I recently gave a presentations on the topic of GUID usage at Miracle Open World. After finishing off my last slide and opening to questions, one of the attendees told a story of how an implicit GUID conversion had resulted in index scans instead of index seeks.
It’s commonly known that to use indexes effectively, we need to seek. Furthermore, to ensure we don’t scan, we should avoid using functions, casts, etc. as predicates as that will cause the optimizer to not utilize the indexes properly. However, in this case the situation was presented as query having a simple “where SomeCol = ‘74e03ed0-6d51-413a-bffb-76b5e409afc1’”. As far as I knew, that should just convert automatically into a uniqueidentifier and still use an index seek. A simple test shows that to be the case as well:
create table #Test
(
ID int identity(1,1) constraint pk_Test_ID primary key clustered,
Guid uniqueidentifier default(newid()),
Padding char(100) null
)
create nonclustered index idx_Guid on #Test (Guid)
declare @cnt int = 0
while @cnt < 10000 begin
insert into #Test default values
set @cnt += 1
end
select * from #Test where Guid = '74e03ed0-6d51-413a-bffb-76b5e409afc1'
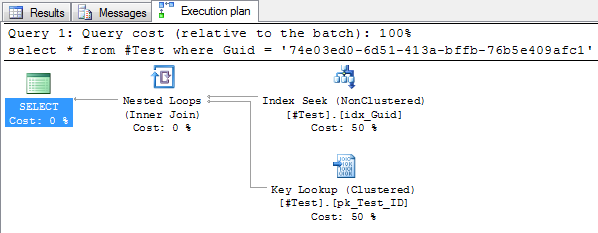
An index seek with a bookmark lookup, perfect. I had no answer to his question so I asked if he could send me the query they were running, so I could take a look at it. I got the queries sent as well as the execution plan, and sure enough, an index scan was performed with a CONVERT_IMPLICIT predicate:
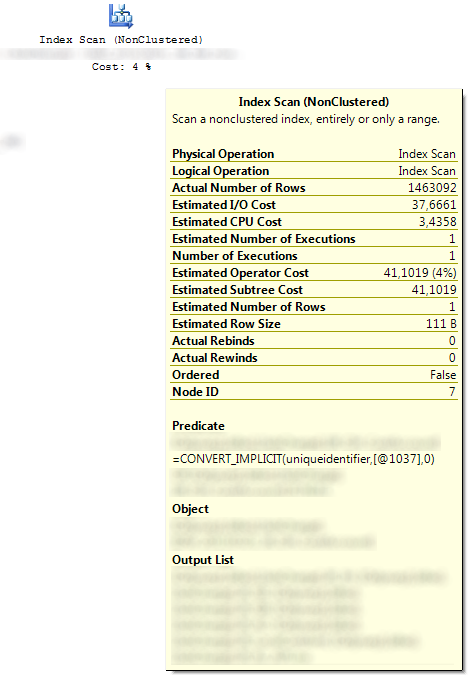
As the system is internal, I promised to keep it anonymous, thus most of it is blurred out. I also do not have access to the actual schema, I was however able to deduce the relevant parts from the execution plans and column/table names used. Here’s an abstract version of the query being run:
-- Schema
create table #GuidTest
(
ID int identity(1,1) constraint pk_GuidTest_ID primary key clustered,
GuidA uniqueidentifier default(newid()),
GuidB uniqueidentifier default(newid()),
GuidC uniqueidentifier default(newid()),
GuidD uniqueidentifier default(newid()),
GuidE uniqueidentifier default(newid()) null,
GuidF uniqueidentifier default(newid()),
Cost float default(rand()) null,
Padding char(20)
)
create nonclustered index idx_Guid on #GuidTest (GuidA, GuidB, GuidC, GuidD, GuidE) include (Cost, GuidF)
with ( pad_index = off,
statistics_norecompute = off,
sort_in_tempdb = off,
ignore_dup_key = off,
drop_existing = off,
online = off,
allow_row_locks = on,
allow_page_locks = on,
fillfactor = 90)
create table #GuidJoin
(
JoinGuid uniqueidentifier default(newid()),
JoinValue char(3) null
)
create nonclustered index idx_JoinGuid on #GuidJoin (JoinGuid)
-- Query
select
sum(isnull(Cost, 0)),
GuidA,
GuidB,
GuidC,
GuidD
from
#GuidTest
left join
#GuidJoin on GuidF = JoinGuid
where
(JoinValue = 'XYZ' or JoinValue is null) AND
(
(GuidA = '0B0220E8-053E-43CA-A268-AD78DF4F7DC0' AND GuidB = 'F268830A-5C13-4E6E-AE63-DAA1353A6306' AND GuidC = '5565A230-E919-4229-BA65-49AE1D4FFAE3' AND GuidD = 'C4BAAA53-9447-419F-A7FA-76C43B8F1049') OR
(GuidA = 'D32EE121-FB05-44E8-BD36-86833E4BE3B6' AND GuidB = '9DE3B8FF-95B1-4519-9F92-9DE7758D9DE6' AND GuidC = '8ADF6C5E-E3B6-49C7-BEF7-E26074D8874C' AND GuidD = 'D2BBB20C-991D-44FD-848C-124B33CFC9F6') OR
-- Snipped about 250 lines --
(GuidA = '54E75EB0-83FE-40A0-B2E0-6A2A71B393AA' AND GuidB = 'CC3D2107-6C1B-4ED6-B708-6503BFAD8965' AND GuidC = 'B62EBEA3-193A-422A-846D-978000E1AB9C' AND GuidD = 'ECC25117-B903-49EE-8B66-8E31F07170A5')
) AND
(GuidE = '08F62323-0707-430E-B5F8-5FFF040D2AF6' OR GuidE is null)
group by
GuidA, GuidB, GuidC, GuidD
Obviously this is not the optimal way of doing this, passing in a large amount of variables in ad-hoc fashion. This was not an in-house system however, so they had to live with the code. Using my code as a test, filled with a large number of dummy test data, I’m not able to reproduce the issue. However, the most interesting part is how they managed to solve the problem. Instead of doing a usual uniqueidentifier predicate like:
select * from #Test where Guid = '74e03ed0-6d51-413a-bffb-76b5e409afc1'
They were able to modify the predicates to look like this:
select * from #Test where Guid = {GUID'74e03ed0-6d51-413a-bffb-76b5e409afc1'}
And if you look closely at the execution plan of the first query, this is what’s happening internally as well:
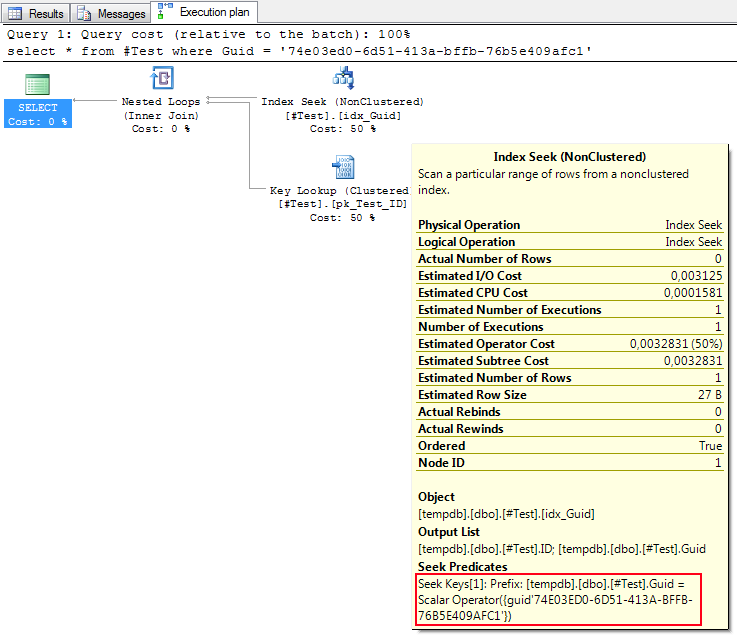
Since I was unable to reproduce the issue, and I can find no documentation on the {GUID’xyz’} (neither online nor in BOL) syntax, I am unable to explain exactly what’s going on. EDIT: Mladen Prajdić found a page describing GUID Escape Sequences.aspx). My guess is that the input query, while simple in structure, became too complex due to the large number of predicates, and thus the optimizer was unable to convert the input string to a GUID at compile time and thus had to resort to an IMPLICIT_CONVERT, causing an index scan. Using parameters, a TVF or another form of temporary table to hold those ~1000 predicate GUIDs in would obviously have been a lot more optimal as well, and would have avoided the implicit convert too. Being as it was a third party system, that was a modification that could not be made. If you have any further information on the {GUID’xyz’} constant syntax, please do get in touch.
While I have no final explanation, the conclusion must be – watch out for those implicit conversions, even when you absolutely do not expect them to occur.