Having recently read The Pragmatic Programmer and Working Effectively with Legacy Code (both books are amazing - and neither need further review or description as they are globally appreciated as classics), I was feeling ready to read something non-development related, just to get back on my feet again.
I’d heard our CEO speaking highly of a sales book by Frank Bettger, but I’d never really thought more of it. When I found a copy of How I Raised Myself from Failure to Success in Selling in a bag I’d borrowed for a trip to Belgium, I thought I might as well give it a try.
While it’s no programming book, I do feel it was a great read, and I believe it’s got some great tips for anyone dealing with clients - no matter if it’s sales or support related. Some of the chapters may be borderline self-help-ish, but he keeps a sane level of thought all the way through. One of the greatest features of the book is that 70% of the text are war stories of how he either accomplished or failed when speaking with a client. Some of the things he mentions will seem obvious at first, but when you think about it, you realize how you’ve never actually thought about the process behind the technique.
It’s a quick and quite enjoyable read due to his light style of writing and war stories. I highly recommend it to just about anyone, no matter your field of work.
I held my TechTalk on CAS security in the .NET framework today. As promised, here are the demos and slides (in Danish). If you’re asked for a key password, it’s “123456”.
I will be hosting two TechTalks on security in .NET, at Microsoft Denmark in August. The TechTalks will be held in DANISH.
Jakob Andersen will be co-hosting the TechTalks, hopefully filling in on my weak points and vice versa.
I urge participants to comment on this post regarding topics you would like us to talk about, problems you’ve had, suggestions and so forth.
If you’re not attending, please comment anyways - I’ll be blogging a lot on security for the time being and I’m always seeking relevant topics to research further :)
I recently mentioned the possibility of having an assembly provide custom evidence alongside the CLR provided evidence. Let’s see how to do it.
Creating the evidence
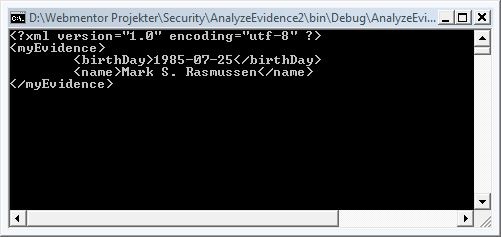
The first step is to actually create the evidence itself. The evidence can be in any form, as long as it’s serializable. That means you can use strings, complex types (provided they’re serializable), or plain old’n’good XML. In lack of a better example, I’ll create a piece of evidence that tells the birthdate and name of the developer behind the assembly. Really useful, I know.
<?xml version="1.0" encoding="utf-8" ?><myEvidence><birthDay>1985-07-25</birthDay><name>Mark S. Rasmussen</name></myEvidence>
Saving the evidence in binary form
To embed our XML as evidence, we first have to save it in binary form. To save a bit of typing, I use my SaveXmlAsBinaryEvidence function:
///<summary>/// Saves the input XML in binary format that can be used when linking custom evidence to an assembly///</summary>///<param name="xml"></param>///<param name="outputFile"></param>publicstaticvoidSaveXmlAsBinaryEvidence(string xml, string outputFile)
{
Evidence customEvidence = new Evidence();
customEvidence.AddAssembly(xml);
using (FileStream fs = new FileStream(outputFile, FileMode.Create))
{
BinaryFormatter bf = new BinaryFormatter();
bf.Serialize(fs, customEvidence);
}
}
This allows us to save out the evidence in binary format using a single line:
If we compile it directly in Visual Studio, we end up with an assembly called TestAssembly.dll - this is not what we want. We need to compile the code into a .netmodule module file so we can manually link it together with our assembly into a finished assembly. Running the following command (with relevant path variables setup, or from the Visual Studio Command Prompt) will compile MyClass into a netmodule called MyClass.netmodule:
csc /target:module MyClass.cs
You can actually load the .netmodule file into Reflector to verify the contents. It’ll work nicely, though Reflector will give a warning since our netmodule does not contain an assembly manifest.
Creating an assembly by linking the netmodule and evidence together
The final step is to link our evidence (MyEvidence.evidence) and netmodule (MyClass.netmodule) together. Make sure both files reside in the same directory (they don’t have to, but it’ll be easier). The following command will invoke AL.exe and do the final assembly linking:
al /target:library /evidence:MyEvidence.evidence /out:MyClass.dll MyClass.netmodule
If you load up the resulting assembly in Reflector, you’ll see the attached evidence under the Resources directory:
Now, if we analyze the assembly evidence by loading the assembly and enumerating the assembly provided evidence like so:
al /target:library /evidence:MyEvidence.evidence /out:MyClass.dll MyClass.netmodule
We see our custom evidence:
Trustworthiness
As mentioned earlier, assembly provided evidence is inherently not trustworthy. There are however ways to secure it. We could use a public/private cryptosystem to sign the actual evidence. That way, anyone reading the evidence could verify the evidence providers signature and thus be sure that the entity linking the evidence into the assembly is trustworthy.
Skilled developers are hard to come by these days, that includes Flash/AS3/Flex developers. As the product I’m working on is very much dependent on a Flash based frontend, I’ve been forced to learn & work with AS3 & Flex recently.
It’s a great experience, learning a new language - especially now that Silverlight is marching forward. As the old saying goes, know your enemy. Anyways, enough with the chit chatting, on with the problems.
Today I tried making a very simple functionality, I wanted to be able to select a number of images by making them highlight when selected, and dim out when deselected:
In this case the button is “selected” from the start (alpha = 1). When clicked, the alpha changes to half opaque (0.5), switches back to 1 when reclicked, and so forth. All working good.
But it’s a bit hard to differentiate between selected and non selected, so let’s change the alpha setting to 0.4 instead of 0.5:
But what’s this, now we’re only able to dim it, not reselect it. Why’s that? Nothing’s changed other than the alpha value. The problem becomes apparent if we trace out the buttons alpha value like so:
In case you don’t have Flash 9 installed, or are just too lazy to click the button, the resulting Alert box shows the following value: 0.3984375 - obviously not quite the 0.4 we specified.
Ok, let’s dumb it down a bit and do some quick testing:
Now this is where things start getting weird. We can obviously store the value 0.4 in a number (which is a 64 bit double-precision format according to the IEEE-754 spec). Furthermore, we’re also able to compare two instances of Number with the value 0.4 and get the expected equality comparison result, true. Now, it would seem that as soon we set the alpha value on our Sprite, it’s corrupted. Sprite inherits the alpha property from DisplayObject - which obviously lists alpha as a value of type Number.
Why does this happen? It’s no problem storing the value 0.4 in a 64 bit double precision number:
Sign: +1Exponent: -2Mantissa: 1.6Result: sign x 2<sup>exponent</sup> x mantissa => +1 x 2<sup>-2</sup> x 1.6 = 0.4
It might be (and probably is) me not understanding something right. Can somebody explain to me how the Flash VM handles Numbers, and thereby, explain why this is happening? Is it perhaps not due to the VM’s handling of Numbers, but instead just a simple matter of an odd implementation of the alpha property on DisplayObject?
When the CLR loads an assembly and needs to determine the appropriate permission set to apply, it’s based on various evidence. Assembly evidence tells the CLR about the origins of the assembly, the zone it’s loaded from and the file hash of the actual assembly file - these are just some of the more common evidence types the CLR uses, there are a lot more that are rarely used. Any object can be a piece of evidence, the CLR will only react on well known evidence types though.
There are two different overall origins of evidence, assembly provided and CLR provided. When the CLR loads an assembly, it recognizes the evidence based on the location the assembly is loaded from, file hash and so forth - this is the CLR provided evidence. The other type of evidence is custom evidence provided by the assembly itself. Although useful, we have to be careful not to blindly trust this evidence as it’s provided by the assembly manufacturer. Thus an assembly manufacturer might provide a piece of evidence claiming that the assembly is provided by Microsoft / Google / some other trustworthy corporation - even though that might not be the case.
Any loaded assembly has an evidence property of type System.Security.Policy.Evidence. The Evidence class has three relevant functions for obtaining the actual evidence, namely GetHostEnumerator, GetAssemblyEnumerator and GetEnumerator. GetHostEnumerator returns an IEnumerator containing the evidence policies, likewise the GetAssemblyEnumerator returns the assembly provided (and inherently untrustworthy) policies, while the GetEnumerator returns the union of the two.
Just a quick tip. I hate using enumerators, I much prefer foreach loops. The following method will take an IEnumerator and yield an IEnumerable, enabling you to foreach the collection:
publicstatic IEnumerable GetEnumerable(IEnumerator enumerator)
{
while (enumerator.MoveNext())
yieldreturn enumerator.Current;
}
I’ve created a simple assembly containing an empty class (the contents of the assembly is not relevant in regards to evidence) called TestAssembly. The following code will load in the TestAssembly from the application directory and enumerate the CLR provided evidence. Note that I’ve got a special case for theSystem.Security.Policy.Hash.aspx) type as it includes a rather lengthy hash of the file. The hash evidence can be used to validate the assembly contents against a pre-known hash of the assembly as a simple way of tamper protecting your applications assemblies.
Assembly asm = Assembly.LoadFile(Path.Combine(Path.GetDirectoryName(Assembly.GetExecutingAssembly().Location), "TestAssembly.dll"));
foreach (object obj in EnumeratorHelper.GetEnumerable(asm.Evidence.GetHostEnumerator()))
if (obj is Hash)
Console.WriteLine(@"<System.Security.Policy.Hash version=""1""><RawData>4D5A900003...00000</RawData></System.Security.Policy.Hash>");
else
Console.WriteLine(obj.ToString());
As we can see, it gives us the URL from where the assembly was loaded, our security zone (MyComputer since it was loaded locally), and finally the dummy hash.
I’ve got a test server running called Mirage. Mirage is part of the Active Directory domain ipaper.lan and I’ve set a website up on it answering to the default address http://mirage.ipaper.lan. When loading the TestAssembly from this website, the evidence changes a bit:
This time the SecurityZone is defined as Internet. Although my server is placed on my local network, it’s known as the internet by my computer. This time we also get the Site policy since the assembly is loaded from a website, namely mirage.ipaper.lan. The security zone is actually provided by Windows (using theIInternetSecurityManager::MapUrlToZone method.aspx)) and not by the CLR itself, except in the case of locally loaded assemblies - in which it’ll automatically set the zone to MyComputer. Thus, if I add mirage.ipaper.lan to my Internet Options control panel Intranet sites list, my SecurityZone changes to Intranet instead of Internet. Likewise I can add it to my trusted & untrusted sites list and modify the resulting SecurityZone.
I often need to output indented text in one way of the other, it could be HTML, XML, source code etc (please look beyond the actual problem domain - I’d enver write XML this way, it’s just an example). Usually that involved me writing tab characters manually (or by calling a function that returned the current indentation string), cluttering the actual output. An example might look like this:
Pretty simple code, but it’s a bit hard for the eyes, especially if there’s a lot of it.
By utilizing the IDisposable interface, we can create a StringBuilder-esque class that handles the indentation for us. Here’s an example of how we might write the previous snippet using the IndentedStringBuilder (note that it’s not really a StringBuilder since StringBuilder’s a sealed class):
using (IndentedStringBuilder sb = new IndentedStringBuilder())
{
sb.AppendLine("public static void Hello()");
sb.AppendLine("{");
using (sb.IncreaseIndent())
{
sb.AppendLine("if(true)");
using (sb.IncreaseIndent())
sb.AppendLine("Console.WriteLine("World!");");
}
sb.AppendLine("}");
Console.Write(sb.ToString());
Console.Read();
}
Each time Dispose() is called on the instance, the indentation level is decreased. Calling IncreaseIndent() increases the indentation level, as well as returning a reference to the IndentedStringBuilder instance itself. The using construct will make sure Dispose is called on the reference each time we exit the using block - and calling Dispose does not do anything to the object other than calling the Dispose method - which’ll decrease the indentation level.
Here’s the IndentedStringBuilder class:
using System;
using System.Text;
namespace Improve.Framework.Text
{
publicclass IndentedStringBuilder : IDisposable
{
private StringBuilder sb;
privatestring indentationString = "\t";
privatestring completeIndentationString = "";
privateint indent = 0;
///<summary>/// Creates an IndentedStringBuilder///</summary>publicIndentedStringBuilder()
{
sb = new StringBuilder();
}
///<summary>/// Appends a string///</summary>///<param name="value"></param>publicvoidAppend(stringvalue)
{
sb.Append(completeIndentationString + value);
}
///<summary>/// Appends a line///</summary>///<param name="value"></param>publicvoidAppendLine(stringvalue)
{
Append(value + Environment.NewLine);
}
///<summary>/// The string/chars to use for indentation, t by default///</summary>publicstring IndentationString
{
get { return indentationString; }
set
{
indentationString = value;
updateCompleteIndentationString();
}
}
///<summary>/// Creates the actual indentation string///</summary>privatevoidupdateCompleteIndentationString()
{
completeIndentationString = "";
for (int i = 0; i < indent; i++)
completeIndentationString += indentationString;
}
///<summary>/// Increases indentation, returns a reference to an IndentedStringBuilder instance which is only to be used for disposal///</summary>///<returns></returns>public IndentedStringBuilder IncreaseIndent()
{
indent++;
updateCompleteIndentationString();
returnthis;
}
///<summary>/// Decreases indentation, may only be called if indentation > 1///</summary>publicvoidDecreaseIndent()
{
if (indent > 0)
{
indent--;
updateCompleteIndentationString();
}
}
///<summary>/// Decreases indentation///</summary>publicvoidDispose()
{
DecreaseIndent();
}
///<summary>/// Returns the text of the internal StringBuilder///</summary>///<returns></returns>publicoverridestringToString()
{
return sb.ToString();
}
}
}
Through various projects, I’ve had to do some shortest-path finding in a connected graph. An efficient and straight-forward way to do this is using Dijkstra’s Algorithm. Notice that it’ll only work for graphs with non negative path weights, like 2D maps for instance. While I’ve used the algorithm on several occasions, it’s only now that I’ve rewritten it in generic form
using System;
using System.Collections.Generic;
using System.Linq;
namespace Improve.Framework.Algorithms
{
publicclass Dijkstra<TNode>
{
///<summary>/// Calculates the shortest route from a source node to a target node given a set of nodes and connections. Will only work for graphs with non-negative path weights.///</summary>///<param name="connections">All the nodes, as well as the list of their connections.</param>///<param name="sourceNode">The node to start from.</param>///<param name="targetNode">The node we should seek.</param>///<param name="fnEquals">A function used for testing if two nodes are equal.</param>///<param name="fnDistance">A function used for calculating the distance/weight between two nodes.</param>///<returns>An ordered list of nodes from source->target giving the shortest path from the source to the target node. Returns null if no path is possible.</returns>publicstatic List<TNode> ShortestPath(IDictionary<TNode, List<TNode>> connections, TNode sourceNode, TNode targetNode, Func<TNode, TNode, bool> fnEquals, Func<TNode, TNode, double> fnDistance)
{
// Initialize values
Dictionary<TNode, double> distance = new Dictionary<TNode, double>(); ;
Dictionary<TNode, TNode> previous = new Dictionary<TNode, TNode>(); ;
List<TNode> localNodes = new List<TNode>();
// For all nodes, copy it to our local list as well as set it's distance to null as it's unknownforeach (TNode node in connections.Keys)
{
localNodes.Add(node);
distance.Add(node, double.PositiveInfinity);
}
// We know the distance from source->source is 0 by definition
distance[sourceNode] = 0;
while (localNodes.Count > 0)
{
// Return and remove best vertex (that is, connection with minimum distance
TNode minNode = localNodes.OrderBy(n => distance[n]).First();
localNodes.Remove(minNode);
// Loop all connected nodesforeach (TNode neighbor in connections[minNode])
{
// The positive distance between node and it's neighbor, added to the distance of the current nodedouble dist = distance[minNode] + fnDistance(minNode, neighbor);
if (dist < distance[neighbor])
{
distance[neighbor] = dist;
previous[neighbor] = minNode;
}
}
// If we're at the target node, breakif (fnEquals(minNode, targetNode))
break;
}
// Construct a list containing the complete path. We'll start by looking at the previous node of the target and then making our way to the beginning.// We'll reverse it to get a source->target list instead of the other way around. The source node is manually added.
List<TNode> result = new List<TNode>();
TNode target = targetNode;
while (previous.ContainsKey(target))
{
result.Add(target);
target = previous[target];
}
result.Add(sourceNode);
result.Reverse();
if (result.Count > 1)
return result;
elsereturnnull;
}
}
}
Once we’ve made the list of nodes & connections, invoking the algorithm is rather simple. We just need to provide an equality function as well as a distance function:
// Run Dijkstra's algorithm
List<Point2D> result = Dijkstra<Point2D>.ShortestPath(connections, mouse, target, (p1, p2) => p1 == p2, (p1, p2) => p1.DistanceTo(p2));
It’s a unique book unlike most others I’ve read. Most of the books I read are practically oriented, how to do this, how to do that (in an abstract way, but still practical).
Programmers at Work contains interviews with 19 of the most influential computer programmers, written in the early 80’s. It’s an eye opener how similar the though processes, scenarios and development ideas where back then to what we’re used to today. They didn’t have nearly the same facilities at hand, neither hardware nor codewise, but the goals were the same. It’s fun to read some fundamental discussions about whether OS’s have a place at all, or whether they should simply be discarded (I guess that’d be the embedded devices of today).
While all interviewees are techy guys in one way or the other, there’s great diversity among them. Some are downright developers/architects while others work on the UI, graphics and even audio design.
There are lots of great war stories in most interviews, 40% of them about Apple - it really becomes clear how big a part Apple played back then, and how small they became for a period which seems to be nearing an end.
The original method relied heavily on reflection to set the values directly. Reflection’s bad in regards of speed, mkay? But reflection is not necessarily evil, you can do great good with it. Now, the problem with the original method is that each field is set using reflection for each row, that’s [number of fields] * [number of rows] fields being set using reflection, resulting in pretty poor performance. If we compare it to the manual way, there’s obviously some kind of a gap. If we could just somehow, in a generic way, create mapper methods like we do manually…
We’ll have to create a DynamicMethod that takes in a DbDataReader, converts the current row to a generic type T. We’ll call it MapDR, although it doesn’t really matter what it’s called.
// Our method will take in a single parameter, a DbDataReader
Type[] methodArgs = { typeof(DbDataReader) };
// The MapDR method will map a DbDataReader row to an instance of type T
DynamicMethod dm = new DynamicMethod("MapDR", typeof(T), methodArgs, Assembly.GetExecutingAssembly().GetType().Module);
ILGenerator il = dm.GetILGenerator();
In this method, we’ll create an instance of the generic type T and store it as a variable.
// We'll have a single local variable, the instance of T we're mapping
il.DeclareLocal(typeof(T));
// Create a new instance of T and save it as variable 0
il.Emit(OpCodes.Newobj, typeof(T).GetConstructor(Type.EmptyTypes));
il.Emit(OpCodes.Stloc_0);
Then we’ll look each property of the type.
foreach (PropertyInfo pi intypeof(T).GetProperties())
Now we’ll read the column value from the DbDataReader using the properties name. By reading it, we’re pushing it onto the stack.
// Load the T instance, SqlDataReader parameter and the field name onto the stack
il.Emit(OpCodes.Ldloc_0);
il.Emit(OpCodes.Ldarg_0);
il.Emit(OpCodes.Ldstr, pi.Name);
// Push the column value onto the stack
il.Emit(OpCodes.Callvirt, typeof(DbDataReader).GetMethod("get_Item", new Type[] { typeof(string) }));
Now’s the ugly part. Depending on the type, there are different ways to convert it into the corresponding .NET type, i’ve made a switch statement handling most common types, although it does lack support for nullable types, guids and various other numeric formats. It should show to idea though. Converting the value will push the resulting correctly typed value onto the stack, and pop the original value in the process.
// Depending on the type of the property, convert the datareader column value to the typeswitch (pi.PropertyType.Name)
{
case"Int16":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToInt16", new Type[] { typeof(object) }));
break;
case"Int32":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToInt32", new Type[] { typeof(object) }));
break;
case"Int64":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToInt64", new Type[] { typeof(object) }));
break;
case"Boolean":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToBoolean", new Type[] { typeof(object) }));
break;
case"String":
il.Emit(OpCodes.Callvirt, typeof(string).GetMethod("ToString", new Type[] { }));
break;
case"DateTime":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToDateTime", new Type[] { typeof(object) }));
break;
case"Decimal":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToDecimal", new Type[] { typeof(object) }));
break;
default:
// Don't set the field value as it's an unsupported typecontinue;
}
And finally we set the properties value, thereby popping the value from the stack.
// Set the T instances property value
il.Emit(OpCodes.Callvirt, typeof(T).GetMethod("set_" + pi.Name, new Type[] { pi.PropertyType }));
After we’ve mapped all the properties, we’ll load the T instance onto the stack and return it.
// Load the T instance onto the stack
il.Emit(OpCodes.Ldloc_0);
// Return
il.Emit(OpCodes.Ret);
To improve performance, let’s cache this mapper method as it’ll work for the type T the next time we need it. Notice that what we’re caching is not the method itself, but a delegate to the method - enabling us to actually call the method.
privatedelegate T mapEntity<T>(DbDataReader dr);
privatestatic Dictionary<Type, Delegate> cachedMappers = new Dictionary<Type, Delegate>();
// Cache the method so we won't have to create it again for the type T
cachedMappers.Add(typeof(T), dm.CreateDelegate(typeof(mapEntity<T>)));
// Get a delegate reference to the dynamic method
mapEntity<T> invokeMapEntity = (mapEntity<T>)cachedMappers[typeof(T)];
Now all we gotta do is loop the DbDataReader rows and return the mapped entities.
// For each row, map the row to an instance of T and yield return itwhile (dr.Read())
yieldreturn invokeMapEntity(dr);
And of course, here’s the final method/class. Remember that this is more a proof of concept than a complete class. It ought to handle all necessary types. Also, it might be relevant to consider whether one should map public as well as private properties. Whether it should handle type validation errors, missing columns or not, I’m not sure. As it is now, it’ll throw a normal ArgumentOutOfRangeException in cases of missing columns, and relevant type conversion errors - all those can be handled by the callee using try/catch blocks.
using System;
using System.Collections.Generic;
using System.Data.Common;
using System.Reflection;
using System.Reflection.Emit;
namespace Improve.Framework.Data
{
publicclass EntityMapper
{
privatedelegate T mapEntity<T>(DbDataReader dr);
privatestatic Dictionary<Type, Delegate> cachedMappers = new Dictionary<Type, Delegate>();
publicstatic IEnumerable<T> MapToEntities<T>(DbDataReader dr)
{
// If a mapping function from dr -> T does not exist, create and cache oneif (!cachedMappers.ContainsKey(typeof(T)))
{
// Our method will take in a single parameter, a DbDataReader
Type[] methodArgs = { typeof(DbDataReader) };
// The MapDR method will map a DbDataReader row to an instance of type T
DynamicMethod dm = new DynamicMethod("MapDR", typeof(T), methodArgs, Assembly.GetExecutingAssembly().GetType().Module);
ILGenerator il = dm.GetILGenerator();
// We'll have a single local variable, the instance of T we're mapping
il.DeclareLocal(typeof(T));
// Create a new instance of T and save it as variable 0
il.Emit(OpCodes.Newobj, typeof(T).GetConstructor(Type.EmptyTypes));
il.Emit(OpCodes.Stloc_0);
foreach (PropertyInfo pi intypeof(T).GetProperties())
{
// Load the T instance, SqlDataReader parameter and the field name onto the stack
il.Emit(OpCodes.Ldloc_0);
il.Emit(OpCodes.Ldarg_0);
il.Emit(OpCodes.Ldstr, pi.Name);
// Push the column value onto the stack
il.Emit(OpCodes.Callvirt, typeof(DbDataReader).GetMethod("get_Item", new Type[] { typeof(string) }));
// Depending on the type of the property, convert the datareader column value to the typeswitch (pi.PropertyType.Name)
{
case"Int16":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToInt16", new Type[] { typeof(object) }));
break;
case"Int32":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToInt32", new Type[] { typeof(object) }));
break;
case"Int64":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToInt64", new Type[] { typeof(object) }));
break;
case"Boolean":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToBoolean", new Type[] { typeof(object) }));
break;
case"String":
il.Emit(OpCodes.Callvirt, typeof(string).GetMethod("ToString", new Type[] { }));
break;
case"DateTime":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToDateTime", new Type[] { typeof(object) }));
break;
case"Decimal":
il.Emit(OpCodes.Call, typeof(Convert).GetMethod("ToDecimal", new Type[] { typeof(object) }));
break;
default:
// Don't set the field value as it's an unsupported typecontinue;
}
// Set the T instances property value
il.Emit(OpCodes.Callvirt, typeof(T).GetMethod("set_" + pi.Name, new Type[] { pi.PropertyType }));
}
// Load the T instance onto the stack
il.Emit(OpCodes.Ldloc_0);
// Return
il.Emit(OpCodes.Ret);
// Cache the method so we won't have to create it again for the type T
cachedMappers.Add(typeof(T), dm.CreateDelegate(typeof(mapEntity<T>)));
}
// Get a delegate reference to the dynamic method
mapEntity<T> invokeMapEntity = (mapEntity<T>)cachedMappers[typeof(T)];
// For each row, map the row to an instance of T and yield return itwhile (dr.Read())
yieldreturn invokeMapEntity(dr);
}
publicstaticvoidClearCachedMapperMethods()
{
cachedMappers.Clear();
}
}
}