When I initially started working on OrcaMDF I had just one goal, to gain a deeper knowledge of MDF file internals than I could through most books available.
As time progressed, so did OrcaMDF. While I had no initial plans of doing so, OrcaMDF has ended up being capable of parsing base tables, metadata and even dynamically recreating common DMVs. On top of this, I made a simple GUI, just to make OrcaMDF easier to use.
While that’s great, it comes at the price of extreme complexity. To be able to automatically parse table metadata like schemas, partitions, allocation units and more, not to mention abstracting away details like heaps and indexes, it takes a lot of code and it requires intimate knowledge of the database itself. Seeing as metadata changes between versions, OrcaMDF currently only supports SQL Server 2008 R2. While the data structures themselves are rather stable, there are minor differences in the way metadata is stored, the data exposed by DMVs and so forth. And on top of this, requiring all of the metadata to be perfect, for OrcaMDF to work, results in OrcaMDF being just as vulnerable to corruption as SQL Server is itself. Got a corrupt boot page? Neither SQL Server nor OrcaMDF will be able to parse the database.
Say Hello to RawDatabase
I tried to imagine the future of OrcaMDF and how to make it the most useful. I could march on make it support more and more of the same features that SQL Server does, eventually being able to parse 100% of an MDF file. But what would the value be? Sure, it would be a great learning opportunity, but the thing is, if you’ve got a working database, SQL Server does a pretty good job too. So what’s the alternative?
RawDatabase, in contrast to the Database class, doesn’t try to parse anything besides what you tell it to. There’s no automatic parsing of schemas. It doesn’t know about base tables. It doesn’t know about DMVs. It does however know about the SQL Server data structures and it gives you an interface for working with the MDF file directly. Letting RawDatabase parse nothing but the data structures means it’s significantly less vulnerable to corruption or bad data.
Examples
It’s still early in the development, but let me show some examples of what can be done using RawDatabase. While I’m running the code in LINQPad, as that makes it easy to show the results, the result are just standard .NET objects. All examples are run against the AdventureWorks 2008R2 LT (Light Weight) database.
Getting a Single Page
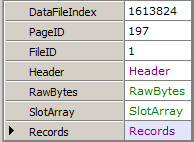
In the most basic example, we’ll parse just a single page.
// Get page 197 in file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.GetPage(1, 197).Dump();
Parsing the Page Header
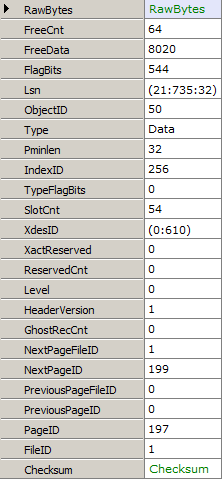
Now that we’ve got a page, how about we dump the header values?
// Get the header of page 197 in file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.GetPage(1, 197).Header.Dump();
Parsing the Slot Array
Just as the header is available, you can also get the raw slot array entries.
// Get the slot array entries of page 197 in file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.GetPage(1, 197).SlotArray.Dump();

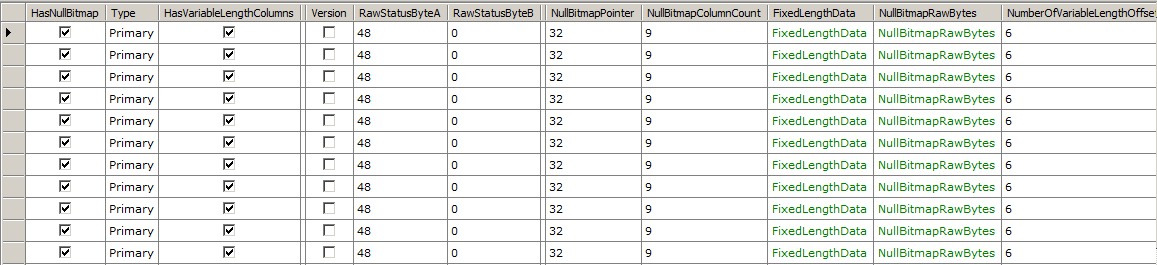
Parsing Records
While getting the raw slot array entries can be useful, you’ll usually want to look at the records themselves. Fortunately, that’s easy to do too.
// Get all records on page 197 in file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.GetPage(1, 197).Records.Dump();
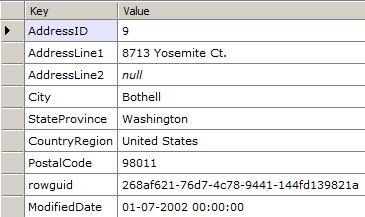
Retrieving Data from Records
Once you’ve got the records, you could now access the FixedLengthData or the VariableLengthOffsetValues properties to get the raw fixed length and variable length column values. However, what you’ll typically want is to get the actually parsed values. To spare you the work, OrcaMDF can parse it for you, if you just provide it the schema.
// Read the record contents of the first record on page 197 of file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
RawPrimaryRecord firstRecord = (RawPrimaryRecord)db.GetPage(1, 197).Records.First();
var values = RawColumnParser.Parse(firstRecord, new IRawType[] {
RawType.Int("AddressID"),
RawType.NVarchar("AddressLine1"),
RawType.NVarchar("AddressLine2"),
RawType.NVarchar("City"),
RawType.NVarchar("StateProvince"),
RawType.NVarchar("CountryRegion"),
RawType.NVarchar("PostalCode"),
RawType.UniqueIdentifier("rowguid"),
RawType.DateTime("ModifiedDate")
});
values.Dump();
RawColumnParser.Parse will, given a schema, automatically convert the raw bytes into a Dictionary<string, object>, the key being the column name from the schema and the value being the actual type of the column, e.g. int, short, Guid, string, etc. By letting you, the user, specify the schema, OrcaMDF can get rid of a slew of dependencies on metadata, thus ignoring any possible corruption in metadata. Given the availability of the Next & PreviousPageID properties of the header, it would be simple to iterate through all linked pages, parsing all records of each page - basically performing a scan on a given allocation unit.
Filtering Pages
Besides retrieving a specific page, RawDatabase also has a Pages property that enumerates over all pages in a database. Using this you could, for example, get a list of all IAM pages in the database.
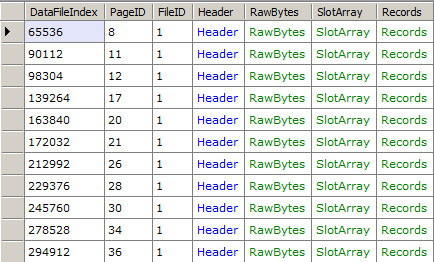
// Get a list of all IAM pages in the database
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.Pages
.Where(x => x.Header.Type == PageType.IAM)
.Dump();
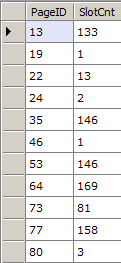
And since this is powered by LINQ, it’s easy to project just the properties you want. For example, you could get all index pages and their slot counts like this:
// Get all index pages and their slot counts
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.Pages
.Where(x => x.Header.Type == PageType.Index)
.Select(x => new {
x.PageID,
x.Header.SlotCnt
}).Dump();
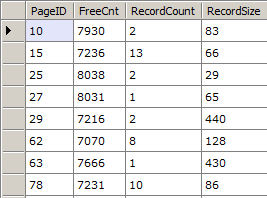
Or let’s say you wanted to get all data pages with at least one record and more than 7000 bytes of free space - with the page id, free count, record count and average record size as the output:
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.Pages
.Where(x => x.Header.FreeCnt > 7000)
.Where(x => x.Header.SlotCnt >= 1)
.Where(x => x.Header.Type == PageType.Data)
.Select(x => new {
x.PageID,
x.Header.FreeCnt,
RecordCount = x.Records.Count(),
RecordSize = (8096 - x.Header.FreeCnt) / x.Records.Count()
}).Dump();
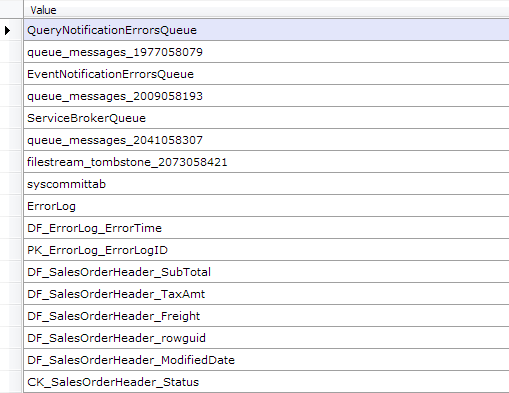
And as a final example, imagine you’ve got just an MDF file but you seem to have forgotten what objects are stored inside of it. Fret not, we’ll just get the data from the sysschobjs base table! Sysschobjs is the base table that stores all object data, and fortunately it has a static object ID of 34. Using this, we can filter down to all of the data pages for object 34, get all the records and then parse just the two first columns of the schema (you may specify a partial schema, as long as you only omit columns at the end), ending up in us dumping just the names (we could of course have gotten the full schema, if we wanted to).
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
var records = db.Pages
.Where(x => x.Header.ObjectID == 34 && x.Header.Type == PageType.Data)
.SelectMany(x => x.Records);
var rows = records.Select(x => RawColumnParser.Parse((RawPrimaryRecord)x, new IRawType[] {
RawType.Int("id"),
RawType.NVarchar("name")
}));
rows.Select(x => x["name"]).Dump();
Compatibility
Seeing as RawDatabase doesn’t rely on metadata, it’s much easier to support multiple SQL Server versions. Thus, I’m happy to say that RawDatabase fully supports SQL Server 2005, 2008, 2008R2 and 2012. It probably supports 2014 too, I just haven’t tested that. Speaking of testing, all unit tests are automatically run against AdventureWorksLT for both 2005, 2008, 2008R2 and 2012 during testing. Right now there are tests demonstrating that OrcaMDF RawDatabase is able to parse the first record of each and every table in the AdventureWorks LT databases.
Corruption
One of the really interesting use cases for RawDatabase is in the case of corrupted databases. You could filter pages on the object id you’re searching for and then brute-force parse each of them, retrieving whatever data is readable. If metadata is corrupted, you could ignore it, provide the schema manually and the just follow the linked lists of pages, or parse the IAM pages to read heaps. During the next couple of weeks I’ll be blogging more on OrcaMDF RawDatabase to show various use case examples, including ones on corruption.
Source & Feedback
I’m really excited about the new RawDatabase addition to OrcaMDF and I hope I’m not the only one who can see the potential. If you try it out, have any ideas, suggestions or other kinds of feedback, I’d love to hear it.
If you want to try it out, head on over to the OrcaMDF project on GitHub. Once it’s just a bit more polished, I’ll make it available on NuGet as well. Just like the rest of OrcaMDF, the code is licensed under GPL v3.