’] multiple times in the code. [‘0’ .. ‘9’] means all digits between 0 and 9.
Tokens
number = (digit+ | digit+ '.' digit+);
add = '+';
sub = '-';
mul = '*';
div = '/';
mod = '%';
sqrt = 'sqrt';
cos = 'cos';
sin = 'sin';
lparen = '(';
rparen = ')';
Note that I’m jumping ahead and ignoring Productions section for now, I’ll come to that in just a bit. The Abstract Syntax Tree defines the nodes that will be present in our parsed AST. Each type of operation and function has a corresponding node in the AST. Thus, and add operation will consist of an Add node with two children - a left and a right expression. Those expressions may themselves be constant numbers or nested expressions - since they’re defined as exp which is a recursive reference to the actual AST exp type.
Add, sub, mul, div and mod are binary operators and thus have two child expressions. Paren, sqrt, cos and sin (and in some ways, number) are unary operators in that they only have a single child/parameter - an expression. Number is a leaf node that expresses an actual number constant.
The Productions section defines our mapping from the actual input to the AST that we’ve just defined.
The first production we define is a generic one for expressing expressions. Note that the way we define operator precedence is by first expressing the least prioritized operator (add & sub) and then referencing the factor operations (mul, div, mod & unary) and thus forth. exp {-> exp} signifies that the concrete syntax of an expression is mapped into the abstract syntax tree node called “exp” as well. Productions and Abstract Syntax Tree are two different namespaces and they may thus share the same names.
= {add} [left]:exp add [right]:factor {-> New exp.add(left, right.exp)}
The add operation is defined by a left expression followed by the add token (defined as ‘+’ previously) and then a factor expression on the right, hence defining the precedence relation between the add operation and factor operations. Finally we define that the add operation maps into a new instance of the exp AST node, having the left and right expressions as parameters (children in the AST). The sub operation is almost identical to the add operator.
| {factor}factor{-> factor.exp}
Any factor expressions are simply mapped onto the factor production defined later on.
The mul, div and mod expressions are basically identical to the add and sub expressions, except defining unary as the next production in the operator precedence chain.
The simplest of all expressions is the unary number expression that defines a numeric constant. The number expression is mapped into a new AST node of the type exp.number, having the actual number as a parameter. The sqrt, cos and sin functions all define the input as the function name and the parameter expression enclosed in parentheses. Finally we define the {paren} unary function which is an arbitrary expression enclosed in parentheses. This gets mapped into the exp.paren AST type, taking the arbitrary expression as a parameter. The {paren} function allows us to differentiate between expressions like “5*2-7” and “5*(2-7)”.
The final production is what allows us to chain expressions. Without the exp_list production only single operations would be allowed (5+2, 3*7 etc), not chains of expressions (5+2+3, 5*2+3 etc). exp_list {-> exp*} defines that the exp_list production maps into a list of exp’s in the AST.
Anyone having done functional programming will recognize the tail recursion going on here. If there’s only a single expression, we map it into a list of expressions containing just that one expression. If there’s a single expression and a list of expressions following it (which may be one or more expressions), we map it into a list of expressions containing the first expression as well as the rest of the expressions represented by the tail parameter.
Generating the parser
Once we’ve defined the grammar, we’re ready to run the simplecalc_sable bat file, hopefully resulting in the following output:
D:\Webmentor Projekter\Eclipse Projects\SableCC\>simplecalc_sable -d generated -t c
sharp simplecalc.sablecc
D:\Webmentor Projekter\Eclipse Projects\SableCC\>java -jar"C:Program FilesSabl
eCCsablecc-3-beta.3.altgen.20041114libsablecc.jar"-d generated -t csharp sim
plecalc.sablecc
SableCC version 3-beta.3.altgen.20040327
Copyright (C) 1997-2003 Etienne M. Gagnon <etienne.gagnon@uqam.ca>and
others.All rights reserved.
This software comes with ABSOLUTELY NO WARRANTY. This is free software,
and you are welcome to redistribute it under certain conditions.Type'sablecc -license'to view
the complete copyright notice and license.-- Generating parser for simplecalc.sablecc in D:Webmentor ProjekterEclipse P
rojectsSableCCgenerated
Verifying identifiers.
Verifying ast identifiers.
Adding empty productions and empty alternative transformation if necessary.
Adding productions and alternative transformation if necessary.
computing alternative symbol table identifiers.
Verifying production transform identifiers.
Verifying ast alternatives transform identifiers.
Generating token classes.
Generating production classes.
Generating alternative classes.
Generating analysis classes.
Generating utility classes.
Generating the lexer.
State: INITIAL
- Constructing NFA...............................- Constructing DFA........................................................................- resolving ACCEPT states.
Generating the parser...........................................................................................................................
Now if we look in the generated directory, there should be six files: analysis.cs, lexer.cs, nodes.cs, parser.cs, prods.cs and tokens.cs. The files should contain classes in the SimpleCalc namespace.
Printing the abstract syntax tree
To help ourselves, the first task we’ll do is to simply print out the AST so we can verify what gets parsed is correct. Create a solution called SimpleCalc and either copy the genrated files or create a solution link to the folder. Add a new file called AstPrinter.cs and paste the following contents:
using System;
using SimpleCalc.analysis;
using SimpleCalc.node;
namespace SimpleCalc
{
class AstPrinter : DepthFirstAdapter
{
int indent;
privatevoidprintIndent()
{
Console.Write("".PadLeft(indent, 't'));
}
privatevoidprintNode(Node node)
{
printIndent();
Console.ForegroundColor = ConsoleColor.White;
Console.Write(node.GetType().ToString().Replace("SimpleCalc.node.", ""));
if (node is ANumberExp)
{
Console.ForegroundColor = ConsoleColor.DarkGray;
Console.WriteLine(" " + node.ToString());
}
else
Console.WriteLine();
}
publicoverridevoidDefaultIn(Node node)
{
printNode(node);
indent++;
}
publicoverridevoidDefaultOut(Node node)
{
indent--;
}
}
}
The DepthFirstAdapter is a class auto generated by SableCC. It allows us to easily traverse the generated AST depth first, while giving us various hook points along the way. Each node in the tree has an In and Out method that we can override. In is called before the children are traversed while Out is called after the children have been traversed. Note that we may change the tree during the traversal - though we’re not going to do so.
In the AstPrinter class I’ve overriden the DefaultIn and DefaultOut methods that gets called for each node unless we’ve overriden their specific default methods. In the In method we increase the indent, and likewise we decrease it in the Out method. Furthermore, in the In method we also print the actual node contents to the console. If it’s a ANumberExp node (the name of the node corresponding to the number type in the AST) then we print the actual number, otherwise we just print the name of the node itself.
In the main program file, paste the following:
using System;
using System.IO;
using SimpleCalc.lexer;
using SimpleCalc.node;
using SimpleCalc.parser;
namespace SimpleCalc
{
class Program
{
privatestaticvoidMain(string[] args)
{
if (args.Length != 1)
exit("Usage: Simplecalc.exe filename");
using (StreamReader sr = new StreamReader(File.Open(args[0], FileMode.Open)))
{
// Read source
Lexer lexer = new Lexer(sr);
// Parse source
Parser parser = new Parser(lexer);
Start ast = null;
try
{
ast = parser.Parse();
}
catch (Exception ex)
{
exit(ex.ToString());
}
// Print tree
AstPrinter printer = new AstPrinter();
ast.Apply(printer);
}
exit("Done");
}
privatestaticvoidexit(string msg)
{
if (msg != null)
Console.WriteLine(msg);
else
Console.WriteLine();
Console.WriteLine("Press any key to exit...");
Console.Read();
Environment.Exit(0);
}
}
}
I’ve made it so the program takes in a single argument, a filename where our calculation expression is written. By taking a file as a parameter, it’s easier for me to change the expression directly in Visual Studio without having to setup launch parameters. The only launch parameter that needs to be set is the file argument.
The program tries to open the file and then instantiates the SableCC auto generated lexer and parser.
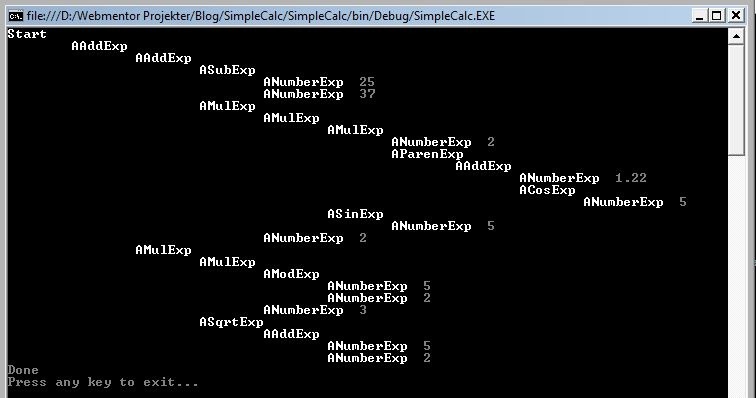
Now let’s make a new file called test.ss and paste the following expression into it: 25-37+2*(1.22+cos(5))*sin(5)*2+5%2*3*sqrt(5+2). If you run the application at this point, you should see an output like the following:
By comparing the printed AST with the input expression, we’ll see that they match both in contents and in regards to operator precedence. Now all that’s left is to perform the actual calculation of the expression.
Calculating the expression based on the abstract syntax tree
Add a new file called AstCalculator.cs and paste the following contents:
using System;
using System.Collections.Generic;
using System.Globalization;
using SimpleCalc.analysis;
using SimpleCalc.node;
namespace SimpleCalc
{
class AstCalculator : DepthFirstAdapter
{
privatedouble? result;
private Stack<double> stack = new Stack<double>();
publicdouble CalculatedResult
{
get
{
if (result == null)
thrownew InvalidOperationException("Must apply AstCalculator to the AST first.");
return result.Value;
}
}
publicoverridevoidOutStart(Start node)
{
if (stack.Count != 1)
thrownew Exception("Stack should contain only one element at end.");
result = stack.Pop();
}
// Associative operatorspublicoverridevoidOutAMulExp(AMulExp node)
{
stack.Push(stack.Pop() * stack.Pop());
}
publicoverridevoidOutAAddExp(AAddExp node)
{
stack.Push(stack.Pop() + stack.Pop());
}
// Non associative operatorspublicoverridevoidOutASubExp(ASubExp node)
{
double numB = stack.Pop();
stack.Push(stack.Pop() - numB);
}
publicoverridevoidOutAModExp(AModExp node)
{
double numB = stack.Pop();
stack.Push(stack.Pop() % numB);
}
publicoverridevoidOutADivExp(ADivExp node)
{
double numB = stack.Pop();
stack.Push(stack.Pop() / numB);
}
// UnarypublicoverridevoidOutASqrtExp(ASqrtExp node)
{
stack.Push(Math.Sqrt(stack.Pop()));
}
publicoverridevoidOutACosExp(ACosExp node)
{
stack.Push(Math.Cos(stack.Pop()));
}
publicoverridevoidOutASinExp(ASinExp node)
{
stack.Push(Math.Sin(stack.Pop()));
}
publicoverridevoidInANumberExp(ANumberExp node)
{
stack.Push(Convert.ToDouble(node.GetNumber().Text.Trim(), new CultureInfo("en-us")));
}
}
}
I will not go through all parts of the calculator as many functions are very similar. I’ll outline the important ones below.
privatedouble? result;
private Stack<double> stack = new Stack<double>();
publicdouble CalculatedResult
{
get
{
if (result == null)
thrownew InvalidOperationException("Must apply AstCalculator to the AST first.");
return result.Value;
}
}
As all numbers are treated as doubles, the result will be a double as well. The result can be retrieved through the CalculatedResult property, but only once the calculation has been performed - thus we check whether the result is null or not.
While traversing the AST to perform the calculations we maintain state through the use of a generic stack of doubles.
publicoverridevoidOutStart(Start node)
{
if (stack.Count != 1)
thrownew Exception("Stack should contain only one element at end.");
result = stack.Pop();
}
When starting out the stack will be empty. Once we’ve traversed the tree the stack should only contain a single element - the result. To ensure there’s no errors we make sure the stack only contains a single element, after which we return it by popping it from the stack.
publicoverridevoidInANumberExp(ANumberExp node)
{
stack.Push(Convert.ToDouble(node.GetNumber().Text.Trim(), new CultureInfo("en-us")));
}
Probably the most important unary operator is the constant number. Whenever we’re in a ANumberExp node we read in the number and push it onto the stack.
The other unary operators follow the same pattern. We pop the stack and perform a math operation on the popped value, after which we push the result back onto the stack.
The associative operators are simple in that they have no requirements as to which order the input parameters are in. As such, a multiplication simple pops two numbers from the stack and push the multiplied result back onto the stack.
The non associative opreators need to first pop one number and store it in a temporary variable. The reason we need to do this is that we’re working with a FIFO stack, meaning the second number will not be the topmost on the stack and thus we can’t perform the calculation in a single expression.
Now that we’ve made the AstCalculator class we just need to modify the main method so it runs the calculator.
// Print tree
AstPrinter printer = new AstPrinter();
ast.Apply(printer);
// Calculate expression
AstCalculator calculator = new AstCalculator();
ast.Apply(calculator);
Console.WriteLine("Calculation result: " + calculator.CalculatedResult);
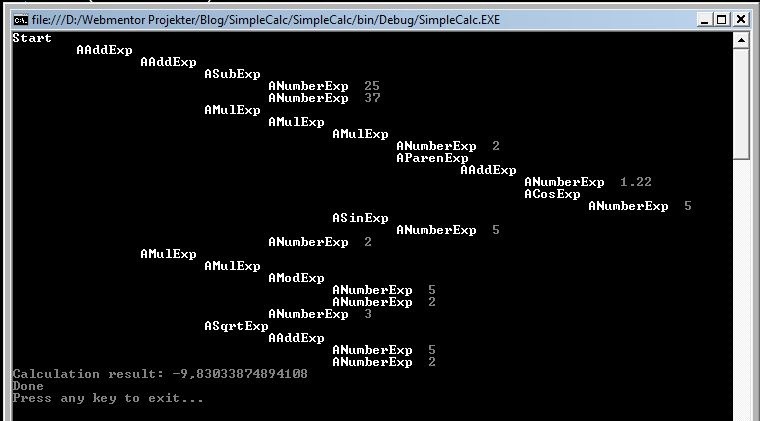
Simply instantiate a new AstCalculator after printing the AST, and then apply it to the AST. If you make the above modification and run the program, you should see an output similar to this:
Lo and behold, the result is identical to the one provided by Google originally!
Wrapping up
I’ve now shown how we can define a language grammar in SableCC and have it auto generate a parser for us. Using the SableCC parser we can read an input string and transform it into an abstract syntax tree. Once we have the abstract syntax tree, we can easily traverse it and modify it.
While SableCC originally was only able to generate Java output, we now have multiple options for the output language. Unfortunately the generated C# classes are not partial - a feature that would’ve been very useful once we start doing more advanced stuff with the AST. It’s rather easy to modify the six source files manually, as well as setting up an automated script to do it for us.
Once we read the input and transformed it into an AST we used stack based approach to traverse it and calculate sub results in a very simple way, emulating how most higher level languages work internally.
I’ll be following up on this post later on by extending the grammar and interpreter functionality.
A single server has started to sometime leave zombie w3wp.exe processes when trying to recycle. A new process is spawned properly and everything seems to work, except the old processes are still present and take up memory. Task manager reports there’s only a single thread left, far from the active ones that have between 40 and 70 threads usually. Using ProcDump I’ve taken a full memory dump to analyze further in WinDbg. The machine is a Server 2008 R2 x64 8 core machine as stated by WinDbg:
Windows 7Version7600 MP (8 procs) Free x64
After loading sos a printout of the managed threads reveals the following:
0:000> !threads
ThreadCount: 19
UnstartedThread: 0
BackgroundThread: 19
PendingThread: 0
DeadThread: 0
Hosted Runtime: no
PreEmptive Lock
ID OSID ThreadOBJ State GC GC Alloc Context Domain Count APT Exception
XXXX 19d0 000000000209b4c0 8220Enabled0000000000000000:0000000000000000000000000208e7700 Ukn
XXXX 2 c60 00000000020c3130 b220 Enabled000000013fbe5ed0:000000013fbe7da8 000000000208e7700 MTA (Finalizer)
XXXX 3 a24 00000000020f0d60 880a220 Enabled0000000000000000:0000000000000000000000000208e7700 MTA (Threadpool Completion Port)
XXXX 497c 000000000210518080a220 Enabled0000000000000000:0000000000000000000000000208e7700 MTA (Threadpool Completion Port)
XXXX 5 c28 000000000210bfe0 1220Enabled0000000000000000:0000000000000000000000000208e7700 Ukn
XXXX 6 d40 00000000053f9080 180b220 Enabled00000001bfe75d20:00000001bfe767c8 000000000208e7700 MTA (Threadpool Worker)
XXXX 7 c18 00000000053f9b30 180b220 Enabled00000000fff95880:00000000fff97210 000000000208e7700 MTA (Threadpool Worker)
XXXX 8 f7c 00000000053fa5e0 180b220 Enabled000000011fbea268:000000011fbea920 000000000208e7700 MTA (Threadpool Worker)
XXXX 991c 00000000053fb090 180b220 Enabled00000001dfc39138:00000001dfc39670 000000000208e7700 MTA (Threadpool Worker)
XXXX a fb0 00000000053fbd20 180b220 Enabled00000000fff922b0:00000000fff93210 000000000208e7700 MTA (Threadpool Worker)
XXXX b fc8 00000000053fc9b0 180b220 Enabled0000000160053ea0:0000000160054778000000000208e7700 MTA (Threadpool Worker)
XXXX c 53800000000053fd460 180b220 Enabled000000017fd8fc98:000000017fd911f8 000000000208e7700 MTA (Threadpool Worker)
XXXX d 60400000000053fdf10 180b220 Enabled000000019fd7aa78:000000019fd7c648 000000000208e7700 MTA (Threadpool Worker)
0 f 2cc 0000000005514c60 220Enabled0000000000000000:0000000000000000000000000208e7700 Ukn
XXXX 109bc 00000000020a90c0 220Enabled0000000000000000:0000000000000000000000000208e7700 Ukn
XXXX 119c0 00000000056b7a00 220Enabled0000000000000000:0000000000000000000000000208e7700 Ukn
XXXX e 9d4 00000000056b7fd0 220Enabled0000000000000000:0000000000000000000000000208e7700 Ukn
XXXX 129d8 00000000056b85a0 220Enabled0000000000000000:0000000000000000000000000208e7700 Ukn
XXXX 13 cb8 00000000056b8b70 220Enabled0000000000000000:0000000000000000000000000208e7700 Ukn
Of more interest however is probably the output of a stack backtrace for the single unmanaged thread remaining:
From the stack trace it’s obvious that the w3wp process is trying to shut down and perform its cleanup tasks, but for some reason ntdll!ZwClose is hanging up. It’s been hung for several days without change - and without apparent side effects besides an increased amount of memory usage.
The w3wp processes do not hang up all the time, I have yet to find a reproducible pattern. In the meantime, any suggestions for further debugging?
I recently put a number of load balanced websites in production by using the newly released IIS7 Application Request Routing v2 Beta extension. Everything seemed to run perfectly both performance and functionality wise. There was a slight problem however.
Some users were reporting mysterious errors when uploading files to the website, apparently seeming like a timeout. When I tried to reproduce, all smallish files when through, though larger files did fail. I checked out the responses in Fiddler and to my surprise the ones working returned 200 while the failing ones returned a 404 error after a while. To the trained eye, the problem might already be apparent - unfortunately it wasn’t apparent to me at the time. I’d expect a status 200 for working uploads and a 500 for failed uploads. A 404 should only happen when the URL is wrong, which certainly shouldn’t vary depending on file size.
Circumventing the ARR load balancing server fixed the issue, so I quickly pinpointed that the addition of the ARR load balancer was the root cause. Enabling IIS logging on the content servers revealed that the failing requests never reached the content servers, hinting that the actual problem occurred on the ARR machine before even being proxied on to the content servers.
Checking out the IIS log of the ARR server revealed the following crucial line (unimportant parts abbreviated):
[DATETIME] [USER_IP] GET / - 80 - [USER_IP] [UserAgent] 4041301
The HTTP status code is 404 as shown by Fiddler. The interesting part however is the HTTP substatus code of 13. Checking up on the HTTP substatus codes utilized by the IIS7 Request Filtering module revals that 404.13 is caused by a too large content length. If the ARR IIS had spat out a detailed IIS error page instead of a generic 404, the problem would have been apparent much quicker since the substatus code would’ve been included. Unfortunately the detailed errors are disabled on the ARR ISS for security reasons.
The solution is simple. By opening the C:WindowsSystem32inetsrvconfigapplicationHost.config (the main IIS configuration file) and setting the maxAllowedContentLength in system.webServer/security/requestFiltering/requestLimits to a higher value, we automatically allow larger bodies for incoming requests and thus avoiding the 404.13 error caused by the request filtering module. In the below example I’ve set the limit to 256 MB - the value is expressed in bytes.
Tip: Instead of editing the applicationHost.config file manually you can also install the IIS Admin Pack Tech Preview 2 which will give you the option to edit request filtering settings directly from the IIS Manager, as well as a number of other management GUI improvements.
Whenever you concatenate multiple strings into a path, you really ought to be using the System.IO.Path class’s Combine method. At times you may be concatenating a number of smaller parts of a path instead of just the two that the Path.Combine() method takes. Nested Path.Combine calls quickly become difficult to read and error prone:
Often we won’t have all of our path parts in named variables, and even when we do, they’ll rarely be named partOne, partTwo, partX etc. If we mix literal strings with variables and multiple levels of nested Path.Combine calls, mayhem will arise.
As an alternative I’m using a simple wrapper method above the Path.Combine method:
The C# params.aspx) keyword allows us to make a method take in any number of parameters of the same type - string in this case. Note that I’ve split the paths up into three parts - path1, path2 and pathn. If we were to only take the params string[] parameter, the user might send in no parameters at all - which wouldn’t make sense. By forcing the user to send in at least two paths, we maintain the interface of Path.Combine and just add extra functionality on top of it - though the user may still just send in two paths as before.
An extension method you say? The logical place to put this function would be in the Path class itself, perhaps named CombineMultiple. Unfortunately the Path class is static so we’re unable to extend it. Another option might be directly on string as a CombinePath method like this:
While this does work, I really don’t recommend it. I’m against overly use of extension methods unless there’s a good reason. I think it’s much cleaner to contain this code in a separate class whose only purpose is path combining. Now devs are going to be confused when they sometimes see the CombinePath method in Intellisense and not at other times, depending on whether the namespace has been imported. Also, I think the PathCombiner.Combine syntax is the cleanest on top of that, but you be the judge:
Logging is an integral part of most applications, whether it’s for logging performance metrics or causality data. Avoiding performance hits due to logging can be tricky though as we don’t want to spend CPU cycles on the logging infrastructure when logging is disabled, while still keeping the full logging ability when required.
Imagine the following scenario in which we want to log an exception in our application:
Logger.Log("An error occured at " + DateTime.Now + " on computer " + Environment.MachineName + " in process" + Process.GetCurrentProcess().ProcessName + ".");
Inside the Logger.Log method we may have a check for whether logging is enabled like the following:
What’s the problem? Although we do not touch the file system when logging is disabled, we still incur the rather large overhead of string concatenation and retrieving the machine and process name. Usually this overhead will be even larger depending on what extra information is logged as part of the actual log message. Yes, we could append the machine and process names within the Logger.Log method, but that’s beyond the problem I’m describing.
We can avoid this by checking for LoggingEnabled in our actual application code:
if(Logger.LoggingEnabled)
Logger.Log("An error occured at " + DateTime.Now + " on computer " + Environment.MachineName + " in process" + Process.GetCurrentProcess().ProcessName + ".");
While this does save us from doing string concatenation and retrieving other data when logging is disabled, it’s rather ugly to have logging checks scattered around the application code.
An alternative to sending a log message directly to the Logger.Log method would be to send a Func that fetches the log message if needed:
Logger.Log(() => "An error occured at " + DateTime.Now + " on computer " + Environment.MachineName + " in process" + Process.GetCurrentProcess().ProcessName + ".");
This has the big benefit of only executing the actual logging message functionality if logging is enabled, thus reducing the overhead to a near zero.
While this is rather straight forward as long as the logging is performed synchrounously, there’s a pitfall if we perform asynchronous logging. Take the following asynchronous Logger implementation as an example:
Instead of outputting the log message to the log file immediately when the Log function is called, we now store the actual log messages in a FIFO) queue. At some point we’ll call Logger.FlushMessages to flush out the messages to the text file. To optimize the process we’d usually concatenate the messages in a StringBuilder and perform just a single sequential write to disk, but to KISS I’m just writing out the messages one by one.
We’ll perform a number of logs using the following code:
string date = DateTime.Now.ToString();
Logger.Log("An error occured at " + DateTime.Now + " (" + date + ") on computer " + Environment.MachineName + " in process" + Process.GetCurrentProcess().ProcessName + ".");
If you open the log file, you’ll notice a discrepancy between the two dates that are logged, while you might expect them to be identical. As the actual lambda function is performed at log flush time instead of log time, the DateTime.Now variable will include the flush moment instead of the original logging moment.
The solution in this case is simple. All we need to do is to store the results of the log Funcs instead of the actual funcs:
We can still implement asynchronous logging, as long as the actual log message is retrieved synchronously or we make sure the logging Func only references local immutable variables - though the last case kinda destroys the performance gain.
string date = DateTime.Now.ToString();
Logger.Log(() => "An error occured at " + date + " on computer " + Environment.MachineName + " in process" + Process.GetCurrentProcess().ProcessName + ".");
To sum up the speed gains of using deferrered lambda logging, I’ve implemented a simple synchronous Logger implementation:
As we can see from the results, even with logging disabled it still costs us 763ms using the normal logging procedure. By deferring the execution of the log message we only incur an overhead of 0,65ms when logging is disabled. When logging is enabled the execution costs are ~identical.
Once you start distributing your ASP.NET website across multiple webservers, you’re going to need a way to share session state. That is, unless your app is stateless, in which case scaling it should be a breeze!
One of the easiest ways to provide common session state for a small cluster (very dependant on load and hardware specs, but ~10 servers max, per state server), is to use the built-in ASP.NET State Service. It’s a free service that’s installed alongside the .NET Framework on all Windows servers.
While the InProc session storage is stored directly in the w3wp process, the ASP.NET State Service is an independant process that runs alongside your IIS w3wp processes. The State Service does not have to run on a machine with IIS installed - it can run on a machine dedicated to serving session state for other web servers running IIS.
Performance
Switching from InProc to State Service will have an impact on performance. We now have to cross not only process boundaries, but also machine boundaries. Furthermore, once we go out-of-process, all objects will have to be serialized, requiring extra work and requires all objects to be marked with the [Serializable] attribute.
The State Service performance is heavily reliant on memory. Once physical memory has been exhausted it’ll start paging to disk which will kill performance quickly. Make sure to monitor the memory load on your State Service machine(s) and adjust memory accordingly.
Enabling remote connectivity
By default, the State Service will only allow local-to-machine connections. To allow remote connections you’ll have to set the HKLM\SYSTEM\CurrentControlSet\Services\aspnet_state\Parameters\AllowRemoteConnection key to a value of ‘1’. After changing the AllowRemoveConnection key value, you’ll have to restart the State Service service for the change to take effect. Also make sure your firewall allows connectivity to the State Service port (TCP 42424 by default).
Requirements
All session objects must be serializable.
All IIS websites that are to share session state must have a common IIS application path (the ID column in the sites list). I strongly recommend you look into the IIS7 Shared Configuration feature as it’ll help you keep all the web servers IIS7 configuration in synch, including the application path.
All websites that are to share session state must have the same values so they’re able to read one anothers sessions. You can generate the keys online.
Scalability
If you start saturating your dedicated State Service machine, it’s possible to implement session state partitioning by implementing theSystem.Web.IPartitionResolver interface. By creating your own implementating, you can route new requests to different state servers and perhaps even check whether the state servers are available or not, to add redundancy. Note however that this will not give you redundancy in case the State Service crashes either due to software or hardware.
I’m finally sitting in the train on my way home from the Airport and an excellent week spent in Nashville, also known as Nash Vegas.
First of all, major kudos go out to John Kellar (@johnkellar) and the rest of the devLINK team. I still can’t believe the amazing quality of devLINK as a conference, the speaker lineup, food, party, etc, all for a price of just $75! From what I gathered, there were only three international participants at devLINK this year, including me and @KasperVesth - if devLINK continues its current path, I’m sure there’ll be plenty more next year.
Also thanks to Elijah Manor for giving me and @KasperVesth a ride home from Lipscomb - cabs are nowhere to be found out there! Likewise, thanks to John Doe (sorry, can’t remember your name!) from who we hitched a ride back to the Sheraton from Lipscomb after having walked a mile down the road and realized cabs weren’t around.
Besides having to reboot my laptop at the last minute due to my virtual machines not recognizing my network, I think the presentation went quite well. Not as many people as I’d hoped for, but I guess having the last slot with a narrow topic is a challenge in that regard.
You can download my code, slides and videos here. I’ve not included the virtual PCs since they’d take up around 40GB to download.
I hope I’ll be able to join you again next year, providing the economy & work schedule allows it :)
Gaines Kergosien in his chainmail at the Community Leadership Summit the day before devLINK.
The outdoor eating area.
I’ve never seen this high a concentration of guitars at any conference!
The main entrance at Lipscomb University - perfect venue for the event. Could’ve used more cabs in the vicinity however.
Hands down the best conference party I’ve attended. Free buffet at the local Nashville Sounds baseball game. Awesome.
When adding sites to IIS7 either by script or by editing the config files directly, you may receive an error in the sites list that says:
Unknown: The object identifier does not represent a valid object. (Exception from HRESULT: 0x800710D8)
I’m running multiple servers in an NLB setup, using the shared configuration feature of IIS7 (config files are stored on a SAN exposed through a CIFS share). My first thoughts were that this was probably related to the shared configuration / network access, but I’m able to reproduce the problem even with location configuration. An interesting observation is that all IIS’s on all servers using the shared config will display the same errors on the same sites.
Restarting the sites, app pool or even IIS does not help on the issue, neither does restarting the IIS Manager itself. I have not tried restarting the servers, and I’m not going to.
The only relevant info I could find on Google was this thread on forums.iis.net. Besides various mutations of the restart option, the thread mentions it might be a permissions issue. I’m running IIS Manager under an administrative account and all application pools run under processes with access to the configuration directory. Running Process Monitor confirms that there are no permission issues.
What I’ve found since then is that a simple file tocuh will fix the problem. That is, if I open the file in notepad and make/undo a change and save the file, all IIS’s will reload the configuration and all sites will have loaded correctly on all servers. Using Process Monitor I’ve verified that change notifications are being sent out to all servers, thereby notifying them of an update to the configuration, causing the reload in IIS. The aforementioned thread does note that IIS will basically start a timer with an interval of a few ms before it’ll update the site list of a config change - if reading the config file takes longer than this timeout, we may be in trouble. However, this issue should be fixed by a refresh and most certainly by a restart of the IIS. Also, since this is happening on all servers, it would seem weird that they all exceed the timeout.
To add confusion, this bug is temporal. If I add three sites programmaticaly (three transactions - they’re not committed all at once, but in succession) using code like this:
using (ServerManager mgr = new ServerManager())
{
if (mgr.Sites[name] != null)
mgr.Sites.Remove(mgr.Sites[name]);
// Create site
Site site = mgr.Sites.Add(name, "http", "*:80:" + domain, physicalPath);
// Set app poolforeach (var app in site.Applications)
app.ApplicationPoolName = pool;
// Add extra bindingsforeach (string hostname in extraBindings)
site.Bindings.Add("*:80:" + hostname, "http");
mgr.CommitChanges();
}
Sometimes all sites work, sometimes 1-3 of them don’t. Usually two of them will have failed while one will be working. Running the exact code again will fix the problem. The code is made so it’ll just recreate a website if it already exists and thus running the code again will basically just touch the file, causing reloads of the config files across the servers. If I try to access the sites programmatically, I’ll receive the same exception as is displayed in the IIS Manager and as a result I might actually be able to detect this issue and just keep retrying until all sites work.
As an alternative, I’ve also tried just generating the complete applicationHost.config file from scratch so that all changes are definitely made at the same time. By creating the applicationHost.config file separately and then replacing the old one, I don’t get the “valid object” error any more. However, a random number of websites & pools will be in the “stopped” state for no apparent reason. All sites & pools have the auto start attributes set to true. I can start the sites manully without problems, it’s not a good solution though seeing as there’s hundreds of sites and it’ll take a considerably amount of time to start half of them manually. Fortunately that part is easy to script:
using (ServerManager mgr = new ServerManager())
{
// Start all app poolsforeach (var pool in mgr.ApplicationPools)
pool.Start();
log("Pools started - Done");
// Start all sitesforeach (var site in mgr.Sites)
site.Start();
log("Sites started - Done");
}
Anyone else experiencing this issue and have found the cause? Or do you have a better workaround than what I’m doing?