One of the latest features I’ve added to OrcaMDF is support of databases with multiple data files. This required relatively little parsing changes, actually it was mostly bug fixing code that wasn’t hit previously, due to only working with single file databases. It did however require some major refactoring to move away from MdfFile being the primary entrypoint, to now using the Database class, encapsulating a variable number of DataFiles.
Proportional fill allocation
OrcaMDF supports the standard proportional fill allocation scheme where a table is created in the database, being bound to the default PRIMARY filegroup containing all the data files. As an example, you might create the following database & schema:
CREATE DATABASE
[SampleDatabase]
ON PRIMARY
(
NAME = N'SampleDatabase_Data1',
FILENAME = N'C:SampleDatabase_Data1.mdf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
),
(
NAME = N'SampleDatabase_Data2',
FILENAME = N'C:SampleDatabase_Data2.ndf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
),
(
NAME = N'SampleDatabase_Data3',
FILENAME = N'C:SampleDatabase_Data3.ndf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N'SampleDatabase_log',
FILENAME = N'C:SampleDatabase_log.ldf',
SIZE = 3072KB,
FILEGROWTH = 10%
)
GO
USE SampleDatabase
GO
CREATE TABLE MyTable
(
A int identity,
B uniqueidentifier default(newid()),
C char(6000)
)
GO
INSERT INTO MyTable DEFAULT VALUES
GO 100
This would cause MyTable to be proportionally allocated between the three data files (the C column being used for the fill to require 100 pages of storage – to ensure we hit all three data files). And to parse it, all you’d do is the following:
var files = new[]
{
@"C:SampleDatabase_Data1.mdf",
@"C:SampleDatabase_Data2.ndf",
@"C:SampleDatabase_Data3.ndf"
};
using (var db = new Database(files))
{
var scanner = new DataScanner(db);
var result = scanner.ScanTable("MyTable");
EntityPrinter.Print(result);
}
And when run, you’ll see this:
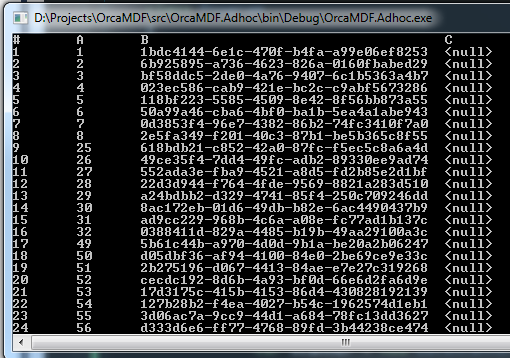
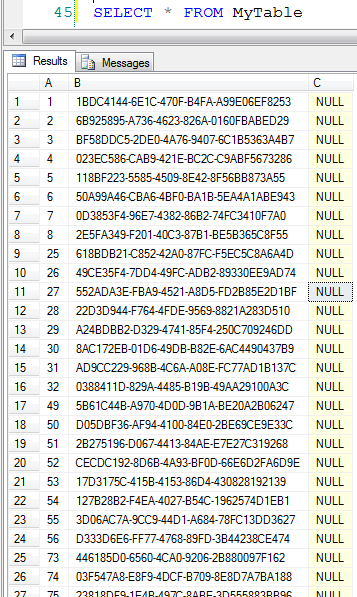
All the way down to 100. Notice how the A column identity value is jumping – this is due to the fact that we’re allocating one extent per data file in round robin fashion. ID’s 1-8 in the first data file, 9-16 in the second data file and finally 17-24 in the third data file. At this point pages 25-32 are allocated in the first data file again, and so on. Since it’s a heap, we’re scanning these in allocation order – by file. That causes us to get results 1-8, 25-32, 49-56, 73-80 and finally 97-100 all from the first file first, and then 9-16, 33-40, etc. from the second and finally the remaining pages from the third data file. Think that looks weird? Well, it’s exactly the same for SQL Server:
Filegroup support
OrcaMDF also supports the use of filegroups, including proportional fill allocation within a specific filegroup. As an example, you might create the following database & schema:
CREATE DATABASE
[SampleDatabase]
ON PRIMARY
(
NAME = N'SampleDatabase_Data1',
FILENAME = N'C:SampleDatabase_Data1.mdf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
LOG ON
(
NAME = N'SampleDatabase_log',
FILENAME = N'C:SampleDatabase_log.ldf',
SIZE = 3072KB,
FILEGROWTH = 10%
)
GO
ALTER DATABASE
[SampleDatabase]
ADD FILEGROUP
[SecondFilegroup]
GO
ALTER DATABASE
[SampleDatabase]
ADD FILE
(
NAME = N'SampleDatabase_Data2',
FILENAME = N'C:SampleDatabase_Data2.ndf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
),
(
NAME = N'SampleDatabase_Data3',
FILENAME = N'C:SampleDatabase_Data3.ndf',
SIZE = 3072KB,
FILEGROWTH = 1024KB
)
TO FILEGROUP
[SecondFilegroup]
GO
USE SampleDatabase
GO
CREATE TABLE MyTable
(
A float default(rand()),
B datetime default(getdate()),
C uniqueidentifier default(newid()),
D char(5000)
) ON [SecondFilegroup]
GO
INSERT INTO MyTable DEFAULT VALUES
GO 100
This would cause MyTable to be proportionally allocated in the second and third datafile (the D column being used for fill to require 100 pages of storage – to ensure we hit both data files in the filegroup), while the primary data file is left untouched. To parse it, you’d do the exact same as in the previous example, and the result would be:
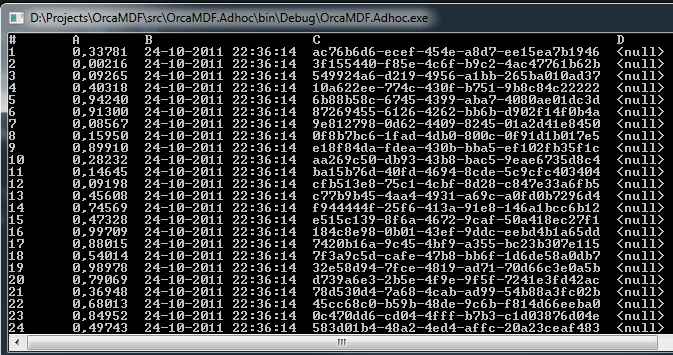
… All the way down to 100.