One of the best way to improve performance of any website is to reduce the load from clients by allowing them to cache resources. There are various ways to ensure we utilize client side caching to the fullest extent, an often overlooked parameter however, is the actual URL for the resource we want to cache.
The traditional methods
Basically client side caching comes down to three different parameters, the cache policy, the expiration dates as well as the last-modified / etag of the resource.
Through the no-cache policy we can completely disallow all caching of the resource, in which case the resource URL does not matter at all. For this blog entry, I’ll assume we allow caching, just as I’ll assume we have control over the HTML rendered that references the resource.
When caching is allowed, the expiration date defines whether the client can use a locally stored version or whether it has to make a request for the server. Before the browser makes a request to the server, it’ll check if the resource is cached locally. If it is, it will check the expires header of the file - and as long as the expiration date has not been passed, the file will be loaded locally, and no request will be made to the server. Obviously, this is the optimal solution since we completely avoid the overhead of a request to the server - which will help both the client & server performance.
If the expiry date has been passed - or if an expiry date wasn’t sent along with the resource when it was cached - the browser will have to make a request to the server. The server can then check whether the resource has been modified since the last-modified header or etag header (provided the server sent these with the resource originally, and thereby enabling the client to send them back) and send either a 304 or a 200 status back.
URL impact
So what does the actual resource URL have to do with caching? Let’s take Google as an example. On the frontpage of Google there’s an ever changing doodle logo, let’s for discussions sake say the url is google.com/doodle.jpg. Now, since the image isn’t static, we definitely need either to send an expiry header, or if that’s not possible, an etag/last-modified header so the client can at least cache the resource data, and only have to make a if-modified-since request to the server.
Why might it not be possible to send an expiry header? Remember that if we specify an expiry date, the client will not even check in with the server for updates to that resource until the resource has expired locally. Thus, if the resource needs to change in the meantime, clients will suddenly show outdated conent. Because of this, if we do not know the schedule for when resources might change, it can be dangerous / inappropriate to send an expiry header.
There’s a simple way of avoiding the unknown schedule problem while still allowing the client to fully cache the resource without making if-modified-since requests. Simply change the resource URL. If the doodle url is google.com/doodle.jpg, make the next one google.com/doodle1.jpg, doodle2.jpg etc. The URL will still have to be sent along with the HTML code, so there’s no harm in sending a different URL for the new doodle. In this way, the client can be allowed to cache the resource indefinitely - as long as a change in the resource will be saved as a new URL.
Surrogate vs natural keys in URLs
Imagine a scenario where we published books on the internet, with any number of related pages. The catch is, the pages may change over time. Maybe the publisher corrected some errors, added an appendix etc. This rules out setting an expiry header on the individual page resources since we have to be sure we always fetch the most recent version.
There are two ways we might store the data in the database. Here’s one:
[tblBooks]BookID, Name
[tblPages]
BookID, Number, Data
In this example, we use the page’s natural key, a composite of the BookID and Number columns. The pages of a book will always be numbered 1..n and there can be no two pages with the same number, so we have a unique index. Using this table layout, our resource URLs would probably look like this: /Books/[BookID]/[Number]. This means page 2 of the book with ID 5 will always have the same URL: /Books/5/2. Since the URL is the same, the resource might change (if the page is replaced), and we can’t predict when the change will occur (a publisher can do it at any point), we have to rely on last-modified/etags and have the client perform if-modified since requests.
A second way to store the data in the database would be this:
[tblBooks]BookID, Name
[tblPages]
PageID, BookID, Number, Data
The difference being that we’ve introduced a surrogate key in the tblPages table: PageID. This allows us to use URLs like this: /Books/[BookID]/[PageID]. While not as user friendly, it allows us to set an indefinite expiry header and thereby allowing the client to avoid server requests completely.
Adding versions to URLs
Keeping with the book/pages example, let’s add a [LastModified] column to the [tblPages] table:
[tblPages]
BookID, Number, Data, LastModified
We still have a natural key, but now we also store the last modification date of the row - this could either be an application updated value or a database timestamp. The idea is to preserve the natural key in the URLs, but add the LastModified value to the URL for no other reason than to generate a new resource URL when it changes. The first URL might be /Books/5/2/?v=2009-03-08_11:25:00, while the updated version of the page will result in a URL like this: /Books/5/2/?v=2009-03-10_07:32:00. The v parameter is not used for anything serverside, but to the client, it’s a completely unrelated URL and will thus ignore the previously cached resource. This way we can keep the natural base URL the same while still forcing clients to request the new resource whenever it’s changed.
Recap
While properly utilizing caching headers itself is an often overlooked issue, it can be further improved by choosing resource URLs wisely. By combining correct caching headers with changing resource URLs, we can effectively allow the client to cache resources entirely clientside for just the right amount of time, resulting in increased performance for both servers and clients. It’s no silver bullet as caching strategies will always be very domain specific - make sure you understand your domain and create a caching strategy accordingly.
We’re used to using transactions when dealing with the database layer. Transactions ensure we can perform multiple queries as one atomic event, either they all succed or they all fail, obeying the rules of ACIDity. Until Vista, performing transactional file operations haven’t been possible.
Transaction NTFS (or TxF) is available from Vista and onwards, which means Server 2008 is also capable. XP and Server 2003 do not support TxF and there are currently no plans of adding TxF support in systems previous to Vista.
So what is the benefit of using TxF? The benefit is that we can now perform ACID operations in the file level, meaning we can perform several file operations (whether that be moves, deletions, creations etc) and make sure all of them are committed atomically. It also provides isolation from/for other processes, so whenever a transaction has been started, we will always see a consistent view of a view until we have committed the transaction, even though it has been modified otherwhere. Surendra Verma has a great video on Channel 9 explaining TxF. Jon Cargille and Christian Allred has another video on Channel 9 that goes even more in-depth on the inner workings on TxF and the Vista KTM.
Why hasn’t TxF gotten more momentum? Most likely because it’s not part of the BCL! To utilize TxF we have to call Win32 API functions, which is a big step away from lazily utilizing database transactions by just wrapping our code inside of a TransactionScope.
Using TxF is actually quite simple once we’ve made a couple of necessary managed wrapper classes. Let me present you to KtmTransactionHandle:
using System;
using System.ComponentModel;
using System.Runtime.InteropServices;
using System.Transactions;
using Microsoft.Win32.SafeHandles;
namespace TxFTest
{
publicclass KtmTransactionHandle : SafeHandleZeroOrMinusOneIsInvalid
{
///<summary>/// http://msdn.microsoft.com/en-us/library/aa344210(VS.85).aspx///</summary>
[ComImport]
[InterfaceType(ComInterfaceType.InterfaceIsIUnknown)]
[Guid("79427A2B-F895-40e0-BE79-B57DC82ED231")]
privateinterface IKernelTransaction
{
void GetHandle([Out] out IntPtr handle);
}
///<summary>/// http://msdn.microsoft.com/en-us/library/ms724211.aspx///</summary>
[DllImport("kernel32")]
privatestaticexternboolCloseHandle(IntPtr handle);
privateKtmTransactionHandle(IntPtr handle): base(true)
{
this.handle = handle;
}
///<summary>/// http://msdn.microsoft.com/en-us/library/cc303707.aspx///</summary>publicstatic KtmTransactionHandle CreateKtmTransactionHandle()
{
if (Transaction.Current == null)
thrownew InvalidOperationException("Cannot create a KTM handle without Transaction.Current");
return KtmTransactionHandle.CreateKtmTransactionHandle(Transaction.Current);
}
///<summary>/// http://msdn.microsoft.com/en-us/library/cc303707.aspx///</summary>publicstatic KtmTransactionHandle CreateKtmTransactionHandle(Transaction managedTransaction)
{
IKernelTransaction tx = (IKernelTransaction)TransactionInterop.GetDtcTransaction(Transaction.Current);
IntPtr txHandle;
tx.GetHandle(out txHandle);
if (txHandle == IntPtr.Zero)
thrownew Win32Exception("Could not get KTM transaction handle.");
returnnew KtmTransactionHandle(txHandle);
}
protectedoverrideboolReleaseHandle()
{
return CloseHandle(handle);
}
}
}
The KtmTransactionHandle represents a specific transaction going on inside of the KTM. In the code, there’s references for further reading of the specific fucntions, most of them stemming from MSDN. Note that the CreateTransactionHandle method assumes there’s already a current transaction, if there is not, an exception will be thrown.
The second class we need is called TransactedFile. I basically made this to be used as a direct replacement of System.IO.File. It does not include all of the functionality of System.IO.File, but it does have the two most important ones, Open and Delete - most of the other functions are just wrappers of these two, so they are easily appended later on.
using System;
using System.ComponentModel;
using System.IO;
using System.Runtime.InteropServices;
using Microsoft.Win32.SafeHandles;
namespace TxFTest
{
publicclass TransactedFile
{
///<summary>/// http://msdn.microsoft.com/en-us/library/aa363916(VS.85).aspx///</summary>
[DllImport("kernel32", SetLastError=true)]
privatestaticexternboolDeleteFileTransactedW(
[MarshalAs(UnmanagedType.LPWStr)]string file,
KtmTransactionHandle transaction);
///<summary>/// http://msdn.microsoft.com/en-us/library/aa363859(VS.85).aspx///</summary>
[DllImport("kernel32", SetLastError=true)]
privatestaticextern SafeFileHandle CreateFileTransactedW(
[MarshalAs(UnmanagedType.LPWStr)]string lpFileName,
NativeFileAccess dwDesiredAccess,
NativeFileShare dwShareMode,
IntPtr lpSecurityAttributes,
NativeFileMode dwCreationDisposition,
int dwFlagsAndAttributes,
IntPtr hTemplateFile,
KtmTransactionHandle hTransaction,
IntPtr pusMiniVersion,
IntPtr pExtendedParameter);
[Flags]
privateenum NativeFileShare
{
FILE_SHARE_NONE = 0x00,
FILE_SHARE_READ = 0x01,
FILE_SHARE_WRITE = 0x02,
FILE_SHARE_DELETE = 0x04
}
[Flags]
privateenum NativeFileMode
{
CREATE_NEW = 1,
CREATE_ALWAYS = 2,
CREATE_EXISTING = 3,
OPEN_ALWAYS = 4,
TRUNCATE_EXISTING = 5
}
[Flags]
privateenum NativeFileAccess
{
GENERIC_READ = unchecked((int)0x80000000),
GENERIC_WRITE = 0x40000000
}
///<summary>/// Transaction aware implementation of System.IO.File.Open///</summary>///<param name="path"></param>///<param name="mode"></param>///<param name="access"></param>///<param name="share"></param>///<returns></returns>publicstatic FileStream Open(string path, FileMode mode, FileAccess access, FileShare share)
{
using (KtmTransactionHandle ktmHandle = KtmTransactionHandle.CreateKtmTransactionHandle())
{
SafeFileHandle fileHandle = CreateFileTransactedW(
path,
TranslateFileAccess(access),
TranslateFileShare(share),
IntPtr.Zero,
TranslateFileMode(mode),
0,
IntPtr.Zero,
ktmHandle,
IntPtr.Zero,
IntPtr.Zero);
if (fileHandle.IsInvalid)
thrownew Win32Exception(Marshal.GetLastWin32Error());
returnnew FileStream(fileHandle, access);
}
}
///<summary>/// Reads all text from a file as part of a transaction///</summary>///<param name="path"></param>///<param name="contents"></param>///<returns></returns>publicstaticstringReadAllText(string path)
{
using (StreamReader reader = new StreamReader(Open(path, FileMode.Open, FileAccess.Read, FileShare.Read)))
{
return reader.ReadToEnd();
}
}
///<summary>/// Writes text to a file as part of a transaction///</summary>///<param name="path"></param>///<param name="contents"></param>publicstaticvoidWriteAllText(string path, string contents)
{
using (StreamWriter writer = new StreamWriter(Open(path, FileMode.OpenOrCreate, FileAccess.Write, FileShare.None)))
{
writer.Write(contents);
}
}
///<summary>/// Deletes a file as part of a transaction///</summary>///<param name="file"></param>publicstaticvoidDelete(string file)
{
using (KtmTransactionHandle ktmHandle = KtmTransactionHandle.CreateKtmTransactionHandle())
{
if (!DeleteFileTransactedW(file, ktmHandle))
thrownew Exception("Unable to perform transacted file delete.");
}
}
///<summary>/// Managed -> Native mapping///</summary>///<param name="mode"></param>///<returns></returns>privatestatic NativeFileMode TranslateFileMode(FileMode mode)
{
if (mode != FileMode.Append)
return (NativeFileMode)(int)mode;
elsereturn (NativeFileMode)(int)FileMode.OpenOrCreate;
}
///<summary>/// Managed -> Native mapping///</summary>///<param name="access"></param>///<returns></returns>privatestatic NativeFileAccess TranslateFileAccess(FileAccess access)
{
if (access == FileAccess.Read)
return NativeFileAccess.GENERIC_READ;
elsereturn NativeFileAccess.GENERIC_WRITE;
}
///<summary>/// Direct Managed -> Native mapping///</summary>///<param name="share"></param>///<returns></returns>privatestatic NativeFileShare TranslateFileShare(FileShare share)
{
return (NativeFileShare)(int)share;
}
}
}
The primary two API functions used are DeleteFileTransactedW.aspx) and CreateFileTransactedW.aspx). Note that these functions are the ‘W’ versions, accepting unicode paths for the files. To send the strings as null terminated unicode, we have to add the MarshalAs(UnmanagedType.LPWstr) attribute to the ‘path’ parameter.
The BCL FileMode, FileShare and FileAccess all have native counterparts. The constant values are in the Microsoft.Win32.NativeMethods class, but unfortunately it’s internal so we’ll have to make our own. There are three helper functions for translating between the managed and native versions of FileMode, FileShare and FileAccess.
The Open and Delete methods both try to obtain a KTM transaction handle as their first action. If a current transaction does not exist, they will throw an exception since KtmTransactionHandle assumes one exists. We could modify these to either perform a transacted operation or non transacted, depending on the availability of a current transaction, but in this case we’re explicitly assuming a transaction will be available.
Next up the Delete operation will attempt to delete the file using the DeleteFileTransactedW function, passing in the KTM transaction handle. The Open function first tries to obtain a SafeFileHandle for the file, which is basically a wrapper class around a normal file handle. Using the SafeFileHandle, we can create a new FileStream, passing in the file handle as a parameter.
Using these two classes, we can now perform transactional file operations:
using System;
using System.Data.SqlClient;
using System.Transactions;
namespace TxFTest
{
class Program
{
staticvoid Main(string[] args)
{
try
{
using (var ts = new TransactionScope())
{
TransactedFile.WriteAllText("test.txt", "hello world");
}
// At this point test.txt does not exist since we didn't ts.complete()using (var ts = new TransactionScope())
{
TransactedFile.WriteAllText("test.txt", "hello world");
// The transaction hasn't been committed, so the file is still not logically available outisde// of the transaction, but it is available inside of the transaction
Console.WriteLine(TransactedFile.ReadAllText("test.txt"));
// After the transaction is committed, the file is available outside of the transaction
ts.Complete();
}
// Since the TransactionScope works for both database and files, we can combine the two. This is great for ensuring// integrity when we store database related filesusing (var ts = new TransactionScope())
{
SqlCommand cmd = new SqlCommand("INSERT INTO SomeTable (A, B) VALUES ('a', 'b'); SELECT @@IDENTITY");
int insertedID = Convert.ToInt32(cmd.ExecuteScalar());
TransactedFile.WriteAllText(insertedID + ".txt", "Blob file related to inserted database row");
ts.Complete();
}
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
Console.Write("Done");
Console.Read();
}
}
}
Note that the KTM transaction is able to participate in a distributed transaction using the MS DTC service. That means we can both perform database and file operations inside of a transaction scope and have all of them performed ACIDically.
Using transactions comes at a cost - performance. Since the system has to guarantee the ACID properties are respected, there will be administrative overhead as well as the possibility of extra disk activity. Whenever we modify an existing file, the original file is left untouched until the new file has been written to disk, otherwise we might risk destryoying the original file if the computer were to crash halfways through a write procedure.
There are of course limitations in TxF.aspx), as there are in all good things. Most notably it’ll only work for local volumes, you can’t use TxF on file shares as it’s not supported by the CIFS/SMB protocols.
I held a TechTalk on optimizing SQL Server 2005 on the 21st of January. I think it went well so I’m looking forward to the evaluations - please fill them out :)
I have put up the slides, code and test database backup for you to download.
Note that the slides are in Danish - sorry non-danes.
As I mentioned at the end of the TechTalk, I barely made it through all of my slides, and that’s even after I sacrificed a lot of the topics & depth I wanted to talk about. Depending on the evaluations I get back, I’ll probably be announcing a part 2 on this topic later on.
The tool I used to generate test data was Red Gate’s SQL Data Generator. It’s a great tool for quickly making a large set of test data so you can analyze the actual benefits of a properly indexed table.
At a recent TechTalk I talked about code access security and how to perform declarative and imperative security demands & requests. There’s no doubt declarative security checking is nicer than imperative checking, but not everything can be done declaratively.
We want to make sure we have permission to write to the filepath. Declaratively, we can request (SecurityAction.RequestMinimum) for an unrestricted FileIOPermission which would ensure that we had write access. But requesting unrestricted IO access is way overkill, since we only need access to select paths.
I got the question, why we could not perform that security check declaratively? As all declarative security checks are done at JIT and not at runtime, we simply do not have any knowledge of the filePath parameter value, and thus we can’t require permission for those specific paths. The only way we can demand permission for just the paths we need, is to do an imperative permission demand like so:
staticvoid writeFile(string filePath)
{
var perm = new FileIOPermission(FileIOPermissionAccess.Write, filePath);
perm.Demand();
File.WriteAllText("test", filePath);
}
This however, clutters up our writeFile implementation as we now dedicate 2/3 lines for security checking… If only we could do this declaratively.
PostSharp Laos is a free open source AOP framework for .NET. Using PostSharp, we can define our own custom attributes that define proxy methods that will be invoked at runtime, instead of the actual method they decorate. Thus, we are able to define an imperative security check in our custom attribute, which will run before our actual method. I’ll jump right into it and present such an attribute:
// We need to make our attributes serializable:// http://doc.postsharp.org/1.0/index.html#http://doc.postsharp.org/1.0/UserGuide/Laos/Lifetime.html
[Serializable]
publicclass FilePathPermissionAttribute : OnMethodInvocationAspect
{
privatereadonlystring parameterName;
privatereadonly FileIOPermissionAccess permissionAccess;
privateint parameterIndex = -1;
// In the constructor, we take in the required permission access (write, read, etc) as well as// the parameter name that should be used for filepath inputpublicFilePathPermissionAttribute(FileIOPermissionAccess permissionAccess, string parameterName)
{
this.parameterName = parameterName;
this.permissionAccess = permissionAccess;
}
// This method is run at compiletime, and it's only run once - therefore performance is no issue.// We use this to find the index of the requested parameter in the list of parameters.publicoverridevoidCompileTimeInitialize(MethodBase method)
{
ParameterInfo[] parameters = method.GetParameters();
for (int i = 0; i < parameters.Length; i++)
if (parameters[i].Name.Equals(parameterName, StringComparison.InvariantCulture))
parameterIndex = i;
if (parameterIndex == -1)
thrownew Exception("Unknown parameter: " + parameterName);
}
// This method is run when our method is invoked, instead of our actual method. That means this method// becomes a proxy for our real method implementation.publicoverridevoidOnInvocation(MethodInvocationEventArgs eventArgs)
{
// Demand the IOPermission to the requested file pathvar perm = new FileIOPermission(permissionAccess, eventArgs.GetArgumentArray()[parameterIndex].ToString());
perm.Demand();
// If the permission demand above didn't explode, we are now free to invoke the real method.// Calling .Proceed() automatically executes the real method, passing all parameters along.
eventArgs.Proceed();
}
}
In this attribute, we take two parameters, the FileIOPermissionAccess that is required, as well as the name of the parameter containing the file path we should demand permission for. The CompileTimeInitialize method is actually run at compile time - it will look through the list of parameters the method receives, and find the index of the parameter (by its name) and store it for later use. The stored values will be serialized in binary format, thus the need for making the class Serializable. If the parameter name is not found, we throw an exception. It’s important to note that this exception will be thrown at compile time, not at runtime. Thus there’s nothing dangerous in specyfying the parameter by its name (in string format) as we still have full compile time checking. Finally, the OnInvocation method is run when the decorated method is invoked. It’ll do the imperative security check and proceed with the original method call.
Using our FilePathPermission attribute, we can now rewrite our writeFile method as:
[FilePathPermission(FileIOPermissionAccess.Write, "filePath")]
staticvoid writeFile(string filePath)
{
Console.WriteLine("Let's pretend we just successfully wrote a file to: " + filePath);
}
And there we go, we’ve now abstracted the security plumbing code out of our method implementation, while still doing an imperative security demand at runtime. In the same way, we can implement logging, exception handling, parameter sanitation, validation and so forth.
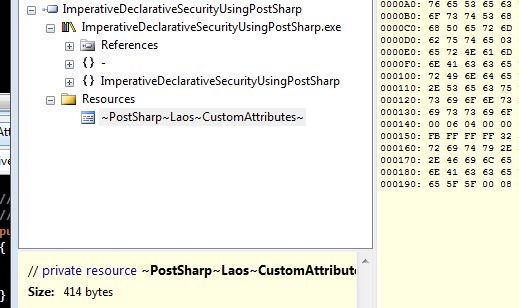
So what happens behind the scenes? The state we saved at compile time is embedded as a resource:
PostSharp also includes a special class it uses to keep track of the decorated methods, aspect state and so forth:
Let’s compare the complete initial code:
publicclass Program
{
staticvoid Main(string[] args)
{
// This could be any kind of user inputstring filePath = @"C:test.txt";
try
{
// We'll simulate that our assembly does not have FileIOPermission by denying itvar perm = new FileIOPermission(PermissionState.Unrestricted);
perm.Deny();
// Now let's simulate that we need to write a file to the user provided path
writeFile(filePath);
}
catch (SecurityException ex)
{
Console.WriteLine(ex);
}
finally
{
// Always, always, always remember to revert your stack walk modifiers
CodeAccessPermission.RevertDeny();
}
// So we keep the console window open
Console.Read();
}
[FilePathPermission(FileIOPermissionAccess.Write, "filePath")]
staticvoid writeFile(string filePath)
{
Console.WriteLine("Let's pretend we just successfully wrote a file to: " + filePath);
}
}
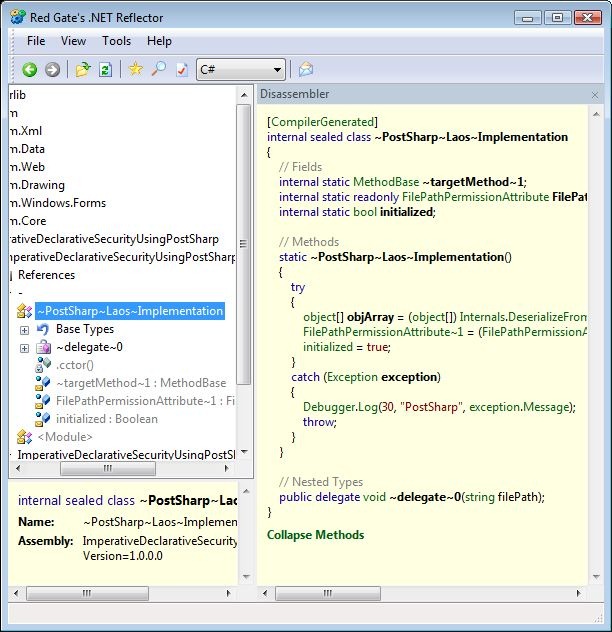
With the reflected code after PostSharp has done its magic:
publicclass Program
{
// Methods
[CompilerGenerated]
static Program()
{
if (!~PostSharp~Laos~Implementation.initialized)
LaosNotInitializedException.Throw();
~PostSharp~Laos~Implementation.~targetMethod~1 = methodof(Program.writeFile);
~PostSharp~Laos~Implementation.FilePathPermissionAttribute~1.RuntimeInitialize(~PostSharp~Laos~Implementation.~targetMethod~1);
}
privatestaticvoid ~writeFile(string filePath)
{
Console.WriteLine("Let's pretend we just successfully wrote a file to: " + filePath);
}
privatestaticvoidMain(string[] args)
{
string filePath = @"C:test.txt";
try
{
try
{
FileIOPermission perm = new FileIOPermission(PermissionState.Unrestricted);
perm.Deny();
writeFile(filePath);
}
catch (SecurityException ex)
{
Console.WriteLine(ex);
}
}
finally
{
CodeAccessPermission.RevertDeny();
}
Console.Read();
}
[DebuggerNonUserCode, CompilerGenerated]
privatestaticvoidwriteFile(string filePath)
{
Delegate delegateInstance = new ~PostSharp~Laos~Implementation.~delegate~0(Program.~writeFile);
object[] arguments = newobject[] { filePath };
MethodInvocationEventArgs eventArgs = new MethodInvocationEventArgs(delegateInstance, arguments);
~PostSharp~Laos~Implementation.FilePathPermissionAttribute~1.OnInvocation(eventArgs);
}
}
Note that these are debug builds, but the code modifications are the same in both release and debug mode. The main method is unaffected. A static initializer has been added which takes care of PostSharp’s intialization, obtaining pointers to the proxy methods - of which there is only one in this example. Finally, the writeFile method has been renamed to ~writeFile (otherwise unmodified), and a new writeFile method has been added. The new writeFile method, generated by PostSharp, invokes our FilePathPermissionAttributes OnInvocation method, passing in an MethodInvocationEventArgs parameter containing the parameter values.
While PostSharp does make a lot of things happen automagically at the compile stage, the effects are rather easy to get a comprehension of. Also, since PostSharp is completely open source and very well documented, you can always pinpoint exactly what happens and why it happens.
What about performance? There’s definitely a performance hit when using PostSharp. The build may be longer since PostSharp is invoked as part of the build process, but in my experience this is a rather quick process. As for runtime performance penalties, I constructed the following short app to test the performance hit by executing it both with and without the LaosTest attribute (using CodeProfiler for profiling):
[Serializable]
publicclass LaosTestAttribute : OnMethodInvocationAspect
{
publicoverridevoidOnInvocation(MethodInvocationEventArgs eventArgs)
{
eventArgs.Proceed();
}
}
class Program
{
staticint i = 0;
staticvoid Main(string[] args)
{
TimeSpan ts = CodeProfiler.ProfileAction(() =>
{
for (int n = 0; n < 1000000; n++)
test();
}, 5);
Console.WriteLine(ts.ToString());
Console.Read();
}
[LaosTest]
staticvoid test()
{
i++;
}
}
Profiling 10^6 calls to test() over five iterations yielded a total runtime of 13.879ms when using the PostSharp attribute - in release mode, excluding the first call. Running the same test, without the attribute, takes just 23ms. That’s 600 times quicker than when using PostSharp. But, still, that’s just 0.0027ms per call when using PostSharp (and nearly unmeasurable when not). Given that in all real life situations, the actual business logic will be much much slower, this performance penalty has almost no effect. Usually, we’re much better off sacrificing these minute amounts of speed over much better manageability of our source code.
Inspired by a recent question on StackOverflow, I felt like sharing my thoughts on static methods in general.
I used to love utility classes filled up with static methods. They made a great consolidation of helper methods that would otherwise lie around causing redundancy and maintenance hell. They’re very easy to use, no instantiation, no disposal, just fire’n’forget. I guess this was my first unwitting attempt at creating a service oriented architecture - lots of stateless services that just did their job and nothing else. As a system grows however, dragons be coming.
Polymorphism
Say we have the method UtilityClass.SomeMethod that happily buzzes along. Suddenly we need to change the functionality slightly. Most of the functionality is the same, but we have to change a couple of parts nonetheless. Had it not been a static method, we could make a derivate class and change the method contents as needed. As it’s a static method, we can’t. Sure, if we just need to add functionality either before or after the old method, we can create a new class and call the old one inside of it - but that’s just gross.
Interface woes
Static methods cannot be defined through interfaces for logic reasons. And since we can’t override static methods, static classes are useless when we need to pass them around by their interface. This renders us unable to use static classes as part of a strategy pattern. We might patch some issues up by passing delegates instead of interfaces.
Testing
This basically goes hand in hand with the interface woes mentioned above. As our ability of interchanging implementations is very limited, we’ll also have trouble replacing production code with test code. Again, we can wrap them up but it’ll require us to change large parts of our code just to be able to accept wrappers instead of the actual objects.
Fosters blobs
As static methods are usually used as utility methods and utility methods usually will have different purposes, we’ll quickly end up with a large class filled up with non-coherent functionality - ideally, each class should have a single purpose within the system. I’d much rather have a five times the classes as long as their purposes are well defined.
Parameter creep
To begin with, that little cute and innocent static method might take a single parameter. As functionality grows, a couple of new parameters are added. Soon further parameters are added that are optional, so we create overloads of the method (or just add default values, in languages that support them). Before long, we have a method that takes 10 parameters. Only the first three are really required, parameters 4-7 are optional. But if parameter 6 is specified, 7-9 are required to be filled in as well… Had we created a class with the single purpose of doing what this static method did, we could solve this by taking in the required parameters in the constructor, and allowing the user to set optional values through properties, or methods to set multiple interdependent values at the same time. Also, if a method has grown to this amount of complexity, it most likely needs to be in its own class anyways.
Demanding consumers to create an instance of classes for no reason
One of the most common arguments is, why demand that consumers of our class create an instance for invoking this single method, while having no use for the instance afterwards? Creating an instance of a class is a very very cheap operation in most languages, so speed is not an issue. Adding an extra line of code to the consumer is a low cost for laying the foundation of a much more maintainable solution in the future. And finally, if you want to avoid creating instances, simply create a singleton wrapper of your class that allows for easy reuse - although this does make the requirement that your class is stateless. If it’s not stateless, you can still create static wrapper methods that handle everything, while still giving you all the benefits in the long run. Finally, you could also make a class that hides the instantiation as if it was a singleton: MyWrapper.Instance is a property that just returns new MyClass();
Only a Sith deals in absolutes
Of course, there are exceptions to my dislike of static methods. True utility classes that do not pose any risk to bloat are excellent cases for static methods - System.Convert as an example. If your project is a one-off with no requirements for future maintenance, the overall architecture really isn’t very important - static or non static, doesn’t really matter - development speed does, however.
Standards, standards, standards!
Using instance methods does not inhibit you from also using static methods, and vice versa. As long as there’s reasoning behind the differentiation and it’s standardised. There’s nothing worse than looking over a business layer sprawling with different implementation methods.
Once you start receiving visitors from all over the world, a new kind of scaling issue arise. It’s not a matter of adding more servers to the cluster or optimizing code (we’ll assume these factors are perfect), it’s a simple matter of geography and mathematics. Serving code from one end of the world to the other will take time, no matter how quick your servers are handling the request. The speed of light suddenly seems quite slow.
At one of my current projects we serve a lot of image data. Letting US based clients fetch all the data from Denmark results in very slow response times. The obvious solution is to partner up with a CDN provider, problem solved. While this may solve the problem, it’ll also cost you a bit as CDN providers, rightfully, are not cheap. If you don’t need the amount of PoPs that the CDN provides, you can setup your own service quite easily using Squid.
The scenario
We want to setup Squid as a reverse proxy. By utilizing a reverse proxy setup, we can use the Squid server with minimal changes to our current configuration. This is very case dependent however - it’ll not be optimal for non-cacheable resources like personalized pages, shortlived data and so forth. In our case we have non-expiring static images with static urls - the perfect case for a reverse proxy setup. Squid will comply completely with the cache properties set by the HTTP headers of your requests, so make sure you’ve got them under control in your solution. In our case, images are served with a lifetime of a year and a static etagwhich’ll ensure Squid won’t purge them unless it’s running short on disk space. So just to summarize this would be the typical scenario for a US based client visiting our website:
Squid has not cached data
Client: Can I please have image X? Squid: Oh, I don’t have it, please wait while I fetch it from Denmark… Squid: [Fetching image from Denmark, storing it on disk and caching it in memory] Squid: There you go, here’s image x!
Squid has cached data
Client: Can I please have image x? Squid: There you go, here’s image x!
After the very first request, Squid will have cached the data and thus all further requests will be served directly from the Squid server location in the US, instead of the client having to go all the way to Denmark. This is basically what a reverse proxy CDN setup does, except it’ll have a lot more PoPs all around the world, and several in the US alone probably.
Installing Squid
So how do we get this working? In this example I’ll be setting up a Squid server on a local VPC that’ll act as a reverse proxy for my website, www.improve.dk. In effect, this will mean that all cacheable resources will be served locally on my computer, while non-cacheable resources will be transparently fetched from improve.dk directly. To avoid overriding the improve.dk domain completely, I’ll set it up to listen on cache.improve.dk and forward the requests to improve.dk instead. To enabled this, I’ve added a line in my hosts file pointing cache.improve.dk to my local VPC running Squid.
Start by obtaining a binary release of Squid. I’ll be using the latest stable release, standard 2.7.STABLE4.
Squid does not require installation as such, simply unzip it where you wish. To make it simple, I’ll install Squid directly in C:squid as the standard Squid configuration expects it to be installed here - it’s easy to change though!.
We’ll start by installing Squid as a service, before doing the actual configuration. Open a command prompt and go to C:squidsbin. Now run “squid -i -n Squid”. This will install Squid as a service under the name “Squid”.
C:\squid\sbin>squid -i -n Squid
Registry stored HKLMSOFTWAREGNUSquid2.6SquidConfigFile value c:/squid/etc/squid.conf
Squid Cache version2.7.STABLE4 for i686-pc-winnt
installed successfully as Squid Windows System Service.
To run, start itfromthe Services Applet of Control Panel.
Don't forget to edit squid.conf before starting it.
Configuring Squid
Before we start Squid, we have to configure it. Go to C:squidetc and make a copy of squid.conf.default and call it squid.conf. Do the same for mime.conf.default (we won’t change this one, but it’s needed). There are hundreds of configuration options, all very well documented. Now, I won’t go over all the options, so simply delete the entire contents of the squid.conf file, we’ll add only the configuration options that we need.
Add the following lines:
acl all src all
acl manager proto cache_object
acl port80 port 80
acl domains url_regex .cache.improve.dk/
The above lines define our acl’s which are used to specify what is allowed and what is not allowed. The first line is used as a catch-all that matches everything. The second line matches a special management interface that we will not be used (and thus might as well deny access to). The third line matches port80. The fourth line defines a regular expression that is used to define what addresses are allowed to be requested. It is very important to define the allowed URLs as your proxy might otherwise be used for any service basically.
Add the following lines:
# DENY CACHEMGR
http_access deny manager
# Deny requests to unknown ports
http_access deny !port80
# ALLOWED DOMAINS
http_access allow domains
# And finally deny all other access to this proxy
http_access deny all
# DENY ALL ICP
icp_access deny all
# HTTP PORT
http_port 80 transparent allow-direct
The acl lines simply specify the match cases, not what is actually allowed and denied. Here we start out by denying access to the management interface and denying access to anything but port 80. Then we allow access to only the specified domains in the regex - and afterwards deny access to everything else by saying “http_access deny all”. We also deny ICP traffic as this is only used in a clustered Squid setup for intersquid chat. Finally we allow transparent direct access to the origin server (the actual www.improve.dk server) on port 80.
Here we set the memory limits for Squid. Note that this is not the total memory limit for Squid, only the limit for hot objects in transit (please see the Squid documentation for complete explanation). We also define that any objects over 2MB should not be stored in memory. Our performance really comes from serving small files directly from memory, instead of storing one PDF at 200MBs in memory. Besides storing the files in memory, Squid also stores them on disk. In the cache_dir line we setup the directory for the disk cache, as well as the max disk size in MBs (200GB in my case). The other options should be left at default (see docs).
This defines the location of the Squid log files. It’ll log all cache requests as well as all disk storage activity. You can customize the log format as well (see docs). The logfile_rotate setting defines how many rotations of log files we’ll use as a max. Each time we do a rotation, the old logfiles are left behind, while a new set of files are created with the rotation number appended. When the rotation has reached 100, it’ll start over from number 0 and overwrite/recreate old log files.
Add the following lines:
# Url rewriting
url_rewrite_program C:/squid/etc/scripts/SquidRewriter.exe
url_rewrite_children 5# Objects without an explicit expiry date will never be considered fresh
refresh_pattern . 00% 0# Remove all proxy headers
header_access X-Cache deny all
header_access X-Cache-Lookup deny all
header_access Via deny all
# ALLOW DIRECT
always_direct allow all
These are the final configuration lines. Ignore the url_rewrite lines for now, I’ll get back to them in just a sec. The refresh_pattern setting is very scenario dependent, it defines the lifetime of objects that do not have an explicit expiry date sent along. As my cache is only intended for static files, any files not having an expiry time should never be cached, and thus I’ve set the lifetime to 0. The header sections basically remove any extra headers normally appended by Squid / any proxy. The final line simply says that all requests (if needed) should be forwarded directly to the origin server, and not ask other servers in the cluster for the data.
Creating a .NET url rewriter
Whenever a request is made for the proxy, it’ll be in the form cache.improve.dk/file. cache.improve.dk doesn’t really exist, and the website doesn’t answer to it, so while Squid receives a request for cache.improve.dk, it should map it back to improve.dk. You could do this by configuration, but that’s no fun (in my case I had to do this for hundreds of domains, so it wasn’t feasibly to do by configuration).
Luckily Squid provides an easy interface for creating custom rewriters, log & storage daemons and so forth. Each time a request comes in Squid will write the url to stdin for the url rewriting daemon and it’ll expect the rewritten url to be output to stdout. It’ll also include some extra whitespace-separated options, but they can simply be ignored, just as Squid will also ignore anything after the first whitespace of the stdout output.
To do the job, I’ve made an über simple console application that does the job:
using System;
namespace SquidRewriter
{
class Program
{
staticvoid Main(string[] args)
{
while (true)
{
string input = Console.ReadLine();
if (input == null || input.Length == 0)
return;
Console.WriteLine(input.Replace("cache.improve.dk", "improve.dk"));
}
}
}
}
We need the null check as when Squid closes the process we’ll get a nullref exception otherwise. Now simply copy the app into C:squidetcscripts and Squid will automatically start it up as a child processes (or several, depending on the configuration - 5 in our case). This simple rewriter can of course be written in any language that can talk to stdin & stdout, that be C[++], Python, F#, you name it.
Starting Squid
Before we can start Squid, we need to create the swap directories. These are the directories in which Squid stores the cached data. Creating the swap directories is a one-time procedure that has to be done before Squid is started for the first time. Do this by running C:squidsbinsquid.exe -z. If you encounter any problems when starting squid, refer to the C:SQUID_LOGScache.log file to see what went wrong.
Once you start Squid (from the Services administration), you’ll notice that it starts the squid.exe process, as well as a number of SquidRewriter.exe processes.
If you open a browser and go to cache.improve.dk, you’ll see the normal improve.dk website. The only difference is that the website is now ported through our locally running Squid. You can confirm this by looking at the C:SQUID_LOGSaccess.log file:
1223221967.1464146192.168.0.11 TCP_MISS/20024172 GET http://cache.improve.dk/ - DIRECT/89.221.162.250 text/html
1223221967.917861192.168.0.11 TCP_MISS/200476 GET http://cache.improve.dk/styles/print.css - DIRECT/89.221.162.250 text/css
1223221967.917861192.168.0.11 TCP_MISS/200549 GET http://cache.improve.dk/scripts/general.js - DIRECT/89.221.162.250 application/x-javascript
1223221967.957901192.168.0.11 TCP_MISS/2006273 GET http://cache.improve.dk/styles/screen.css - DIRECT/89.221.162.250 text/css
1223221968.598621192.168.0.11 TCP_MISS/200695 GET http://cache.improve.dk/images/bg.gif - DIRECT/89.221.162.250 image/gif
1223221968.608631192.168.0.11 TCP_MISS/2004724 GET http://cache.improve.dk/images/logos/top.gif - DIRECT/89.221.162.250 image/gif
1223221968.978961192.168.0.11 TCP_MISS/200586 GET http://cache.improve.dk/images/interface/topmenu/topbg.gif - DIRECT/89.221.162.250 image/gif
1223221972.2431222192.168.0.11 TCP_MISS/20024117 GET http://cache.improve.dk/ - DIRECT/89.221.162.250 text/html
1223221972.25350192.168.0.11 TCP_REFRESH_HIT/304292 GET http://cache.improve.dk/styles/screen.css - DIRECT/89.221.162.250 -
1223221972.26350192.168.0.11 TCP_REFRESH_HIT/304289 GET http://cache.improve.dk/styles/print.css - DIRECT/89.221.162.250 -
1223221972.26350192.168.0.11 TCP_REFRESH_HIT/304292 GET http://cache.improve.dk/scripts/general.js - DIRECT/89.221.162.250 -
1223221972.28320192.168.0.11 TCP_REFRESH_HIT/304287 GET http://cache.improve.dk/images/bg.gif - DIRECT/89.221.162.250 -
1223221972.29330192.168.0.11 TCP_REFRESH_HIT/304293 GET http://cache.improve.dk/images/logos/top.gif - DIRECT/89.221.162.250 -
1223221972.30330192.168.0.11 TCP_REFRESH_HIT/304307 GET http://cache.improve.dk/images/interface/topmenu/topbg.gif - DIRECT/89.221.162.250 -
Now, the above log basically confirms that I suck at setting up caching properties for my blog. Naturally, for the first request we’ll get all TCP_MISS statuses as Squid does not have any of the resources cached. For the next request we get all TCP_REFRESH_HIT’s as Squid does have them cached, but it needs to do a 304 check on the server to see if it’s been modified. Had I set a more liberal refresh_pattern, I could’ve cached these and completely avoided a roundtrip to the improve.dk server (resulting in a TCP_MEM_HIT if it’s cached in-memory). But still, the next user accessing the Squid will have the data served locally, even though Squid has to do a refresh check to the improve.dk server. This issue confirms a very important point - Squid will be best for static data that does not frequently change, and can thus be cached safely. Or at least for dynamic content, you have to consider your usage of expiry policies through the HTTP headers.
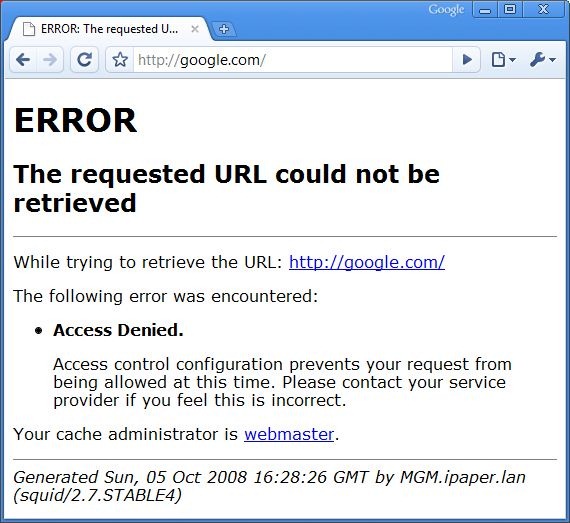
If you add a reference to the local Squid server for google.com, in your hosts line, then you’ll see the error message that pops up due to us filtering away non-improve.dk domains:
Reconfiguration & log rotation
When Squid is running, it’ll ignore any changes you make to the config files until you restart Squid. You can also force Squid to read the config files again without having it restart, simply run the following command:
C:\squid\sbin\squid.exe -k reconfigure -n Squid
To force a log rotation, run:
C:\squid\sbin\squid.exe -k rotate -n Squid
Final considerations
Setting up a Squid server to help speed up your solution for foreign visitors is both cheap & easy. Squid runs in *nix as well as Windows. It has no hardware requirements to speak of and it’s CPU utilization is very limited. Note that it’ll only support a single core, so you won’t get anything from a fancy quad-core setup. Also, it only (there are unofficial builds for x64) runs on x86 so if you want to utilize more than ~3GBs of memory, you’ll have to run multiple instances on different port/ips. As for the setup, I’d recommend to create a special user for Squid that only has access to the Squid directories, otherwise it’ll run with SYSTEM permissions by default.
Squid can not only be used for improving foreign visitor speed, it can also take a lot of static file traffic off of your normal servers. Simply put a Squid in front of your normal servers and let all static/cacheable traffic go through the Squid instead of through the normal app servers.
Some time ago Peter Loft Jensen wrote about how to easily give a user account the neccessary permissions to access the IIS metabase & required directories, and thus be used for running the IIS process.
We’re running all x64 servers, but our IIS is running in 32 bit mode due to some non-x64 compatible 3rd party libraries. Usually this means we have to use the Frameworkversionaspnet_regiis.exe bin instead of the Framework64 version - otherwise it might interfere with our 32 bit IIS settings.
Doing that resulted in the following error:
C:\WINDOWS\microsoft.net\Framework\v2.0.50727>aspnet_regiis -ga [domain][user]
Start granting [domain][user] access to the IIS metabase and other directories used by ASP.NET.
An error has occurred: 0x800703f0 An attempt was made to reference a token that does not exist.
The solution was quite simple, it seems you must use the x64 version on an x64 system to run the -ga command. After using the binary in the Framework64 directory, the command ran perfectly.
I continued my TechTalk on security in the .NET framework today, taking off from where we left last time. As promised, here are the demos and slides (in Danish).
Regarding the demos, the baseline folders contain the code as it was at the beginning of the presentation, the others contain the code as it ended up after the presentation.
I’ve finally succumbed to creating a Twitter account. My gut instinct doesn’t like Twitter, but on the other hand, I do see some possibilities. I don’t know. As the ol’ Cain would’ve said: Stay a while, and listen!
Since I originally posted my XmlOutput class I’ve received lots of great feedback. I’m happy that many of you have found it useful.
I have been using the class myself for most of my xml writing requirements lately (in appropriate scenarios) and I’ve ended up augmenting it a little bit. Nothing major, just a couple of helpful changes.
Automatic xml declaration
Instead of manually declaring our xml declaration each time:
XmlOutput xo = new XmlOutput()
.XmlDeclaration()
.Node("root").Within()
.Node("result").Attribute("type", "boolean").InnerText("true");
XmlOutput will instead add an XmlDeclaration with the default parameters:
var xo = new XmlOutput()
.Node("root").Within()
.Node("result").Attribute("type", "boolean").InnerText("true");
Note that this is a breaking change, meaning it will result in different output than the earlier version did. While you could make an XmlDocument without an XmlDeclaration earlier, you can no longer do this.
Checking for duplicate XmlDeclaration
XmlOutput will throw an InvalidOperationException in case an XmlDeclaration has already been added to the document. I do not allow for overwriting the existing XmlDeclaration as XmlOutput really is forward-only writing and since it might often be a flaw that the XmlDeclaration is overwritten.
IDisposable
Just as I used IDisposable to easily write indented text, I’ve done the same to XmlOutput. For smaller bits of xml, it might cause more bloat than good - but it’s optional when to use it. Using IDisposable will simply call EndWithin() in the Dispose method, making indented xml generation more readable.
using (xo.Node("user").Within())
{
xo.Node("username").InnerText("orca");
// Notice that we're not calling EndWithin() after this block as it's implicitly called in the Dispose methodusing (xo.Node("numbers").Within())
for (int i = 0; i < 10; i++)
xo.Node("number").Attribute("value", i);
xo.Node("realname").InnerText("Mark S. Rasmussen");
}
InnerText & Attribute object values
Instead of explicitly requiring input values of type string, both InnerText and Attribute will now accept objects for the text values. This allows you to easily pass in integers, StringBuilders and so forth.
ToString override
Another breaking change - ToString will now return the OuterXml value of the XmlOutput object.
Making it easy to do it right
Jakob Andersen made a great post regarding how we might extend XmlOutput to return different kinds of interfaces after different operations. This would allow us to utilize IntelliSense as that’d only show the methods that were possible at the current state.
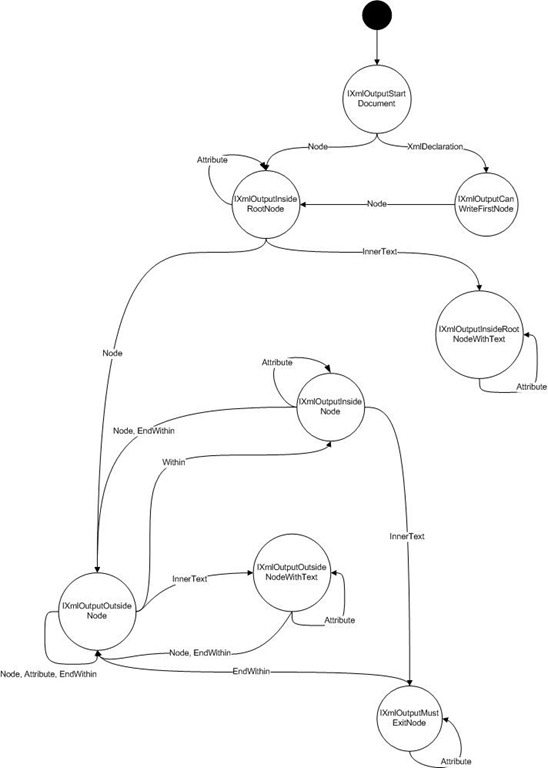
I started implementing it, but I kept running into walls after having thought it through. Let me start out by representing a state machine displaying the different interfaces involved:
So basically, calling a Create method will return an IXmlOutputStartDocument which only supports creating a Node and creating an XmlDeclaration. If you create an XmlDeclaration, you’ll get an IXmlOutputCanWriteFirstNode which only allows you to create a node as that’s the only valid option (ignoring read-only operations). Continuing on, creating a Node at that point will return you an IXmlOutputInsideRootNode which again supports creating either sibling nodes, attributes or innertext. If you call InnerText at this point, we get to a blind alley at the IXmlOutputInsideRootNodeWithText which only allows creating attributes.
Now, on paper, this seems great. The problem however becomes apparent when we start using it:
// xo is now an IXmlOutputCanWriteFirstNodevar xo = XmlOutput.Create()
.XmlDeclaration();
// We've created a root node and ignored the returned IXmlOutputInsideRootNode
xo.Node("root");
// This fails! Since xo is an IXmlOutputCanWriteFirstNode, we're not allowed to create attributes.// Creating the root node above should've changed our type to IXmlOutputInsideRootNode, but it can't since// xo is statically typed as an IXmlOutputCanWriteFirstNode
xo.Attribute("hello", "world");
One way to get around this is to create a new variable after each operation, but I don’t really think I’ll have to explain why this is a bad idea:
// xo1 is now an IXmlOutputCanWriteFirstNodevar xo1 = XmlOutput.Create()
.XmlDeclaration();
// xo2 is now an IXmlOutputCanWriteFirstNodevar xo2 = xo1.Node("root");
// xo3 is now an IXmlOutputInsideRootNodevar xo3 = xo2.Attribute("hello", "world");
Another issue is that we’ll need to have the types change based on the stack level. Imagine we create an IXmlOutputOutsideNode like this:
XmlOutput.Create -> Node –> Node
This will result in us having create a single node inside the root node. We are still within the root node scope (creating another Node will also be a child of the rootnode, but a sibling of the just created node). The problem is, at this point we’re able to call EndWithin() since the IXmlOutputOutsideNode interface allows it, but we can’t move out of the root node scope as we’re on the bottom of the stack. Unless we create interfaces like IXmlOutputOutsideNodeLevel1, Level2, LevelX interfaces, we can’t really support allowing and disallowing EndWithin depending on stack level - and this is a mess I don’t want to get into.
So what’s the conclusion? While the interface based help in regards to fluent interfaces is a great idea, it’s not really easy to implement, as least not as long as we need some kind of recursive functionality on our interfaces. If we had a simple linear fluent interface, it might be easier for us to support it, though we will still have the variable issue.
Code
using System;
using System.Collections.Generic;
using System.Xml;
namespace Improve.Framework.Xml
{
publicclass XmlOutput : IDisposable
{
// The internal XmlDocument that holds the complete structure.
XmlDocument xd = new XmlDocument();
// A stack representing the hierarchy of nodes added. nodeStack.Peek() will always be the current node scope.
Stack<XmlNode> nodeStack = new Stack<XmlNode>();
// Whether the next node should be created in the scope of the current node.bool nextNodeWithin;
// The current node. If null, the current node is the XmlDocument itself.
XmlNode currentNode;
// Whether the Xml declaration has been added to the documentbool xmlDeclarationHasBeenAdded = false;
///<summary>/// Overrides ToString to easily return the current outer Xml///</summary>///<returns></returns>publicoverridestringToString()
{
return GetOuterXml();
}
///<summary>/// Returns the string representation of the XmlDocument.///</summary>///<returns>A string representation of the XmlDocument.</returns>publicstringGetOuterXml()
{
return xd.OuterXml;
}
///<summary>/// Returns the XmlDocument///</summary>///<returns></returns>public XmlDocument GetXmlDocument()
{
return xd;
}
///<summary>/// Changes the scope to the current node.///</summary>///<returns>this</returns>public XmlOutput Within()
{
nextNodeWithin = true;
returnthis;
}
///<summary>/// Changes the scope to the parent node.///</summary>///<returns>this</returns>public XmlOutput EndWithin()
{
if (nextNodeWithin)
nextNodeWithin = false;
else
nodeStack.Pop();
returnthis;
}
///<summary>/// Adds an XML declaration with the most common values.///</summary>///<returns>this</returns>public XmlOutput XmlDeclaration() { return XmlDeclaration("1.0", "utf-8", ""); }
///<summary>/// Adds an XML declaration to the document.///</summary>///<param name="version">The version of the XML document.</param>///<param name="encoding">The encoding of the XML document.</param>///<param name="standalone">Whether the document is standalone or not. Can be yes/no/(null || "").</param>///<returns>this</returns>public XmlOutput XmlDeclaration(string version, string encoding, string standalone)
{
// We can't add an XmlDeclaration once nodes have been added, as the standard declaration will already have been addedif (nodeStack.Count > 0)
thrownew InvalidOperationException("Cannot add XmlDeclaration once nodes have been added to the XmlOutput.");
// Create & add the XmlDeclaration
XmlDeclaration xdec = xd.CreateXmlDeclaration(version, encoding, standalone);
xd.AppendChild(xdec);
xmlDeclarationHasBeenAdded = true;
returnthis;
}
///<summary>/// Creates a node. If no nodes have been added before, it'll be the root node, otherwise it'll be appended as a child of the current node.///</summary>///<param name="name">The name of the node to create.</param>///<returns>this</returns>public XmlOutput Node(string name)
{
XmlNode xn = xd.CreateElement(name);
// If nodeStack.Count == 0, no nodes have been added, thus the scope is the XmlDocument itself.if (nodeStack.Count == 0)
{
// If an XmlDeclaration has not been added, add the standard declarationif (!xmlDeclarationHasBeenAdded)
XmlDeclaration();
// Add the child element to the XmlDocument directly
xd.AppendChild(xn);
// Automatically change scope to the root DocumentElement.
nodeStack.Push(xn);
}
else
{
// If this node should be created within the scope of the current node, change scope to the current node before adding the node to the scope element.if (nextNodeWithin)
{
nodeStack.Push(currentNode);
nextNodeWithin = false;
}
nodeStack.Peek().AppendChild(xn);
}
currentNode = xn;
returnthis;
}
///<summary>/// Sets the InnerText of the current node using CData.///</summary>///<param name="text"></param>///<returns></returns>public XmlOutput InnerText(object text)
{
return InnerText(text.ToString(), true);
}
///<summary>/// Sets the InnerText of the current node.///</summary>///<param name="text">The text to set.</param>///<returns>this</returns>public XmlOutput InnerText(object text, bool useCData)
{
if (useCData)
currentNode.AppendChild(xd.CreateCDataSection(text.ToString()));
else
currentNode.AppendChild(xd.CreateTextNode(text.ToString()));
returnthis;
}
///<summary>/// Adds an attribute to the current node.///</summary>///<param name="name">The name of the attribute.</param>///<param name="value">The value of the attribute.</param>///<returns>this</returns>public XmlOutput Attribute(string name, objectvalue)
{
XmlAttribute xa = xd.CreateAttribute(name);
xa.Value = value.ToString();
currentNode.Attributes.Append(xa);
returnthis;
}
///<summary>/// Same as calling EndWithin directly, allows for using the using statement///</summary>publicvoidDispose()
{
EndWithin();
}
}
}