The agenda for SQLBits 9 has been published (though it’s still provisional). It’s looking really, really good. Especially so when you consider the price of the event – you’ve got until the 26th of August to get the early bird price of £375 for two complete days of conference – PLUS a whole day of full day training sessions.
My presentation
I’ll be presenting my Knowing the Internals, Who Needs SQL Server Anyway? session. This is by far my favorite session! I originally gave it back in April at Miracle Open World, though under the name “Anatomy of an MDF File”. Since then, I’ve added a good three months of development onto OrcaMDF, the project on which the backend of the session is based. As such, this session will be even more awesome than last! Here’s the abstract:
You’re stuck on a remote island with just a laptop and your main database .MDF file. The boss calls and asks you to retrieve some data, but alas, you forgot to install SQL Server on your laptop. Luckily you have a HEX editor by your side!
In this level 500 deep dive session we will go into the intimate details of the MDF file format. Think using DBCC Page is pushing it? Think again! As a learning experiment, I’ve created an open source parser for MDF files, called OrcaMDF. Using the OrcaMDF parser I’ll go through the primary storage structures, how to parse page headers, boot pages, internal system tables, data & index records, b-tree structures as well as the supporting IAM, GAM, SGAM & PFS pages.
Has your database suffered an unrecoverable disk corruption? This session might just be your way out! Using a corrupt & unattachable MDF file, I’ll demo how to recover as much data as possible. This session is not for the faint of heart, there will be bits & bytes.
Join me for a journey into the depths of the SQL Server storage engine. Through a series of lectures and demonstrations we’ll look at the internals of pages, data types, indexes, heaps, extent & page allocation, allocation units, system views, base tables and nightmarish ways of data recovery. We’ll look at several storage structures that are either completely undocumented or very scarcely so. By the end of the day, not only will you know about the most important data structures in SQL Server, you’ll also be able to parse every bit of a SQL Server data file yourself, using just a hex editor! There will be lots of hands on demos, a few of them performed in C# to demonstrate the parsing of data files outside of SQL Server.
In a moment of weakness I pleged to make an absolute fool of myself for this months Meme Monday. I wish I could say that this happened 20 years ago, when I was but a young grasshopper. To my disgrace, this happened fewer years ago than I’d like to admit.
Wow, that’s a lot of data!
As part of beginning a new project that would publish catalogs on the web, I tried to do some capacity calculations on storing user statistics. We needed to be able to query the number of views a single page in a given catalog had had, by the hour. Assuming a worst case scenario of 24/7 visitors for a catalog with 100 pages, that would equal 100 pages 24 hours 365 days, roughly equal to a million rows per year, per catalog.
At this point I’d been working with SQL Server for some years, though exclusively as a developer. I had no knowledge of the inner workings, storage, index internals, etc. I knew enough to get by as a normal web dev, never really reaching any limits in SQL Server no matter how brain dead my solutions were. As a result, when I figured we might have hundreds of these catalogs, we might have hundreds of millions of rows. Wow, there’s absolutely no way SQL Server will be able to search that must data in a table!
Reinventing the clustered index
Being convinced there was no way SQL Server would be able to search that many rows in a single table, I chose to shard my data. Not into separate tables, that’d be too easy. Instead I opted to create a database per catalog, with the sole purpose of storing statistics.
This was brilliant. It really was. Or at least I thought so.
Now instead of SQL Server having to search through a hundred million row large table, I would just query my catalog statistics like so:
SELECT * FROM CatalogStatistics_[CatalogID].dbo.StatisticsTable WHERE Period BETWEEN @X AND @Y
I knew indexes were crucial to querying so I made sure to create a nonclustered index on the Period column. Usually It’d go unused as it would require massive amounts of bookmark lookups and there’d be sufficiently small amounts of data that a clustered index scan was more effective.
Knowing of indexes does not mean you understand them
Obviously I’d heard of indexes, I’d even used them actively. I thought I understood them – you just create them on the columns you query and everything works faster, right?
I’ll give myself the credit that I knew SQL Server would need some kind of way to quickly narrow down the data it had to search. I thought I’d help out SQL Server by storing the data in separate databases, making sure it would be easy for it to scan just the data for a specific catalog. Had I known how indexes really worked, being stored in an ordered binary tree, I’d realize SQL Server wouldn’t benefit from my scheme at all.
I just made stuff worse by causing log trashing, disk trashing, memory trashing, management trashing, backup trashing, you name it, I trashed it.
Dude, this isn’t gonna work
Fast forward a couple of months. Performance wasn’t the bottleneck as there just wasn’t nearly enough data or querying to really cause concern. What was becoming a bottleneck on the other hand; management. We were on a managed server solution with an external hosting company acting as DBAs, though only ensuring SQL Server was running and was backed up. I got an email saying that they were having trouble handling our backups. At that point we had just short of 3.000 databases on the instance.
At the same time I was having trouble satisfying our querying requirements. In the beginning we just needed to query the statistics of a single catalog at a time. Later on we needed to dynamically aggregate statistics across several catalogs at a time. Suffice to say, this didn’t work out well in the long run:
SELECT X, Y, Z FROM CatalogStatistics_123.dbo.StatisticsTable WHERE Period BETWEEN @X AND @Y
UNIONALLSELECT X, Y, Z FROM CatalogStatistics_392.dbo.StatisticsTable WHERE Period BETWEEN @X AND @Y
UNIONALLSELECT X, Y, Z FROM CatalogStatistics_940.dbo.StatisticsTable WHERE Period BETWEEN @X AND @Y
UNIONALLSELECT X, Y, Z FROM CatalogStatistics_1722.dbo.StatisticsTable WHERE Period BETWEEN @X AND @Y
...
My revelation
I remember going to my first SQL Server conference, attending an entry level internals session. Suddenly I knew what a page was, I knew, on a high level, how data was stored in SQL Server. Suddenly I understood the importance of the data being stored in a b-tree and how much it meant to my scalability concerns.
What I really like about this whole ordeal, when looking back at it, is how I didn’t attend a session on proper indexing. I didn’t attend a session about SQL Server limitations, how to store hundreds of millions of rows. Nope, I intended a session on the internals. Having just that basic knowledge of the internals suddenly provided me the necessary knowledge to figure it out myself. Maybe this is the real reason I’ve become slightly obsessed with internals ever since.
LOB types like varchar(MAX), nvarchar(MAX), varbinary(MAX) and xml suffer from split personality disorder. SQL Server may store values in-row or off-row depending on the size of the value, the available space in the record and the table settings. Because of this, it’s no easy task to predict the size of the pointer left in the record itself. You might even say… It depends.
Based on this post, and the fact that I’m working on LOB type support for OrcaMDF at the moment, I decided to look into the LOB pointer storage structures.
Setup
For testing, we’ll use a very simple schema:
CREATETABLE Lob
(
A char(5000) NULL,
B varchar(MAX) NOTNULL
)
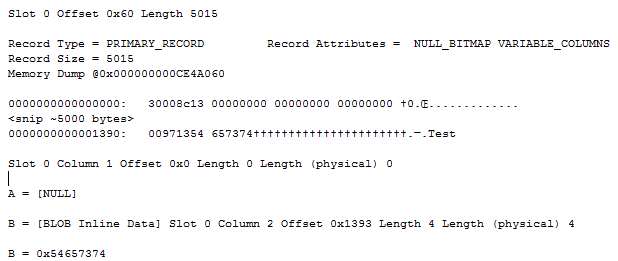
The [BLOB Inline Data] for in-row data
If data is small enough (“small enough” being hard to define as it depends on the free space in the page, the mood of SQL Server and probably a bunch of other undocumented factors), it will be stored in the record itself. Let’s insert a single small row:
INSERTINTO Lob (B) VALUES ('Test')
Since A takes up 5000 bytes and we only try to insert 4 bytes into B, there’s plenty of space for it to be stored in-row, taking up only the expected 4 bytes that we inserted. This behavior is just as a normal varchar(X) SLOB column would react.
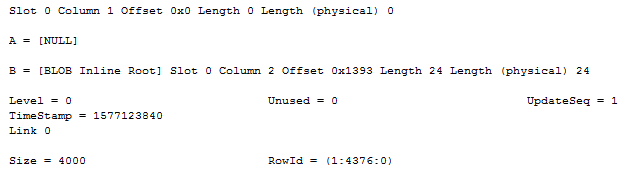
The [BLOB Inline Root] for row-overflow data
Now let’s truncate the table and insert a new row, forcing SQL Server to push the data off-row as there isn’t enough space on the original record:
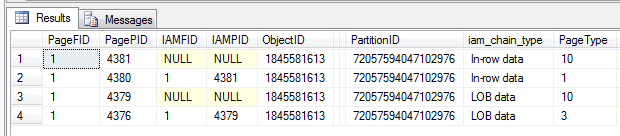
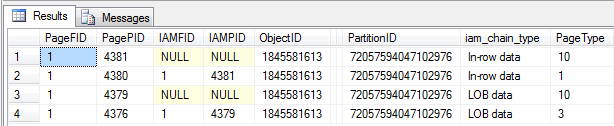
Since A once again takes up a fixed amount of 5000 bytes and we’re now trying to insert 4000 more bytes, we exceed the maximum capacity of 8096 bytes for the page body, causing SQL Server to push the data off-row. Running a DBCC IND confirms that SQL Server has allocated a new IAM page to track the LOB data pages:
DBCC IND (X, 'Lob', -1)
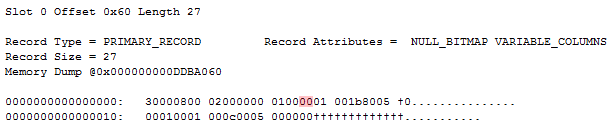
Extracting the record and looking at column 2 reveals that we’re now storing a 24 byte row-overflow pointer:
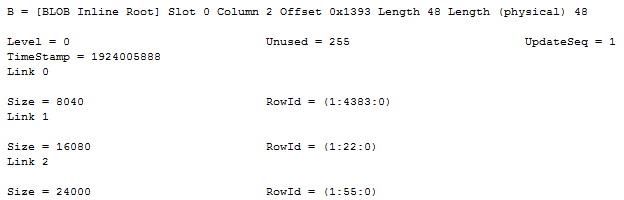
This pointer, once again, is exactly like a SLOB column would be stored. The (MAX) LOB variants do have one trick that SLOBs don’t have though – they can be longer than 8000 bytes. In that case, we need more than one page to store the value – and thus the off-row pointer needs to point at more than one page. The off-row pointer, at an abstract level, points to a root of pointers that then point onwards to the actual data pages (or onto another root in case we need more than two levels of page references). If the root is small enough, it’ll be stored in-row. The smallest root possible is 12 bytes – a single page reference (the extra 12 bytes is due to overhead). Each following page reference takes up an extra 12 bytes. Thus, an inline root pointing to two pages will take up 36 bytes of space, and so forth, just look at this:
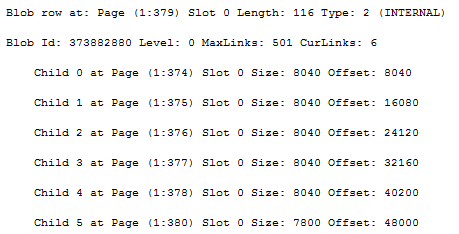
Note how we go from 24 to 36, 48, 60 and finally 72 bytes for a total of 40.000 bytes of data, stored on five data pages. Once we exceed 72 bytes, SQL Server doesn’t store the whole root inline any longer, instead if points to a single new slot on another page. The (1:379) page is a text_tree page, containing references to the pages where the data is stored:
I haven’t been able to make SQL Server store inline blob roots any larger than 72 bytes so I’m guessing that’s a hard cutoff value before it’ll start referencing text_tree pages. Ignoring text_tree pages, the pointer format so far has been exactly the same as for SLOBs. So when exactly does SQL Server store a classic 16 byte LOB pointer for (MAX) LOB types?
The [Textpointer] for LOB data
SQL Server will never store a LOB pointer for the (MAX) LOB types, unless the large value types out of row setting has been turned on. Let’s clear the table, set the setting, and then insert a new row like before:
TRUNCATETABLE LOB
EXEC sp_tableoption N'Lob', 'large value types out of row', 'ON'INSERTINTO Lob (B) VALUES (REPLICATE(CAST('a'ASvarchar(max)), 4000))
Now just as with the inline root, SQL Server allocates an IAM page to track the LOB data pages:
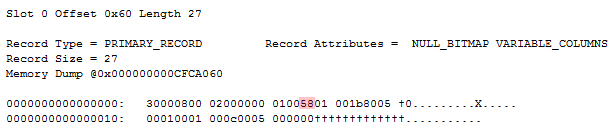
But when we look at the record stored on page (1:4380), we see that it stores a Textpointer instead of an inline blob root:
Mixed pointer types
As long as the large value types out of row setting is off (which it is by default), the (MAX) LOB types will act exactly like a SLOB column, except for the fact that the data can be larger than 8000 bytes. Once we turn the setting on, the (MAX) LOB types start acting like classic LOB types. So does this mean that the tables will always either use inline blob roots or textpointers? No, if only it were that simple. Take a look at this sample:
CREATETABLE TrickyLob
(
A varchar(MAX) NOTNULL
)
INSERTINTO TrickyLob VALUES ('Mark')
INSERTINTO TrickyLob VALUES (REPLICATE(CAST('a'ASvarchar(MAX)), 9000))
EXEC sp_tableoption N'TrickyLob', 'large value types out of row', 'ON'INSERTINTO TrickyLob VALUES (REPLICATE(CAST('a'ASvarchar(MAX)), 4000))
Running DBCC PAGE on the single allocated data page reveals that we now have three records using three different pointer types:
Lesson: When sp_tableoption is run to set the large value types out of row setting, it only takes effect for newly added records. A table rebuild won’t affect existing inline blob roots either, only updates to existing records will rebuild the record and convert the inline blob root to a textpointers.
Conclusion
Predicting the LOB pointer type & size can be tricky as it depends on multiple factors. Using the above, you should be able to get a notion of what will be stored, as well as to interpret the DBCC PAGE results you might run into.
While adding some extra sparse column tests to the OrcaMDF test suite, I discovered an bug in my parsing of records. While the problem was simple enough, it took me a while to debug. Running the test, it worked about 40% of the time while failing the remaining 60% of the time. As I hadn’t picked up on this pattern I happily fixed (or so I thought) the bug, ran my test and verified that it was working. Shortly after the test failed – without me having changed any code. After having the first few strains of hair turn grey, I noticed the pattern and subsequently fixed the bug.
The normal bitmap
Creating a table like the following results in a record with both a null bitmap and a variable length column for the sparse vector:
CREATETABLE Y (A int SPARSE, B intNULL)
INSERTINTO Y VALUES (5, 2)
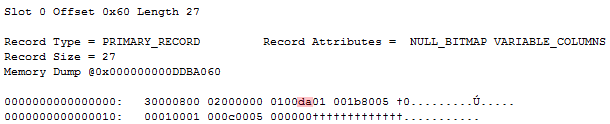
Outputting the lone record in the lone data pages yields the following:
The only thing of interest is the null bitmap. It has a value of 0, indicating that all columns are non null. The only column that actually uses the null bitmap is the B column. While the B column has a column index of 1, it’s represented by index 0 in the null bitmap, given that it’s the first column utilizing the null bitmap. Since the null bitmap has a value of 0x00, we know that the remaining (and unused) 7 bits all have a value of 0 – as would be expected.
The garbage bitmap
Now consider another schema, akin to the previous one:
CREATETABLE DifferingRecordFormats (A int SPARSE)
INSERTINTO DifferingRecordFormats VALUES (5)
ALTERTABLE DifferingRecordFormats ADD B intNULLUPDATE DifferingRecordFormats SET B = 2
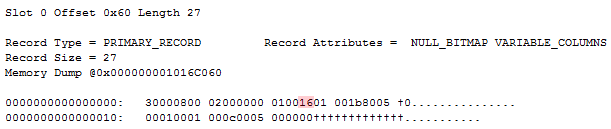
While ending up with the exact same table schema, values and record layout, the null bitmap differs. The following are three sample records, resulting from running the above script three times, dropping the table in between to start on a fresh:
Notice how all three records are exactly the same, except for the null bitmap. It’s even identical to the “The normal bitmap” record that I fixed showed, except for the null bitmap value. Let’s try and convert those three null bitmaps to binary:
All three bitmaps hold valid values for the bit we’re interested in – the very first (rightmost) bit. The remaining bits seem to be random garbage. While this doesn’t affect parsing as we’re not touching those spare bits, I find it interesting that the bitmap behaves differently depending on how it’s added. I’m guessing there’s an internal byte in memory that’s spilling through, having only the necessary bits flipped, instead of creating a new zeroed out byte and flipping bits as necessary on the clean byte.
Thou shalt not trust the null bitmap blindly!
Having garbage in the null bitmap raises some interesting questions. Usually when we add a nullable column to a schema, we don’t have to touch the data pages since we can determine the new columns data is not present in the record, hence it must be null. This is not done using the null bitmap however. Imagine this scenario:
CREATETABLE Garbage (A int sparse)
INSERTINTO Garbage VALUES (5)
ALTERTABLE Garbage ADD B intNULLUPDATE Garbage SET B = 2ALTERTABLE Garbage ADD E varchar(10)
We start out as before, causing a garbage null bitmap that might have a value of 0b01011000, meaning the third three columns are non-null – that is, B and E (since A is sparse and therefor doesn’t utilize the null bitmap). But E is null, even though the null bitmap says otherwise. This is the record as it may (given that the null bitmap value can vary) look after the above queries have been run:
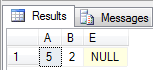
So according to the null bitmap, both B and E are null – doing a select confirms that that is not the case however:
So how do we determine that E is in fact null? By ignoring the null bitmap and realizing there’s no data for E. The column count for the record has a value of 1. It’s important to note that the column count counts the total number of non-sparse columns present in the record, including variable length. Since this has a value of 1 and there’s a fixed-length column present, that’s the one it’s counting. While there’s also a variable length column, that’s the sparse vector – identified by the fact that the column count didn’t include it, and that the variable length offset array entry identifies it as a complex column.
Conclusion
I’m having somefun causing all kinds of edge cases due to sparse columns, even more fun trying to reason why what’s happening is happening. I haven’t seen garbage bitmaps before working with sparse columns and causing the specific scenario where the bitmap is added to a data record that doesn’t already have one. The most important thing to realize is that it doesn’t matter, at all. When doing reads of a record, the first thing we should check is not the null bitmap, but whether to expect the column in the record and afterwards whether there is a null bitmap at all (it may not be present in these sparse scenarios, as well as for index records).
Below is a pseudo code presentation of how I’m currently parsing records, passing all current tests. Note that it’s leaving out a lot of details, but the overall logic follows the actual implementation. Also note that I’m continually updating this as I discover new edge cases that I haven’t taken into account.
foreach column in schema {
if(sparse) {
if(record has sparse vector) {
Value = [Read value from sparse vector, possibly NULL]
} else {
Value = NULL
}
} else {
if(non-sparse column index < record.NumberOfColumns) {
if(record does not have a null bitmap OR null bitmap indicates non NULL) {
if(column is variable length) {
Value = [Read value from variable length data section]
} else {
Value = [Read value from fixed length data section]
}
} else {
Value = NULL
}
} else {
Value = NULL
}
}
}
Warning: this is a select is (most likely) not broken, it’s just not working as I’d expect. It may very well be that I’m just overlooking something, in which case I hope someone will correct me :)
CREATETABLE ScanAllNullSparse
(
A int SPARSE,
B int SPARSE
)
INSERTINTO ScanAllNullSparse DEFAULTVALUES
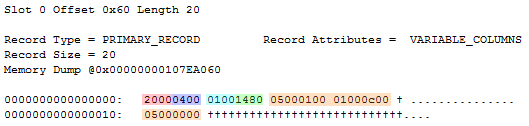
Dumping out the resulting record yields the following:
And this is where things start to get weird. The status bits (red) are all off, meaning there’s neither a null bitmap nor variable length columns in this record. The next two (blue) bytes indicate the end offset of the fixed length portion – right after those two very bytes, since we don’t have any fixed length data.
At this point I’m not too sure what to expect next – after all, in the previous blog post I showed how the column count wasn’t stored in all-sparse tables. Also, the status bits indicate that there’s no null bitmap. But what is the green 0x0100 (decimal value 1) bytes then? The only value I can see them possible indicating is the number of variable length columns. But why would that be present when the status bits indicate there are no such columns? Oh well, if that’s the case, then the next two (pink) bytes must be the offset array entry for the variable length column – having a value of 8 indicates that the variable length column has no value.
But wait, if the variable length column doesn’t have a value, then what is that last (orange/brownish) 0x00 byte doing at the very end? That’s beyond the offset marked in the (assumedly) variable length offset array… And if the pink bytes really is the variable length offset array – should it not indicate a complex column for the sparse vector? (though it would make sense for it not to do so, if it weren’t stored in the record).
I can still parse this by just taking some precautions, but I still don’t understand what’s going on. Any suggestions?
It’s not just DBCC PAGE
To clear DBCC PAGE of any suspicion I amended my original test by inserting two extra rows with DEFAULT VALUES. The resulting offset table looks like this:
As can be seen, the storage engine allocates 9 bytes for all three rows (though we can only verify the first two). Thus it’s not just DBCC PAGE that reads the records as being 9 bytes, so does the storage engine. This just strengthens the case that SQL Server knows best, now if only I could figure out why :)
During my testing I discovered that tables containing only sparse columns neither stored a null bitmap, nor the usual number of columns. Let’s create a test table and find a reference to the data page:
CREATETABLE OnlyFixedSparse (A int SPARSE)
INSERTINTO OnlyFixedSparse VALUES (5)
DBCC IND (X, 'OnlyFixedSparse', -1)
And then let’s check the record contents for page (1:4359):
DBCC PAGE (X, 1, 4359, 3)
The first two bytes contain the record status bits. Next two bytes contain the offset for the end of the fixed-length portion of the record – which is 4 as expected, since we have no non-sparse fixed-length columns. As shown in the Record Attributes output, the status bytes indicates that there’s no null bitmap, and sure enough, the next two bytes indicates the number of variable length columns. The remaining bytes contains the variable length offset array as well as the sparse vector.
Under what conditions does the data record not contain a null bitmap?
I did a quick empirical test to verify my theory that this only happens on tables containing only sparse columns:
Schema
Contains null bitmap
Only variable length columns
Yes
Only fixed length columns
Yes
Only sparse fixed length columns
No
Only sparse variable length columns
No
Fixed length + sparse fixed length columns
Yes
Variable length + sparse fixed length columns
Yes
Thus it would seem that this is an optimization made possible for tables containing nothing but sparse columns.
There’s always an exception to the exception
It is actually possible to have a data record without a null bitmap for a table with non-sparse columns too. Continuing on from the OnlyFixedSparse table from before, let’s add two extra nullable columns:
ALTERTABLE OnlyFixedSparse ADD B intNULLAlterTable OnlyFixedSparse ADD C varchar(10) NULL
Checking the stored record reveals the exact same output as before:
Thus it would seem that even without a null bitmap the usual alter semantics are followed – the addition of new nullable columns does not need to alter existing records. If we’d added a non-nullable column to the table, we would have to modify the record, causing the addition of a null bitmap and column count. The same goes if we insert a value into any of those new columns:
UPDATE OnlyFixedSparse SET B = 2
By setting the value of the B column we just added 7 extra bytes to our data record. 4 for the integer, 2 for the column count and 1 for the null bitmap. Had we not performed the update for all records in the table, only the affected records would be updated. This means we may have data records for a table where some have a null bitmap while others don’t. Just take a look at this:
CREATETABLE OnlyFixedSparse (A int SPARSE)
INSERTINTO OnlyFixedSparse VALUES (5), (6)
ALTERTABLE OnlyFixedSparse ADD B intNULLUPDATE OnlyFixedSparse SET B = 2WHERE A = 5
Conclusion
As I unfortunately do not work on the SQL Server team and I haven’t seen this condition documented, I can only theorize on this. For all normal data records, the null bitmap is always present, even if the table does not contain any null columns. While we can achieve read optimizations when columns may be null, for completely non-null tables, we still get the benefit that we can add a new nullable column to an existing schema, without having to modify the already existing records.
While I think it’s bit of a special use case, my theory is that this is a specific optimization made for the case where you have a table with lots of sparse columns and no non-sparse columns present. For those cases, we save at least three bytes – two for the number of columns and at least one for the null bitmap. If there are only sparse columns, we have no need for the null bitmap as the null value is defined by the value not being stored in the sparse vector.
In this post I’ll be looking at the internal storage mechanism that supports sparse columns. For an introduction to what sparse columns are and when they ought to be used, take a look here.
Sparse columns, whether fixed or variable length, or not stored together with the normal columns in a record. Instead, they’re all stored in a hidden variable length column at the very end of the record (barring the potential 14 byte structure that may be stored when using versioning).
Creating and finding a sparse vector
Let’s create a sample table and insert a couple of test rows:
CREATETABLE Sparse
(
ID int,
A int SPARSE,
B int SPARSE,
C int SPARSE,
D int SPARSE,
E int SPARSE
)
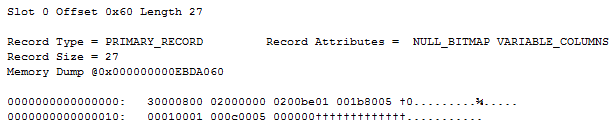
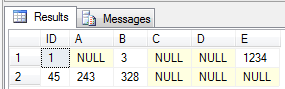
INSERTINTO Sparse (ID, B, E) VALUES (1, 3, 1234)
INSERTINTO Sparse (ID, A, B) VALUES (45, 243, 328)
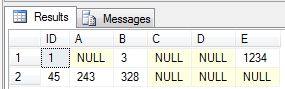
As you’d expect, a SELECT * yields the following result:
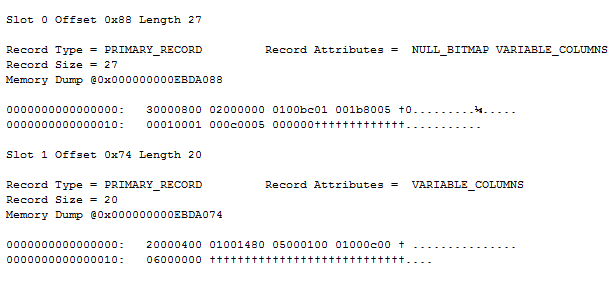
Now let’s use DBCC IND to find the lone data pages ID, and then check out the stored record using DBCC PAGE:
DBCC IND (X, 'Sparse', -1)
DBCC PAGE (X, 1, 4328, 3)
This gives us two records, the first one looking like this:
In a previous post I detailed how we identify complex columns like sparse vectors, so I won’t go into too much detail there. The two red bytes is the single entry in the variable length offset array, with a value of 0x8023 = 32.803. Once we flip the high order bit (identifying this column as a complex column) we get an offset value of 35. Thus we know that the remaining 20 bytes in the record is our sparse vector.
The sparse vector structure
So what do those 20 bytes contain? The sparse vector structure looks like this:
Name
Bytes
Description
Complex column header
2
The header identifies the type of complex column that we’re dealing with. A value of 5 denotes a sparse vector.
Sparse column count
2
Number of sparse column values that are stored in the vector – only columns that have values are included in the vector.
Column ID set
2 Number of sparse columns with values
Each sparse column storing a value will use two bytes to store the ID of the column (as seen in sys.columns).
Column offset table
2 Number of sparse columns with values
Just like the record variable offset array, this stores two bytes per sparse column with a value. The value denotes the end of the actual value in the sparse vector.
Sparse data
Total length of all sparse column data values.
It’s interesting to note that unlike the normal record structure, fixed length and variable length sparse columns are stored in exactly the same way – both have an entry in the offset table, even though the fixed length values don’t differ in length.
Looking at a record
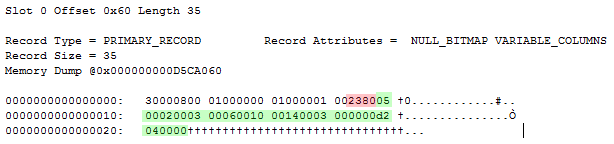
Going back to our record structure, I’ve colored it according to separate the different parts of the vector:
0x05000200030006001000140003000000d2040000
Note that I’ve byte swapped the following byte references.
The first two bytes 0x0005 == 5 contains the complex column ID.
The next two bytes 0x0002 == 2 contains the number of sparse columns that are non-null, that is, they have a value stored in the sparse vector.
The purple part stores two bytes per column, namely the column IDs of the stored columns. 0x0003 == 3, 0x0006 == 6.
Next up we have the green part – again storing two bytes per column, this time the offsets in the sparse vector. 0x0010 == 16, 0x0014 == 20.
Finally we have the values themselves. We know that the first column has an ID of 3 and it’s data ends et offset 16. Since the first 12 bytes are made up of the header, the actual values are stored in bytes 13-16: 0x00000003 == 3. The second value ends at offset 20, meaning it’s stored in bytes 17-20: 0x000004d2 == 1.234.
Correlating sparse vector values with sys.columns
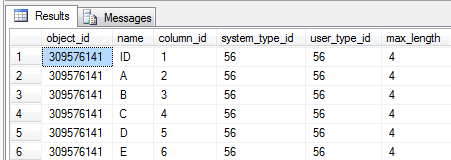
Now that we have the values, we just need to correlate them with the columns whose value they store. Let’s select the columns in our Sparse table:
SELECT
*
FROM
sys.columns
WHERE
object_id = OBJECT_ID('Sparse')
And there we have it – the value 3 was stored in column_id = 3 => B. The value 1.234 was stored in column_id = 6 => E. Coincidentally, that matches up with our originally select query:
The same procedure can be repeated for the second record, but I’m going to leave that as an exercise for the reader :)
Writing a sparse vector parser in C
Once we know the structure of the sparse vector, writing a parser in C# is surprisingly simple:
using System;
using System.Collections.Generic;
using System.Linq;
namespace OrcaMDF.Core.Engine
{
///<summary>/// Parses sparse vectors as stored in records for tables containing sparse columns.///</summary>publicclass SparseVectorParser
{
publicshort ColumnCount { get; privateset; }
public IDictionary<short, byte[]> ColumnValues { get; privateset; }
publicSparseVectorParser(byte[] bytes)
{
// First two bytes must have the value 5, indicating this is a sparse vectorshort complexColumnID = BitConverter.ToInt16(bytes, 0);
if (complexColumnID != 5)
thrownew ArgumentException("Input bytes does not contain a sparse vector.");
// Number of columns contained in this sparse vector
ColumnCount = BitConverter.ToInt16(bytes, 2);
// For each column, read the data into the columnValues dictionary
ColumnValues = new Dictionary<short, byte[]>();
short columnIDSetOffset = 4;
short columnOffsetTableOffset = (short)(columnIDSetOffset + 2 * ColumnCount);
short columnDataOffset = (short)(columnOffsetTableOffset + 2 * ColumnCount);
for(int i=0; i<ColumnCount; i++)
{
// Read ID, data offset and data from vectorshort columnID = BitConverter.ToInt16(bytes, columnIDSetOffset);
short columnOffset = BitConverter.ToInt16(bytes, columnOffsetTableOffset);
byte[] data = bytes.Take(columnOffset).Skip(columnDataOffset).ToArray();
// Add ID + data to dictionary
ColumnValues.Add(columnID, data);
// Increment both ID and offset offsets by two bytes
columnIDSetOffset += 2;
columnOffsetTableOffset += 2;
columnDataOffset = columnOffset;
}
}
}
}
I won’t go into the code as it’s documented and follows the procedure we just went through. A quick test verifies that it achieves the same results as we just did by hand:
For an introduction to the anatomy of records, I suggest you read this post by Paul Randal.
Not all variable length columns are the same. Some are more… Complex than others. An example of a complex column could be the 24 byte row-overflow pointer that are used when SLOB types overflow. Kalen Delaney has an excellent post detailing how to detect overflowing columns. There are more than one complex column type though, and the technique outlined in Kalen’s post can be generalized a bit further.
Complex columns containing row-overflow pointers
Technically I don’t this is a complex column as it doesn’t follow the normal format. It is however identified the same way, so I’ll treat it as a complex column in this post. Let’s create a simple table, cause one of the columns to overflow and then check the record contents:
CREATETABLE OverflowTest (A varchar(8000), B varchar(8000))
INSERTINTO OverflowTest VALUES (REPLICATE('a', 5000), REPLICATE('b', 5000))
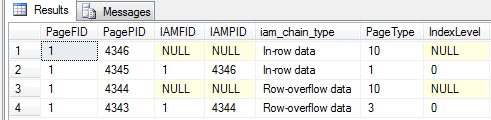
DBCC IND (X, OverflowTest, -1)
Outputting the contents of page (1:4345) shows the following (cropped to only show the first 36 bytes of the lone record body:
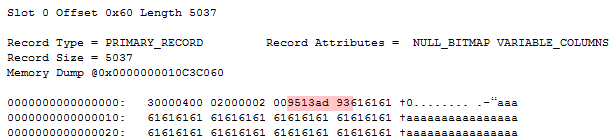
The four colored bytes make up the variable length offset array – two bytes for each offset. The first offset has a value of 0x1395 == 5013, which fits perfectly with there being 5000 characters in the first column, plus 13 for the record overhead. The second offset has a value of 0x93AD == 37.805. Converted to binary that’s a value of 0b1001001110101101. Note how the high order bit is set to 1 – indicating a complex column. Getting the actual offset requires us to mask out the high order bit like so: 0n37805 & 0b011111111111111 == 5.037. Now we can easily calculate the complex column length as being 5.037 – 5.013 == 24 bytes.
At this point we know that the column contains a complex column and we know that it’s 24 bytes long. Row-overflow pointers only use a single byte to identify the type of complex column – this is what distinguishes it from “normal” complex columns, hence why I’m reluctant to call it a complex column.
The very first byte determines the type of complex column that this is. For row-overflow/LOB pointers this can either be 1, indicating a LOB pointer, or 2, indicating a row-overflow pointer. In this case the value is 2, which confirms that we’re looking at a row-overflow pointer.
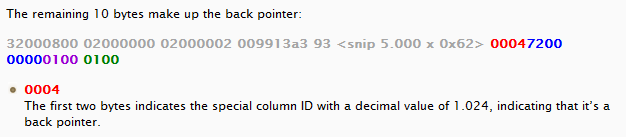
Complex columns containing forwarded record back pointers
All complex columns use the first two bytes to identify the kind of complex columns. In this case a complex column ID of 1.024 indicates a back pointer.
Complex columns containing sparse vectors
Let’s create a simple table containing some sparse columns:
CREATETABLE Sparse
(
ID int,
A int SPARSE,
B int SPARSE,
C int SPARSE,
D int SPARSE,
E int SPARSE
)
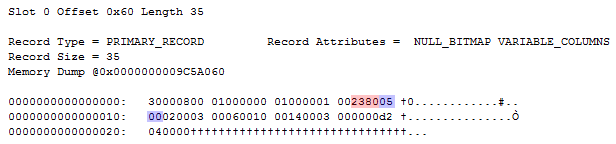
Taking a look at a dump of a record looks like this:
Note that there are no variable length columns in the table definition. However, the sparse vector is stored as a variable length field, thus we have a variable length offset array. The red bytes make up the offset array value of 0x8023 = 32.803. Flipping the high order bit yields a value of 35, indicating that all remaining bytes in the record belong to the sparse vector.
Since the high order bit was flipped, we know that this is a complex column. Checking out the first two bytes (marked with blue) yields a value of 0x0005. A value of 5 is exactly what indicates that we’re dealing with a sparse vector.
Conclusion
In general, variable length columns that contain some kind of special data will be indicated by having their high order bit flipped in the variable length offset array. While row-overflow pointers are not technically complex columns, that act similarly, except only using a single byte to indicate the column type.
Forwarded record back pointers are stored in complex columns having a complex column ID of 1.024.
Sparse vectors use a complex column ID of 5.
I do not know of any more complex columns as of yet, but the documentation is rather non existent except for what’s mentioned in the SQL Server 2008 Internals book.
Based on my findings exploring the sys.system_internals_partition_columns.ti field, I needed parser that could extract the scale, precision, max_length as well as the max_inrow_length fields from it. The tricky part is that those values are stored differently for each individual type, added onto the fact that some types have hardcoded defaults that are not stored in the ti field, even though there’s space for it.
As a result of some reverse engineering and empirical testing, I’ve made a SysrscolTIParser class that takes in the ti value (I have no idea what the acronym stands for – type information perhaps?), determines the type and parses it corresponding to the type. I won’t go into details as that’s all described in my previous post.
And last, but not least, a bunch of tests to verify the functionality:
using NUnit.Framework;
using OrcaMDF.Core.MetaData;
namespace OrcaMDF.Core.Tests.MetaData
{
[TestFixture]
publicclass SysrscolTIParserTests
{
[Test]
publicvoidBigint()
{
var parser = new SysrscolTIParser(127);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(19, parser.Precision);
Assert.AreEqual(8, parser.MaxLength);
Assert.AreEqual(127, parser.TypeID);
Assert.AreEqual(8, parser.MaxInrowLength);
}
[Test]
publicvoidBinary()
{
var parser = new SysrscolTIParser(12973);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(50, parser.MaxLength);
Assert.AreEqual(173, parser.TypeID);
Assert.AreEqual(50, parser.MaxInrowLength);
}
[Test]
publicvoidBit()
{
var parser = new SysrscolTIParser(104);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(1, parser.Precision);
Assert.AreEqual(1, parser.MaxLength);
Assert.AreEqual(104, parser.TypeID);
Assert.AreEqual(1, parser.MaxInrowLength);
}
[Test]
publicvoidChar()
{
var parser = new SysrscolTIParser(2735);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(10, parser.MaxLength);
Assert.AreEqual(175, parser.TypeID);
Assert.AreEqual(10, parser.MaxInrowLength);
}
[Test]
publicvoidDate()
{
var parser = new SysrscolTIParser(40);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(10, parser.Precision);
Assert.AreEqual(3, parser.MaxLength);
Assert.AreEqual(40, parser.TypeID);
Assert.AreEqual(3, parser.MaxInrowLength);
}
[Test]
publicvoidDatetime()
{
var parser = new SysrscolTIParser(61);
Assert.AreEqual(3, parser.Scale);
Assert.AreEqual(23, parser.Precision);
Assert.AreEqual(8, parser.MaxLength);
Assert.AreEqual(61, parser.TypeID);
Assert.AreEqual(8, parser.MaxInrowLength);
}
[Test]
publicvoidDatetime2()
{
var parser = new SysrscolTIParser(1834);
Assert.AreEqual(7, parser.Scale);
Assert.AreEqual(27, parser.Precision);
Assert.AreEqual(8, parser.MaxLength);
Assert.AreEqual(42, parser.TypeID);
Assert.AreEqual(8, parser.MaxInrowLength);
parser = new SysrscolTIParser(810);
Assert.AreEqual(3, parser.Scale);
Assert.AreEqual(23, parser.Precision);
Assert.AreEqual(7, parser.MaxLength);
Assert.AreEqual(42, parser.TypeID);
Assert.AreEqual(7, parser.MaxInrowLength);
}
[Test]
publicvoidDatetimeoffset()
{
var parser = new SysrscolTIParser(1835);
Assert.AreEqual(7, parser.Scale);
Assert.AreEqual(34, parser.Precision);
Assert.AreEqual(10, parser.MaxLength);
Assert.AreEqual(43, parser.TypeID);
Assert.AreEqual(10, parser.MaxInrowLength);
parser = new SysrscolTIParser(1067);
Assert.AreEqual(4, parser.Scale);
Assert.AreEqual(31, parser.Precision);
Assert.AreEqual(9, parser.MaxLength);
Assert.AreEqual(43, parser.TypeID);
Assert.AreEqual(9, parser.MaxInrowLength);
}
[Test]
publicvoidDecimal()
{
var parser = new SysrscolTIParser(330858);
Assert.AreEqual(5, parser.Scale);
Assert.AreEqual(12, parser.Precision);
Assert.AreEqual(9, parser.MaxLength);
Assert.AreEqual(106, parser.TypeID);
Assert.AreEqual(9, parser.MaxInrowLength);
parser = new SysrscolTIParser(396138);
Assert.AreEqual(6, parser.Scale);
Assert.AreEqual(11, parser.Precision);
Assert.AreEqual(9, parser.MaxLength);
Assert.AreEqual(106, parser.TypeID);
Assert.AreEqual(9, parser.MaxInrowLength);
}
[Test]
publicvoidFloat()
{
var parser = new SysrscolTIParser(62);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(53, parser.Precision);
Assert.AreEqual(8, parser.MaxLength);
Assert.AreEqual(62, parser.TypeID);
Assert.AreEqual(8, parser.MaxInrowLength);
}
[Test]
publicvoidVarbinary()
{
var parser = new SysrscolTIParser(165);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(-1, parser.MaxLength);
Assert.AreEqual(165, parser.TypeID);
Assert.AreEqual(8000, parser.MaxInrowLength);
parser = new SysrscolTIParser(228517);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(892, parser.MaxLength);
Assert.AreEqual(165, parser.TypeID);
Assert.AreEqual(892, parser.MaxInrowLength);
}
[Test]
publicvoidImage()
{
var parser = new SysrscolTIParser(4130);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(16, parser.MaxLength);
Assert.AreEqual(34, parser.TypeID);
Assert.AreEqual(16, parser.MaxInrowLength);
}
[Test]
publicvoidInt()
{
var parser = new SysrscolTIParser(56);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(10, parser.Precision);
Assert.AreEqual(4, parser.MaxLength);
Assert.AreEqual(56, parser.TypeID);
Assert.AreEqual(4, parser.MaxInrowLength);
}
[Test]
publicvoidMoney()
{
var parser = new SysrscolTIParser(60);
Assert.AreEqual(4, parser.Scale);
Assert.AreEqual(19, parser.Precision);
Assert.AreEqual(8, parser.MaxLength);
Assert.AreEqual(60, parser.TypeID);
Assert.AreEqual(8, parser.MaxInrowLength);
}
[Test]
publicvoidNchar()
{
var parser = new SysrscolTIParser(5359);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(20, parser.MaxLength);
Assert.AreEqual(239, parser.TypeID);
Assert.AreEqual(20, parser.MaxInrowLength);
}
[Test]
publicvoidNtext()
{
var parser = new SysrscolTIParser(4195);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(16, parser.MaxLength);
Assert.AreEqual(99, parser.TypeID);
Assert.AreEqual(16, parser.MaxInrowLength);
}
[Test]
publicvoidNumeric()
{
var parser = new SysrscolTIParser(265580);
Assert.AreEqual(4, parser.Scale);
Assert.AreEqual(13, parser.Precision);
Assert.AreEqual(9, parser.MaxLength);
Assert.AreEqual(108, parser.TypeID);
Assert.AreEqual(9, parser.MaxInrowLength);
parser = new SysrscolTIParser(135020);
Assert.AreEqual(2, parser.Scale);
Assert.AreEqual(15, parser.Precision);
Assert.AreEqual(9, parser.MaxLength);
Assert.AreEqual(108, parser.TypeID);
Assert.AreEqual(9, parser.MaxInrowLength);
}
[Test]
publicvoidNvarchar()
{
var parser = new SysrscolTIParser(25831);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(100, parser.MaxLength);
Assert.AreEqual(231, parser.TypeID);
Assert.AreEqual(100, parser.MaxInrowLength);
parser = new SysrscolTIParser(231);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(-1, parser.MaxLength);
Assert.AreEqual(231, parser.TypeID);
Assert.AreEqual(8000, parser.MaxInrowLength);
}
[Test]
publicvoidReal()
{
var parser = new SysrscolTIParser(59);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(24, parser.Precision);
Assert.AreEqual(4, parser.MaxLength);
Assert.AreEqual(59, parser.TypeID);
Assert.AreEqual(4, parser.MaxInrowLength);
}
[Test]
publicvoidSmalldatetime()
{
var parser = new SysrscolTIParser(58);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(16, parser.Precision);
Assert.AreEqual(4, parser.MaxLength);
Assert.AreEqual(58, parser.TypeID);
Assert.AreEqual(4, parser.MaxInrowLength);
}
[Test]
publicvoidSmallint()
{
var parser = new SysrscolTIParser(52);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(5, parser.Precision);
Assert.AreEqual(2, parser.MaxLength);
Assert.AreEqual(52, parser.TypeID);
Assert.AreEqual(2, parser.MaxInrowLength);
}
[Test]
publicvoidSmallmoney()
{
var parser = new SysrscolTIParser(122);
Assert.AreEqual(4, parser.Scale);
Assert.AreEqual(10, parser.Precision);
Assert.AreEqual(4, parser.MaxLength);
Assert.AreEqual(122, parser.TypeID);
Assert.AreEqual(4, parser.MaxInrowLength);
}
[Test]
publicvoidSql_Variant()
{
var parser = new SysrscolTIParser(98);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(8016, parser.MaxLength);
Assert.AreEqual(98, parser.TypeID);
Assert.AreEqual(8016, parser.MaxInrowLength);
}
[Test]
publicvoidText()
{
var parser = new SysrscolTIParser(4131);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(16, parser.MaxLength);
Assert.AreEqual(35, parser.TypeID);
Assert.AreEqual(16, parser.MaxInrowLength);
}
[Test]
publicvoidTime()
{
var parser = new SysrscolTIParser(1833);
Assert.AreEqual(7, parser.Scale);
Assert.AreEqual(16, parser.Precision);
Assert.AreEqual(5, parser.MaxLength);
Assert.AreEqual(41, parser.TypeID);
Assert.AreEqual(5, parser.MaxInrowLength);
parser = new SysrscolTIParser(1065);
Assert.AreEqual(4, parser.Scale);
Assert.AreEqual(13, parser.Precision);
Assert.AreEqual(4, parser.MaxLength);
Assert.AreEqual(41, parser.TypeID);
Assert.AreEqual(4, parser.MaxInrowLength);
}
[Test]
publicvoidTimestamp()
{
var parser = new SysrscolTIParser(189);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(8, parser.MaxLength);
Assert.AreEqual(189, parser.TypeID);
Assert.AreEqual(8, parser.MaxInrowLength);
}
[Test]
publicvoidTinyint()
{
var parser = new SysrscolTIParser(48);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(3, parser.Precision);
Assert.AreEqual(1, parser.MaxLength);
Assert.AreEqual(48, parser.TypeID);
Assert.AreEqual(1, parser.MaxInrowLength);
}
[Test]
publicvoidUniqueidentifier()
{
var parser = new SysrscolTIParser(36);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(16, parser.MaxLength);
Assert.AreEqual(36, parser.TypeID);
Assert.AreEqual(16, parser.MaxInrowLength);
}
[Test]
publicvoidVarchar()
{
var parser = new SysrscolTIParser(12967);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(50, parser.MaxLength);
Assert.AreEqual(167, parser.TypeID);
Assert.AreEqual(50, parser.MaxInrowLength);
parser = new SysrscolTIParser(167);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(-1, parser.MaxLength);
Assert.AreEqual(167, parser.TypeID);
Assert.AreEqual(8000, parser.MaxInrowLength);
}
[Test]
publicvoidXml()
{
var parser = new SysrscolTIParser(241);
Assert.AreEqual(0, parser.Scale);
Assert.AreEqual(0, parser.Precision);
Assert.AreEqual(-1, parser.MaxLength);
Assert.AreEqual(241, parser.TypeID);
Assert.AreEqual(8000, parser.MaxInrowLength);
}
}
}
All of this is just one big giant bit of infrastructure I needed to implement to get my scanning of nonclustered indexes working. As soon as I’ve got that up and running, all of this, plus a lot more, will be committed & pushed to the OrcaMDF repo.
Running sp_helptext on the sys.system_internals_partition_columns system view reveals the following internal query:
SELECT
c.rsid AS partition_id,
c.rscolid AS partition_column_id,
c.rcmodified AS modified_count,
CASE c.maxinrowlen
WHEN0THEN p.length
ELSE c.maxinrowlen
ENDAS max_inrow_length,
CONVERT(BIT, c.status & 1) AS is_replicated, --RSC_REPLICATED
CONVERT(BIT, c.status & 4) AS is_logged_for_replication, --RSC_LOG_FOR_REPL
CONVERT(BIT, c.status & 2) AS is_dropped, --RSC_DROPPED
p.xtype AS system_type_id,
p.length AS max_length,
p.prec ASPRECISION,
p.scale AS scale,
CONVERT(sysname, CollationPropertyFromId(c.cid, 'name')) AS collation_name,
CONVERT(BIT, c.status & 32) AS is_filestream, --RSC_FILESTREAM
c.ordkey AS key_ordinal,
CONVERT(BIT, 1 - (c.status & 128)/128) AS is_nullable, -- RSC_NOTNULL
CONVERT(BIT, c.status & 8) AS is_descending_key, --RSC_DESC_KEY
CONVERT(BIT, c.status & 16) AS is_uniqueifier, --RSC_UNIQUIFIER
CONVERT(SMALLINT, CONVERT(BINARY(2), c.offset & 0xffff)) AS leaf_offset,
CONVERT(SMALLINT, SUBSTRING(CONVERT(BINARY(4), c.offset), 1, 2)) AS internal_offset,
CONVERT(TINYINT, c.bitpos & 0xff) AS leaf_bit_position,
CONVERT(TINYINT, c.bitpos/0x100) AS internal_bit_position,
CONVERT(SMALLINT, CONVERT(BINARY(2), c.nullbit & 0xffff)) AS leaf_null_bit,
CONVERT(SMALLINT, SUBSTRING(CONVERT(BINARY(4), c.nullbit), 1, 2)) AS internal_null_bit,
CONVERT(BIT, c.status & 64) AS is_anti_matter, --RSC_ANTIMATTER
CONVERT(UNIQUEIDENTIFIER, c.colguid) AS partition_column_guid,
sysconv(BIT, c.status & 0x00000100) AS is_sparse --RSC_SPARSE
FROM
sys.sysrscols c
OUTER APPLY
OPENROWSET(TABLE RSCPROP, c.ti) p
Nothing too out of the ordinary if you’ve looked at other internal queries. There’s a lot of bitmasking / shifting going on to extract multiple values from the same internal base table fields. One thing that is somewhat convoluted is the OPENROWSET(TABLE RSCPROP, c.ti) p OUTER APPLY being made.
A Google query for “sql server +rscprop” yields absolutely zilch results:
Simplifying the query to only show the fields using the fields referring the OPENROWSET (p) results, shows that the scale, precision, max_length, system_type_id and max_inrow_length are either extracted from the ti field value directly or indirectly:
SELECTCASE c.maxinrowlen
WHEN0THEN p.length
ELSE c.maxinrowlen
ENDAS max_inrow_length,
p.xtype AS system_type_id,
p.length AS max_length,
p.prec ASPRECISION,
p.scale AS scale,
FROM
sys.sysrscols c
OUTER APPLY
OPENROWSET(TABLE RSCPROP, c.ti) p
To help me identifying the ti field structure, I’ve made a test table using a number of different column types:
CREATETABLE TITest
(
A binary(50),
B char(10),
C datetime2(5),
D decimal(12, 5),
E float,
F int,
G numeric(11, 4),
H nvarchar(50),
I nvarchar(max),
J time(3),
K tinyint,
L varbinary(max),
M varchar(75),
N text
)
I’m not going to insert any data as that’s irrelevant for this purpose. For this next part, make sure you’re connected to the SQL Server using the Dedicated Administrator Connection. Now let’s query the sysrscols base table to see what values are stored in the ti field for the sample fields we’ve just created:
-- Get object id of TITest tableSELECT * FROM sys.sysschobjs WHERE name = 'TITest'
-- Get rowset id for TITest
SELECT * FROM sys.sysrowsets WHERE idmajor = 213575799
-- Getall columns for rowset
SELECT * FROM sys.sysrscols WHERE rsid = 72057594040614912
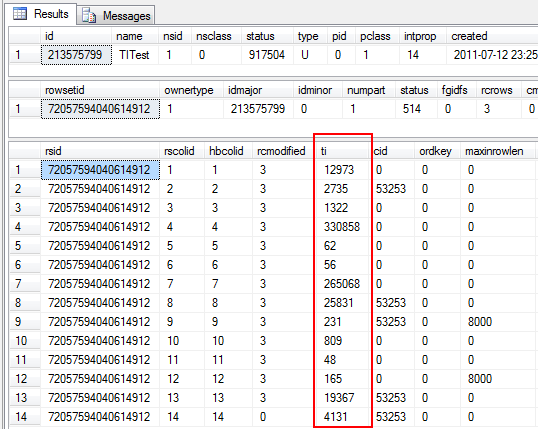
Besides the fact I’ve cut away some irrelevant columns, this is the result:
Note how we first get the object ID by querying sysschobjs, then the partition ID by querying sysrowsets and finally the partition columns by querying sysrscols. The marked ti column are the values from which we shall extract the scale, precision, max_length, system_type_id and max_inrow_length values.
The following query will give a better row-by-row comparison between the ti value and the expected end result field values:
SELECT
t.name,
r.ti,
p.scale,
p.precision,
p.max_length,
p.system_type_id,
p.max_inrow_length
FROM
sys.system_internals_partition_columns p
INNERJOIN
sys.sysrscols r ON
r.rscolid = p.partition_column_id AND
r.rsid = p.partition_id
INNERJOIN
sys.types t ON
t.system_type_id = p.system_type_id AND
t.user_type_id = p.system_type_id
WHERE
partition_id = 72057594040614912
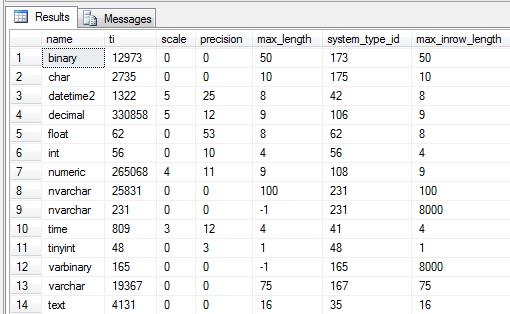
binary
Converting the first system_type_id into hex yields 0n173 = 0xAD. Converting the ti value yields 0n12973 = 0x32AD. An empirical test for all columns shows this to be true for them all. Thus we can conclude that the first byte (printed as the rightmost due to little endianness) stores the type. Extracting the value requires a simple bitmask operation:
12973 & 0x000000FF == 173
As for the length, the second byte stores the value 0x32 = 0n50. As the length is a smallint (we know it can be up to 8000, thus requiring at least a smallint), we can assume the next two bytes cover that. To extract that value, we’ll need a bitmask, as well as a shift operation to shift the two middlemost bytes one step to the right:
(12973 & 0x00FFFF00) >> 8 == 50
datetime2
This is the same for the char field. The datetime2 field is different as it stores the scale and precision values. 0n1322 in hex yields a value of 0x52A. 0x2A being the type (42). All that remains is the 0x5/0n5 which can only be the scale. A quick with a datetime(7) field yields the same result, though the precision is then 27. Thus I’ll conclude that for the datetime2 type, precision = 20 + scale. Extracting the scale from the second byte requires almost the same operation as before, just with a different bitmask:
(1322 & 0x0000FF00) >> 8 == 5
decimal
Moving onto decimal, we now have both a scale and a precision to take care of. Converting 0n330858 to hex yields a value of 0x50C6A. 0x6A being the type (106). 0x0C being the precision and finally 0x5 being the scale. Note that this is different from datetime2 – now the scale is stored as the third byte and not the second!
Extracting the third byte as the scale requires a similar bitmask & shift operation as previously:
(330858 & 0x00FF0000) >> 16 == 5
float
0n62 = 0x3E => the system_type_id value of 62. Thus the only value stored for the float is the type ID, the rest are a given. The same goes for the int, tinyint and similar fixed length field types.
numeric
0n265068 = 0x40B6C. 0x6C = the type ID of 108. 0xB = the precision value of 11. 0x4 = the scale value of 4.
nvarchar & nvarchar(max)
These are a bit special too. Looking at the first nvarchar(100) field we can convert 0n25832 to 0x64E7. 0xE7 being the type ID of 231. 0x64 being the length of 100, stored as a two byte smallint. This shows that the parsing of non-max (n)varchar fields is pretty much in line with the rest so far.
The nvarchar(max) differs in that it only stores the type ID, there’s no length. Given the lack of a length (technically the invalid length of 0 is stored), we read it as being –1, telling us that it’s a LOB/MAX field being stored with a max_length of –1 and a maximum in_row length of 8000, provided it’s not stored off-row.
Varbinary seems to follow the exact same format.
time
0n809 = 0x329. 0x29 = the type ID of 41. 0x3 being the scale of 3. As with the datetime2 field, the precision scales with the scale (pun only slightly intended) – precision = 9 + scale.
text
0n4131 = 0x1023. 0x23 = the type ID of 35. 0x10 being the max_length of 16. The reason the text type has a max_length of 16 is that text is a LOB type that will always be stored off row, leaving just a 16 byte pointer in the record where it’s logically stored.
Conclusion
The OPENROWSET(TABLE RSCPROP, x) obviously performs some dark magic. The ti field is an integer that’s used to store multiple values & formats, depending on the row type. Thus, to parse this properly, a switch would have to be made. Certain types also take values for a given – the precision fields based on the scale value, float having a fixed precision of 53 etc. It shouldn’t be long before I have a commit ready for OrcaMDF that’ll contain this parsing logic :)