I recently stumbled upon a question on Stack Overflow on how best to reduce their data size as it’s growing out of hand. As the original author hasn’t replied back yet (as of writing this post, I’m making some assumptions on the scenario – so take it as an abstract scenario). The basic scenario is that they have a number of measuring stations, each one of those containing a lot of equipment reporting back to a SQL Server in a schema like the following abstract:
CREATETABLE Measurements
(
DataID bigint IDENTITY,
StationID int,
MeasurementA real,
MeasurementB real,
MeasurementC real
... 100 more columns
)
They’re willing to loose some precision of the data, for the purpose of saving space. As some of the data is measuring wind speed in meters/sec and air pressure, I’m making the assumptions that most of the data will be in the 0-200 and 500-2000 ranges, depending on the scale used.
If the wind speed does not need accuracy further than two decimals, storing it in a 4 byte real column is a lot of waste. Instead we might store it in a smallint column, saving 2 bytes per column. The data would be converted like so:
35.7 => 35.7 * 100 = 3,570
1.38 => 1.38 * 100 = 138
155.29 => 155.29 * 100 = 15,529
84.439 => 84.439 * 100 = 8,443 (with the .9 being rounded off due to integer math)
So by multiplying all the values by 100, we achieve a precision of two decimal points, with all further decimal points being cropped. As the smallint max value is 32,767, the maximum value we could store in this format would be:
327.67 => 327.67 * 100 = 32,767
Which is probably enough for most wind measurements. Hopefully.
For the larger values in the 500-2000 ranges, we can employ the same technique by multiplying by 10. This only gives us a single digit of precision, but allows for values in the –3,276.8 to 3,276.7 range, stored using just 2 bytes per column. Employing the same technique we could also store values between 0 and 2.55 in a single byte tinyint column, with a precision of two digits.
Unless you really need to save those bytes, I wouldn’t recommend you do this as it’s usually better to store the full precision. However, this does show that we can store decimals in integer data types with a bit of math involved.
Continuing my review of my old database designs, I stumbled upon yet another mind numbing design decision. Back then, I’d just recently learned about the whole page split problem and how you should always use sequentially valued clustered keys.
This specific table needed to track a number of views for a given entity, storing a reference to the entity and the time of the view. As I knew page splits where bad, I added a clustered index key like so:
With a schema like this, insertions won’t cause fragmentation as they’ll follow the nice & sequential ViewID identity value. However, I did realize that all of my queries would be using EntityID and Created as a predicate, reading most, if not all, of the columns. By clustering on ViewID, I’d have to scan the entire table for all queries. As that obviously wouldn’t be efficient, I added a nonclustered index:
CREATE NONCLUSTERED INDEX IDX_EntityID_Created ON EntityViews (EntityID, Created) INCLUDE (OtherData)
If you’re shaking your head by now, good. This index solved my querying issue as I could now properly seek my data using (WHERE EntityID = x AND Created BETWEEN y AND z) predicates. However, the nonclustered index contains all of my columns, including ViewID as that’s the referenced clustered key. And thus I’m storing all my data twice! My clustered index is neatly avoiding fragmentation, but my nonclustered index (that contains all the same data!) is experiencing the exact fragmentation issues that I originally wanted to avoid!
Realizing this fact, the correct schema would’ve been:
CREATETABLE EntityViews
(
EntityID intNOTNULL,
Created datetime NOTNULL,
OtherData char(20)
)
CREATE CLUSTERED INDEX CX_EntityID_Created ON EntityViews (EntityID, Created)
We save the surrogate key value bytes for each row and all the data is stored only once. There’s no need for secondary indexes as all the data is stored in the natural querying order. However, page splitting will occur as EntityID won’t be sequential. This is easily avoided by scheduling REINDEX & REUBILD as appropriate.
Furthermore, as the clustered key is sorted on Created secondarily, older non-fragmented data won’t be affected – it’ll only affect the most recently added pages, which are probably in memory anyways and thus won’t cause problems for querying.
Inspired by this question on StackOverflow, I’ve made a quick script to demonstrate how this might be done using OrcaMDF.
In this example I’m looping all .mdf files in my local SQL Server data directory. Each one is loaded using OrcaMDF, the boot page is fetched and finally the database name is printed:
using System;
using System.IO;
using OrcaMDF.Core.Engine;
namespace OrcaMDF.Adhoc
{
class Program
{
staticvoid Main()
{
foreach (string mdfPath in Directory.GetFiles(@"C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA"))
{
if (!mdfPath.ToLower().EndsWith(".mdf"))
continue;
using (var file = new MdfFile(mdfPath))
{
var bootPage = file.GetBootPage();
Console.WriteLine(bootPage.DatabaseName);
}
}
}
}
}
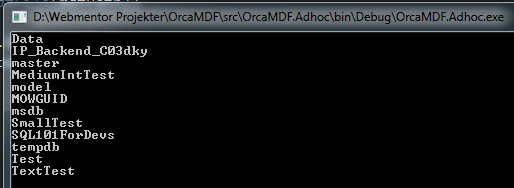
And the following is the output we get:
Which, coincidentally, matches up to the databases I’ve got attached to my local SQL Server. At this point we could match this list up to the one we’d get from sys.databases and see which files didn’t have a matching database, and thus weed out the non-attached mdf files from our data directory.
Being a proponent of carefully choosing your data types, I’ve often longed for the mediumint data type that MySQL has. Both smallint and int are signed data types, meaning their ranges are –32,768 to 32,767 for smallint and –2,147,483,648 to 2,147,483,647 for int. For most relational db schemas, positive identity values are used, meaning we’re looking at a possible 32,767 vs 2,147,483,647 values for smallint vs int. That’s a humongous difference, and it comes at a storage cost as well – 2 vs 4 bytes per column. If only there was something in between…
You say mediumint, I say binary(3)
While there’s no native mediumint data type in SQL Server, there is a binary data type. Internally it’s basically just a byte array, just as any other data type. An int is just a binary(4) with some custom processing on top of it, smallint being a binary(2) and nvarchar being a binary(length * 2). What that means is there’s no stopping us from saving whatever bytes we want into a binary(3) column, including numbers. Using the following sample table:
CREATETABLE ThreeByteInt
(
MediumInt binary(3),
Filler char(20) NULL
)
CREATE CLUSTERED INDEX CX_ThreeByteInt ON ThreeByteInt (MediumInt)
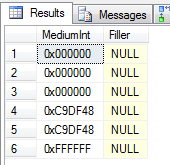
We can insert values through SQL either using byte constants or using numbers as normal:
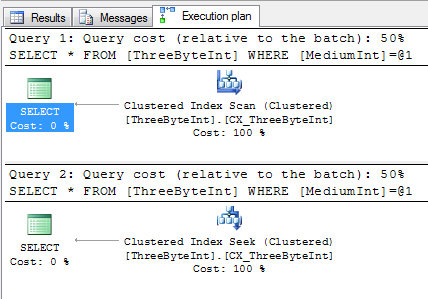
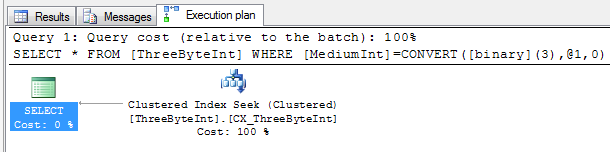
However, take a look at the plans for these two queries:
SELECT * FROM ThreeByteInt WHERE MediumInt = 1500SELECT * FROM ThreeByteInt WHERE MediumInt = 0x0005DC
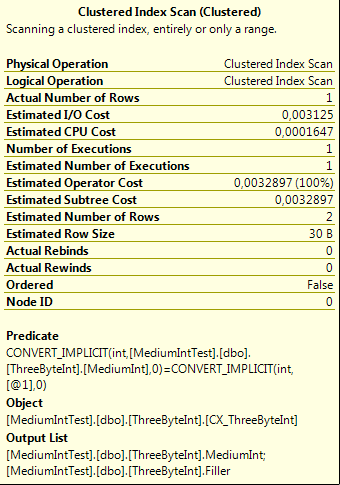
They both contain a predicate looking for a value of 1500, one written as an integer constant, the other as a hex constant. One is causing a scan, the other is using a seek. Taking a closer look at the scan reveals an IMPLICIT_CONVERT which renders are index useless and thus causing the scan:
The easiest way of avoiding this is just to replace the implicit conversion with an explicit cast in the query:
SELECT * FROM ThreeByteInt WHERE MediumInt = CAST(1500as binary(3))
Unsigned integers & overflow
Whereas smallint, int and bigint are all signed integer types (the ability to have negative values), tinyint is not. Tinyint is able to store values in the 0-255 range. Had it been a signed type, it would be able to handle values in the –128 to 127 range. Just like tinyint, binary(3)/mediumint is an unsigned type, giving us a range of 0 to 16,777,215.
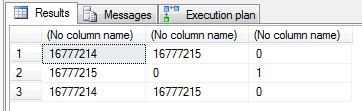
Most developers & DBAs have experienced integer overflow at some point, usually causing havoc in the application. In short, an overflow occurs when you assign a value larger or smaller than what the data type can handle. In our case, that might be –1 or 16,777,216. We can easily demonstrate what’s happening by casting an integer to binary(3) and back to int again like so:
Now that we’ve got our mediumint data type, all we need is to be able to insert & query data from the client.
Inserting is easy – just send values is as integers and it’ll be converted as appropriate – just make sure to check for over/underflows as necessary:
using(var conn = new SqlConnection("Data Source=.;Initial Catalog=MediumIntTest;Integrated Security=SSPI;"))
{
var insert = new SqlCommand("INSERT INTO ThreeByteInt (MediumInt) VALUES (@MediumInt)");
insert.Parameters.Add("@MediumInt", SqlDbType.Int).Value = 439848;
insert.Connection = conn;
conn.Open();
insert.ExecuteNonQuery();
conn.Close();
}
Querying requires slightly more effort. We’ll still pass in the value as an integer, but we’ll have to perform a CAST in the query to avoid scans. We could also pass the value in as a three byte array, but provided we have access to the query text, it’s easier to perform the conversion there. Furthermore there’s no standard three byte integer type in C#, so we’ll have do perform some ugly magic to convert the three bytes into a normal .NET integer:
using(var conn = new SqlConnection("Data Source=.;Initial Catalog=MediumIntTest;Integrated Security=SSPI;"))
{
varselect = new SqlCommand("SELECT MediumInt FROM ThreeByteInt WHERE MediumInt = CAST(@MediumInt AS binary(3))");
select.Parameters.Add("@MediumInt", SqlDbType.Int).Value = 439848;
select.Connection = conn;
conn.Open();
byte[] bytes = (byte[])select.ExecuteScalar();
int result = BitConverter.ToInt32(newbyte[] { bytes[2], bytes[1], bytes[0], 0 }, 0);
conn.Close();
Console.WriteLine(result);
}
Summing it up
As I’ve shown, we can easily create our own mediumint data type, just as we can create a 5 byte integer, 6 byte… Well, you get it. However, there are obviously some trade offs in that you’ll have to manage this data type yourself. While you can query it more or less like a normal data type, you have to be wary of scans. Finally, retrieving values will require some extra work, though that could easily be abstracted away in a custom type.
So should you do it? Probably not. Saving a single byte per column will gain you very little, unless you have a humongous table, especially so if you have a lot of columns that fit in between the smallint and int value range. For those humongous archival tables, this might just be a way to shave an extra byte off per mediumint column.
One of the first challenges I faced when starting out the development of OrcaMDF was parsing page headers. We all know that pages are basically split in two parts, the 96 byte header and the 8096 byte body of remaining bytes. Much has been written about headers and Paul Randal (b|t) has a great post describing the contents of the header as well. However, though the contents have been described, I’ve been completely unable to find any kind of details on the storage format. What data types are the individual fields, and what’s the order? Oh well, we’ve always got DBCC PAGE.
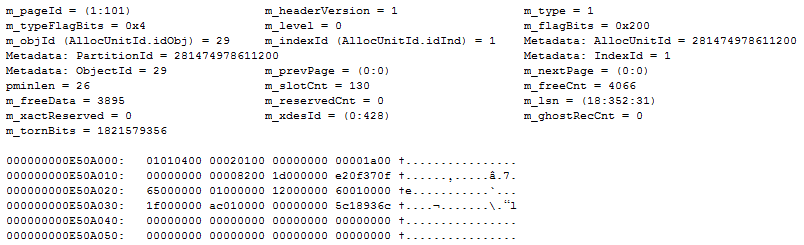
Firing up DBCC PAGE, I scoured for a random data page whose header I could dump, in this case page (1:101):
The result comes in two parts, first we’ve got the header contents as DBCC PAGE kindly parses for us, while the second part is a dump of the 96 bytes that make up the header data:
Armed with this, the hunt begins! What we’re looking for is a match between the parsed values and the bytes in the header. To make it easy, we need to spot some unique values so we don’t get a lot of ambiguity in where the value might be stored. Starting out with m_freeCnt, we see it has a value of 4066. The body size is 8060 bytes so it’s clear that the number can’t be a tinyint. It wouldn’t make sense to make it an int as that supporst way larger values than we need. An educated guess would be that m_freeCnt is probably stored as a smallint, leaving plenty of space for the 0-8060 range we need.
Now, 4066 represented in hex is 0x0FE2. Byte swapped, that becomes 0xE20F, and what do you know, we have a match!
And thus we have identified the first field of our header:
Continuing the search we see that m_freeData = 3895. In hex that’s 0x0F37 and 0x370F when swapped. And voilá, that’s stored right next to m_freeCnt:
Continuing on with this technique, we can map all the distinct header values where there’s no ambiguity as to where they’re stored. But what about a field like m_level? It has the same value as m_xactReserved, m_reservedCnt, m_ghostRecCnt, etc. How do we know which one of those zero values is really m_level? And how do we find out what the data type is? It could be anything from a tinyint to bigint!
Time to bring out the big guns! We’ll start out by shutting down MSSQL / SQL Server:
Then we’ll open up the .mdf file in Visual Studio:
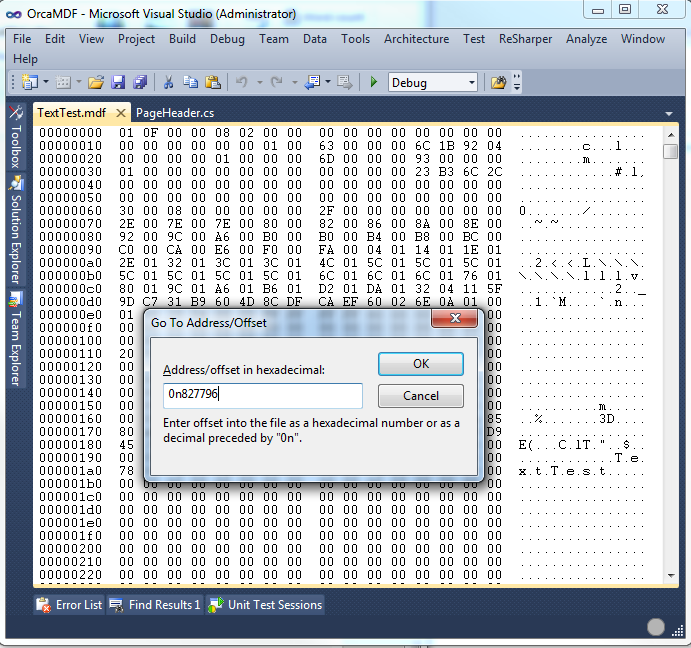
This’ll open up the file in hex editor mode, allowing direct access to all the yummy data! As we know the page id was 101, we need to jump to byte offset 101 * 8192 = 827,392 to get to the first byte of page 101:
Looking at these bytes we see that they’re identical to our header contents, thus confirming we’ve jumped to the correct offset:
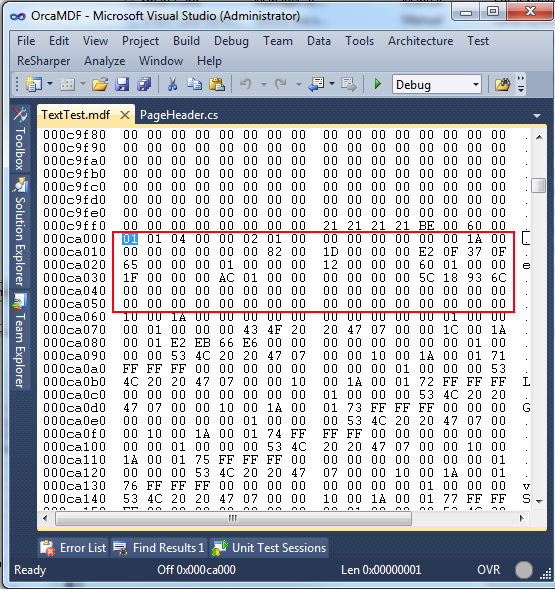
Now I’m going to ask you to do something that will make sheep loving people cry – write some gibberish in there and save the file! Please do not do this to a database with any kind of important data in it. Before:
After:
Oh the horrors! Now restart MSSQL / SQL Server and rerun the DBCC PAGE query from before:
Several values have changed! m_xactReserved had an ambiguous value of 0 before, now it’s at 30,806. Converting that to byte swapped hex we get a value of 0x5678. Looking at the header, we’ve now pinpointed yet another field and datatype (smallint):
And thus we can update our header reference table:
Continuing down this path, messing up the header, correlating messed up values with values parsed by DBCC PAGE, it’s possible to locate all the fields and their corresponding data types. If you see the following message, you know you’ve messed it up properly:
You should be proud of yourself. No go clean up the mess you’ve made!
Jumping forward, I’ve compiled a reference to the page header structure:
I’m not sure what lies in the remaining bytes of the header as DBCC PAGE doesn’t seem to parse stuff there, and it seems to be zeroed out for all pages I’ve tested. I’m assuming it’s reserved bytes for future usage. Once we’ve got the format, parsing becomes a simple task of reading each field, field by field:
I recently had a look at the statistics storage of a system I designed some time ago. As is usually the case, back when I made it, I neither expected nor planned for a large amount data, and yet somehow that table currently has about 750m rows in it.
The basic schema for the table references a given entity and a page number, both represented by ints. Furthermore we register the users Flash version, their IP and the date of the hit.
CREATETABLE #HitsV1
(
EntityID intNOTNULL,
PageNumber intNOTNULL,
Created datetime NOTNULL,
FlashVersion intNULL,
IP varchar(15) NULL
)
Taking a look at the schema, we can calculate the size of the data in the record (synonymous to a row, indicating the structure on disk) to be 4 + 4 + 8 + 4 + 15 = 35 bytes. However, there’s overhead to a record as well, and the narrower the row, the more overhead, relatively.
In this case, the overhead consists of:
Bytes
Content
2
Status bits A & B
2
Length of fixed-length data
2
Number of columns
1
NULL bitmap
2
Number of variable length columns
2
Variable length column offset array
Finally, each record has an accompanying two byte pointer in the row offset array, meaning the total overhead per record amounts to 13 bytes. Thus we’ve got 48 bytes in total per record, and with 8096 bytes of available data space per page, that amounts to a max of about 168 rows per page.
To test things out, we’ll insert 100k rows into the table:
BEGIN TRAN
DECLARE @Cnt int = 0
WHILE @Cnt < 100000BEGININSERTINTO #HitsV1 VALUES (1, 1, getdate(), 1, '255.255.255.255')
SET @Cnt = @Cnt + 1ENDCOMMIT
Note that the actual values doesn’t matter as we’re only looking at the storage effects. Given 168 rows per page, 100.000 rows should fit in about 100.000 / 168 ~= 596 pages. Taking a look at the currently used page count, it’s a pretty close estimate:
SELECT
AU.*
FROM
sys.allocation_units AU
INNERJOIN
sys.partitions P ON AU.container_id = P.partition_id
INNERJOIN
sys.objects O ON O.object_id = P.object_id
WHERE
O.name LIKE'#HitsV1%'
Reconsidering data types by looking at reality and business specs?
If we start out by looking at the overhead, we’ve got a total of four bytes spent on managing the single variable-length IP field. We could change it into a char(15), but then we’d waste space for IP’s like 127.0.0.1 and there’s the whole spaces-at-the-end issue. If we instead convert the IP into an 8-byte bigint on the application side, we save 7 bytes on the column itself, plus 4 for the overhead!
Looking at the FlashVersion field, why do we need a 4-byte integer capable of storing values between –2.147.483.468 and 2.147.483.647 when the actual Flash version range between 1 and 11? Changing that field into a tinyint just saved us 3 bytes more per record!
Reading through our product specs I realize we’ll never need to support more than 1000 pages per entity, and we don’t need to store statistics more precisely than to-the-hour. Converting PageNumber to a smallint just saved 2 extra bytes per record!
As for the Created field, it currently takes up 8 bytes per record and has the ability to store the time with a precision down to one thee-hundredth of a second – obviously way more precise than what we need. Smalldatetime would be much more fitting, storing the precision down to the minute and taking up only 4 bytes – saving a final 4 bytes per record. I we wanted to push it to the extreme we could split Created into two fields – a 3 byte date field and a 1 byte tinyint field for the hour. Though it’d take up the same space, we just gained the ability to store dates all the way up to year 9999 instead of only 2079. As the rapture is coming up shortly, we’ll skip that for now.
So to sum it up, we just saved:
Bytes
Cause
11
Converting IP to bigint
3
Converting FlashVersion to tinyint
2
Converting PageNumber to smallint
4
Converting Created to smalldatetime
In total, 20 bytes per record, resulting in a new total record size of 26 – 28 including the slot offset array pointer. This means we can now fit in 289 rows per page instead of the previous 168.
Testing the new format reveals we’re down to just 364 pages now:
CREATETABLE #HitsV2
(
EntityID intNOTNULL,
CategoryID smallintNOTNULL,
Created smalldatetime NOTNULL,
FlashVersion tinyint NULL,
IP bigint NULL
)
BEGIN TRAN
DECLARE @Cnt int = 0
WHILE @Cnt < 100000BEGININSERTINTO #HitsV2 VALUES (1, 1, getdate(), 1, 1)
SET @Cnt = @Cnt + 1ENDCOMMITSELECT
AU.*
FROM
sys.allocation_units AU
INNERJOIN
sys.partitions P ON AU.container_id = P.partition_id
INNERJOIN
sys.objects O ON O.object_id = P.object_id
WHERE
O.name LIKE'#HitsV2%'
The more rows, the more waste
Looking back at the 750m table, the original format would (assuming an utopian zero fragmentation) take up just about:
And there we have it – spending just a short while longer considering the actual business & data needs when designing your tables can save you some considerable space, resulting in better performance and lower IO subsystem requirements.
Bits are stored very differently from other fixed length data types in SQL Server. Usually all fixed length columns will be present, one after the other, in the fixed data part of a record. As the smallest unit of data we can write to disk is a byte, the naïve approach to storing bits would be to use a whole bit for each bit. It would be very simple to parse as it would follow the usual scheme, but it would also waste quite some space.
How are bits stored internally on records?
Instead, several bit columns values are stored in a single byte, up to a total of 8 max, naturally. Say we had a table definition like this:
CREATETABLE BitTest
(
A bit
B bit
C bit
D int
)
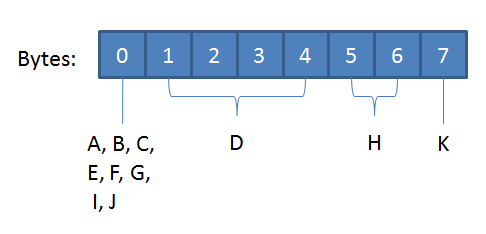
The fixed length data part of our record would be 5 bytes, 4 for the integer column and a single byte, of which only three bits are used, for the bit columns.
Let’s add some more columns:
CREATETABLE BitTest
(
A bit
B bit
C bit
D int
E bit
F bit
G bit
H smallint
I bit
J bit
K bit
)
The bit columns E-G’s ordinal position is after D, but they’ll continue to use the first “bit byte” until it’s full. The following diagram shows that the H smallint column is stored directly after the int column, and not until we add the 9th bit is a new bit byte added:
The need for state while reading bits from records
Obviously we can’t just read one field at a time, incrementing the fixed length data offset pointer for each read, as we usually do for normal fixed length data types. We need some kind of state that will tell us which byte we’re currently reading bits from, and when to read a new bit byte. Allow me to introduce RecordReadState:
publicclass RecordReadState
{
// We start out having consumed all bits as none have been readprivateint currentBitIndex = 8;
privatebyte bits;
publicvoidLoadBitByte(byte bits)
{
this.bits = bits;
currentBitIndex = 0;
}
publicbool AllBitsConsumed
{
get { return currentBitIndex == 8; }
}
publicboolGetNextBit()
{
return (bits & (1 << currentBitIndex++)) != 0;
}
}
RecordReadState is currently only used for handling bits, but I’ve decided on not creating a BitReadState as we may need to save further read state further along. RecordReadState holds a single byte as well as a pointer that points to the next available bit in that byte. If the byte is exhausted (currentBixIndex = 8 (0-7 being the available bits)), AllBitsConsumed will return true, indicating we need to read in a new bit byte. GetNextBit simply reads the current bit from the bit byte, after which it increases the current bit index. See the tests for demonstration.
Implementing SqlBit
Once we have the read state implemented, we can implement the SqlBit type:
SqlBit requires a read state in the constructor, which is scoped for the current record read operation. It’s important to note that the FixedLength depends on the current AllBitsConsumed value of the read state. Once all bits have been consumed, the current bit field will technically have a length of one – causing a byte to be read. If it’s zero, no bytes will be read, but GetValue will still be invoked. GetValue asserts that there are bits available in case a byte wasn’t read (value.Length == 0). If a value was read, we ask the read state to load a new bit byte, after which we can call GetNextBit to return the current bit from the read state. See tests of SqlBit.
There are several different date related data types in SQL Server. Currently OrcaMDF supports the three most common types: date, datetime & smalldatetime.
Implementing SqlDate
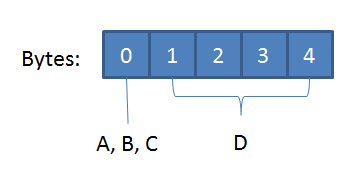
The simplest of the three is date – it’s a 3 byte fixed length type that stores the number of days passed since the default value of 1900-01-01. The only tricky part is that .NET does not have any standard representation of three byte integer values, only shorts & ints which are either too large or too small. Thus, to read the number of days correctly, we’ll have to perform some shift magic to get the correct number into a .NET four byte integer. Once we’ve got the date, we can just create a new default DateTime and add the number of days.
publicclass SqlDate : ISqlType
{
publicbool IsVariableLength
{
get { returnfalse; }
}
publicshort? FixedLength
{
get { return3; }
}
publicobjectGetValue(byte[] value)
{
if (value.Length != 3)
thrownew ArgumentException("Invalid value length: " + value.Length);
// Magic needed to read a 3 byte integer into .NET's 4 byte representation.// Reading backwards due to assumed little endianness.int date = (value[2] << 16) + (value[1] << 8) + value[0];
returnnew DateTime(1, 1, 1).AddDays(date);
}
}
Whereas date only stores the date, datetime also stores a time factor. Datetime is stored as a fixed length 8 byte value, the first being the time part while the second is the date part. Calculating the date is done more or less the same way as in the date example, except this time it’s stored as a normal four byte integer, so it’s much easier to handle. The time part is stored as the number of clock ticks since midnight, with one tick being 1/300th of a second. To represent the tick value, we first define a constant with the value 10d/3d.
All time values are actually stored in the same integer time value, so to access the individual values, we’ll need to perform some division & modulus.
Part
Calculations
Hours
X / 300 / 60 / 60
Minutes
X / 300 / 60 % 60
Seconds
X / 300 % 60
Milliseconds
X % 300 * 10d / 3d
publicclass SqlDateTime : ISqlType
{
privateconstdouble CLOCK_TICK_MS = 10d/3d;
publicbool IsVariableLength
{
get { returnfalse; }
}
publicshort? FixedLength
{
get { return8; }
}
publicobjectGetValue(byte[] value)
{
if (value.Length != 8)
thrownew ArgumentException("Invalid value length: " + value.Length);
int time = BitConverter.ToInt32(value, 0);
int date = BitConverter.ToInt32(value, 4);
returnnew DateTime(1900, 1, 1, time/300/60/60, time/300/60%60, time/300%60, (int)Math.Round(time%300*CLOCK_TICK_MS)).AddDays(date);
}
}
Smalldatetime is brilliant when you need to store a date with limited range (~1900 - ~2079) and a precision down to one second. For most purposes, a time precision of one second is plenty, and we save a lot of space by limiting the precision and date range. A smalldatetime value takes up just 4 bytes, the first two being the number of minutes since midnight, and the last two being the number of days since the default values of 1900-1-1. The math processing done is the same as with datetime, though at a smaller scale.
Part
Calculation
Hours
X / 60
Minutes
X % 60
publicclass SqlSmallDateTime : ISqlType
{
publicbool IsVariableLength
{
get { returnfalse; }
}
publicshort? FixedLength
{
get { return4; }
}
publicobjectGetValue(byte[] value)
{
if (value.Length != 4)
thrownew ArgumentException("Invalid value length: " + value.Length);
ushort time = BitConverter.ToUInt16(value, 0);
ushort date = BitConverter.ToUInt16(value, 2);
returnnew DateTime(1900, 1, 1, time / 60, time % 60, 0).AddDays(date);
}
}
IsVariableLength returns whether this data type has a fixed length size or is variable. FixedLength returns the fixed length of the data type, provided that it is fixed length, otherwise it returns null. The data type parser itself does not care about the length of variable length fields, the size of the input bytes will determine that. Finally GetValue parses the input bytes into and converts them into a .NET object of relevant type.
SqlInt implementation
int is very simple as it’s fixed length and is very straight forward to convert using BitConverter:
publicclass SqlInt : ISqlType
{
publicbool IsVariableLength
{
get { returnfalse; }
}
publicshort? FixedLength
{
get { return4; }
}
publicobjectGetValue(byte[] value)
{
if (value.Length != 4)
thrownew ArgumentException("Invalid value length: " + value.Length);
return BitConverter.ToInt32(value, 0);
}
}
nvarchar is very simple as well – note that we return null for the length as the length varies and the ISqlType implementation must be stateless. GetValue simply converts whatever amount of input bytes it gets into the relevant .NET data type, string in this case.
[TestFixture]
publicclass SqlNvarcharTests
{
[Test]
publicvoidGetValue()
{
var type = new SqlNVarchar();
byte[] input = newbyte[] { 0x47, 0x04, 0x2f, 0x04, 0xe6, 0x00 };
Assert.AreEqual("u0447u042fu00e6", (string)type.GetValue(input));
}
}
Other implementations
OrcaMDF currently supports 12 data types out of the box. I’ll be covering datetime and bit later as those are a tad special compared to the rest of the current types. As the remaining types are implemented, I will be covering those too.
I’ve been spamming Twitter the last couple of days with progress on my pet project, OrcaMDF. But what is OrcaMDF really?
Miracle Open World 2011
I was invited to speak at MOW2011 for the SQL Server track. Last year I got good reviews for my presentation on Dissecting PDF Documents, a deep dive into the file format of PDF files. Wanting to stay in the same grove, I decided to take a look at the MDF format as it’s somewhat closer to SQL Server DBA’s than PDF files. Having almost worn my SQL Server 2008 Internals book down from reading, I’ve always been interested in the internals, though I still felt like I was lacking a lot of knowledge.
A parser is born
For my demos at MOW I wanted to at least read the records from a data page, just like the output from DBCC Page. The basic page format is well documented, and it’s not the first time I’ve taken a deeper look at pages. Surprisingly quickly, I had record parsing from data pages functioning using a hardcoded schema. Parsing a single page is fun, but really, I’d like to get all the data from a table. Restricting myself to just consider clustered tables made it simpler as it’d just be a matter of following the linked list of pages from start to end. However, that meant I’d have to parse the header as well. There’s some good information out there on the anatomy of pages, but everything I could find had a distinct lack of information on the actual header structure and field types.
While resorting to #sqlhelp didn’t directly help me, Kimberly Tripp was kind enough to point out that I’d probably not have any luck in finding deeper documentation out there.
Fast forward a bit of patience, some help from #sqlhelp and @PaulRandal in particular, I managed to reverse engineer the header format, as well as a bit more than I initially set out to do for MOW.
Feature outtakes
With a lot of preconditions (2008 R2 format especially), these are some of the abilities OrcaMDF currently possesses:
Parsing data, GAM, SGAM, IAM, PFS, TextMix, clustered index and and the boot page (preliminary).
Scanning linked pages.
Scanning clustered indexes, either by depth-first into linked-page scan or by forced use of the b-tree structure.
Scanning heaps using IAM chains.
Scanning tables (clustered or heaps) using just the table name as input – root IAM/index page is found through metadata lookup.
Able to parse the following column types: bigint, binary, bit, char, datetime, int, nchar, nvarchar, smallint, tinyint, varbinary & varchar. Adding remaining types is straightforward.
Parsing of four crucial system tables: sysallocunits, sysschobjs, sysrowsets, sysrowsetcolumns.
Parsing of key metadata like table names, types and columns.
There’s probably some errors here and there, and I’ve liberally ignored some complexity here and there thus far, so don’t expect this to work on everything yet. I’m continuing development of OrcaMDF. My hope is to have it support 95+% of typically used features, allowing most MDF files to be parsed. If you have a specific use case or scenario you’d like covered, please get in touch and let me know.
Why oh why are you doing this?
I thought I understood most of what I read about internals. I can now tell you, I did not. Actually parsing this stuff has taught me so much more, as well as given me a really good hands-on understanding of the internals. I’ve still never touched SSIS, SSAS, SSRS and all of that other fancy BI stuff, but I believe having a solid understanding of the internals will make the later stuff so much easier to comprehend.
Furthermore, I think there’s a big opportunity for a number of community supported SQL Server tools to arise. Some possibilities that come to mind (just thinking aloud here, don’t take it too concretely):
Easily distributable read-only access to MDF files to desktops, mobile & embedded clients.
Disaster recovery – forgot to backup and can’t restore your corrupt DB? You might just be able to extract important bits using OrcaMDF.
Need to probe the contents of a DB without attaching it to an instance?
Reading .BAK files – should be possible, will allow single-table restores and object level probing of backup files.
DBCC CHECKDB of non-attached MDF files – this is probably not going to happen, but theoretically possible.
Learning opportunities.
By opening up the code to everybody, this should provide some solid teaching and learning opportunities by looking at samples of how to actually parse the contents and not just read & talk about it.
Alright, alright, show me the codez!
All source code is available on GitHub under the GPLv3 license. Feel free to fork, watch or comment. The only thing I ask for is that you respect the license. If you end up trying out the code or actually using it, please let me know – I’d love to hear about it. Want to follow the latest developments – why don’t you come over and say hi?