Last year I went on a marathon conference trip, starting out in LA at Adobe Max, continuing on to QCon in San Francisco before finally ending up in lovely Seattle for the PASS Summit.
Of the three, the one I’ll definitely be returning to this year is the PASS Summit. Last year I had the honor of getting a nice neon green “FIRST-TIMER” snippet on my badge, a snippet I wore with honor. This year however, I’m aiming for the Alumni snippet, and perhaps even the speaker snippet by submitting a couple of abstracts.
As I’ve been somewhat busy with OrcaMDF in my spare time recently, both of my abstracts use OrcaMDF as the origin for going into the internals. I really hope I get a chance to present about this as I’m super psyched about it :)
Knowing the Internals – Who Needs SQL Server Anyway?
You’re stuck on a remote island with just a laptop and your main database .MDF file. The boss calls and asks you to retrieve some data, but alas, you forgot to install SQL Server on your laptop. Luckily you have a HEX editor by your side!
In this level 500 deep dive session we will go into the intimate details of the MDF file format. Think using DBCC Page is pushing it? Think again! As a learning experiment, I’ve created an open source parser for MDF files, called OrcaMDF. Using the OrcaMDF parser I’ll go through the primary storage mechanisms, how to parse page headers, boot pages, internal system tables, data & index records, b-tree structures as well as the supporting IAM, GAM, SGAM & PFS pages.
Has your database suffered an unrecoverable disk corruption? This session might just be your way out! Using a corrupt & unattachable MDF file, I’ll demo how to recover as much data as possible. This session is not for the faint of heart, there will be bytes!
Why & What?
I originally gave this presentation at Miracle Open World 2011 and got some great feedback. Fueled by positive feedback I continued the development and am now at the point where I have so much content I considered doing a 3½ hour session instead. By attending this session you will not only see diagrams of internal structures on slides, you’ll actually see C# code demonstrated that parses & utilizes them!
Demystifying Database Metadata
You know how to query sys.tables, sys.columns and perhaps even sys.system_internals_allocation_units to discover the metadata contents of a database. But where are these views getting their data from, and how do the core system tables relate?
Based on my work with OrcaMDF, an open source C# parser for MDF files, I will demonstrate how to parse the internal system tables. Using just the boot page as origin, we’ll discover how to traverse the chain of references that ultimately end up in references to the actual system table data, from where we can parse the data records.
Once we’ve got the system table data, I’ll demonstrate how to correlate the different tables to end up with the data we see in common system views.
Why & What?
As I continued the development of OrcaMDF I used the various system views extensively – sys.objects, tables, columns, indexes, internals_allocation_units etc. However, as development moved forward and I needed to parse that metadata myself, I had to look into the underlying tables – sysallocunits, sysschobjs, sysrowsets, sysrowsetcolumns. Join this session and let’s enter the realm of the hidden metadata and let’s explore it together!
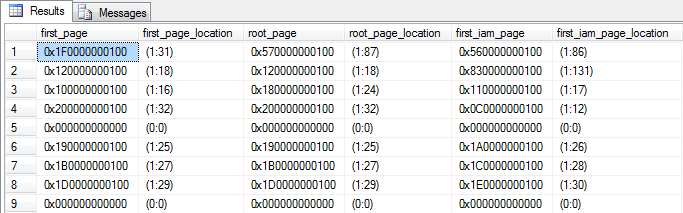
I often like to spend my weekends perusing the sys.system_internals_allocation_units table, looking for the remnants of Frodo and his crew. In the sys.system_internals_allocation_units there are several references to relevant pages:
select
first_page,
root_page,
first_iam_page
from
sys.system_internals_allocation_units
Once you get used to reading these pointers, it becomes rather trivial – byte swap the last two pointers to get the file ID (0 or 1 in all of the above rows), and byte swap the first four bytes to get the page ID. To make it a bit more easier for myself and for those who do not read HEX natively, I’ve made a simple function to convert the pointers into a more easily read format.
While not beautiful, it is rather simple. The result:
select
first_page,
dbo.getPageLocationFromPointer(first_page) as first_page_location,
root_page,
dbo.getPageLocationFromPointer(root_page) as root_page_location,
first_iam_page,
dbo.getPageLocationFromPointer(first_iam_page) as first_iam_page_location
from
sys.system_internals_allocation_units
I recently gave a presentations on the topic of GUID usage at Miracle Open World. After finishing off my last slide and opening to questions, one of the attendees told a story of how an implicit GUID conversion had resulted in index scans instead of index seeks.
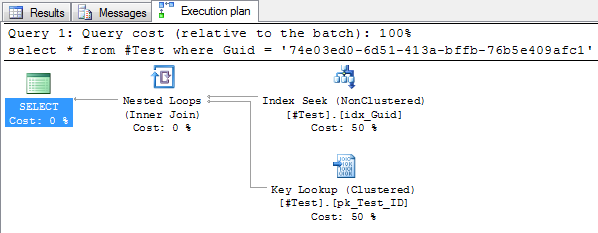
It’s commonly known that to use indexes effectively, we need to seek. Furthermore, to ensure we don’t scan, we should avoid using functions, casts, etc. as predicates as that will cause the optimizer to not utilize the indexes properly. However, in this case the situation was presented as query having a simple “where SomeCol = ‘74e03ed0-6d51-413a-bffb-76b5e409afc1’”. As far as I knew, that should just convert automatically into a uniqueidentifier and still use an index seek. A simple test shows that to be the case as well:
createtable #Test
(
ID intidentity(1,1) constraint pk_Test_ID primarykey clustered,
Guid uniqueidentifier default(newid()),
Padding char(100) null
)
create nonclustered index idx_Guid on #Test (Guid)
declare @cnt int = 0
while @cnt < 10000begininsertinto #Test defaultvaluesset @cnt += 1endselect * from #Test where Guid = '74e03ed0-6d51-413a-bffb-76b5e409afc1'
An index seek with a bookmark lookup, perfect. I had no answer to his question so I asked if he could send me the query they were running, so I could take a look at it. I got the queries sent as well as the execution plan, and sure enough, an index scan was performed with a CONVERT_IMPLICIT predicate:
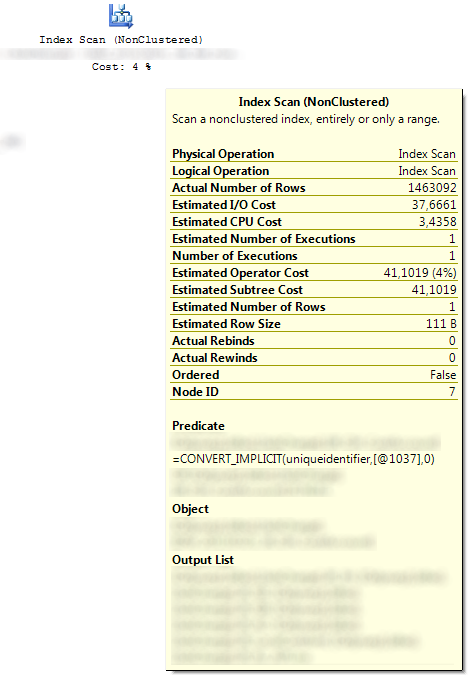
As the system is internal, I promised to keep it anonymous, thus most of it is blurred out. I also do not have access to the actual schema, I was however able to deduce the relevant parts from the execution plans and column/table names used. Here’s an abstract version of the query being run:
Obviously this is not the optimal way of doing this, passing in a large amount of variables in ad-hoc fashion. This was not an in-house system however, so they had to live with the code. Using my code as a test, filled with a large number of dummy test data, I’m not able to reproduce the issue. However, the most interesting part is how they managed to solve the problem. Instead of doing a usual uniqueidentifier predicate like:
select * from #Test where Guid = '74e03ed0-6d51-413a-bffb-76b5e409afc1'
They were able to modify the predicates to look like this:
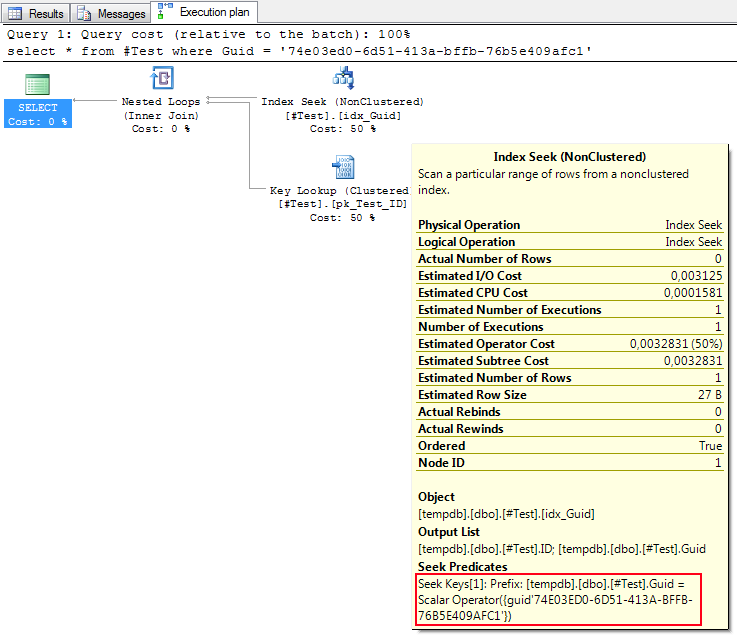
select * from #Test where Guid = {GUID'74e03ed0-6d51-413a-bffb-76b5e409afc1'}
And if you look closely at the execution plan of the first query, this is what’s happening internally as well:
Since I was unable to reproduce the issue, and I can find no documentation on the {GUID’xyz’} (neither online nor in BOL) syntax, I am unable to explain exactly what’s going on. EDIT: Mladen Prajdić found a page describing GUID Escape Sequences.aspx). My guess is that the input query, while simple in structure, became too complex due to the large number of predicates, and thus the optimizer was unable to convert the input string to a GUID at compile time and thus had to resort to an IMPLICIT_CONVERT, causing an index scan. Using parameters, a TVF or another form of temporary table to hold those ~1000 predicate GUIDs in would obviously have been a lot more optimal as well, and would have avoided the implicit convert too. Being as it was a third party system, that was a modification that could not be made. If you have any further information on the {GUID’xyz’} constant syntax, please do get in touch.
While I have no final explanation, the conclusion must be – watch out for those implicit conversions, even when you absolutely do not expect them to occur.
It’s now been roughly 42 weeks since I last wrote a blog entry, phew, time flies! I’ve been busy, one week became two weeks, a month, half a year and before long the tumbleweeds start drifting by.
I originally setup the blog back in ‘06 to blog about my ventures in the World Series of Poker. In a moment of temporary insanity, I decided to write my own blog engine as a fun project – reviving my previous homemade blog engine written in in VB, the horror. While it was a fun project initially, keeping it up to date, doing proper code formatting, file attachments, administration, etc., quickly became a major hassle. Writing blog posts was a tedious job, basically written as plaintext in Visual Studio and then copy/pasted into a textbox in an admin system. I’ve concluded that if I want to keep up blogging, I’d need a better system.
As a result, I’ve migrated my blog to SubText, including going through the formatting of all previous entries to ensure they keep the same format. I apologize for any RSS feed inconsistencies during the migration, it should be back to normal shortly. Running on SubText I could finally try out Windows Live Writer; Boy, do I regret not having tried that out earlier – after creating a couple of custom plugins for entering code and attaching files, writing posts is an absolute dream compared to before.
Last week I attended the Miracle Open World 2011 conference. As in the previous years the 80% content, 80% social moniker held true to its reputation. My legs and arms are still sore from carrying four-man rubber rings to the top of the four-story waterslide – not the typical aftermath of a conference. I met a lot of new awesome people and managed to pull of a couple of presentations with decent success as well, judging from the responses I’ve had so far. I’ve included the slides & demo code for the presentations below.
Anatomy of an MDF File
Ever felt like SQL Server slowed you down, and you’d rather just get the data yourself using a HEX editor? In this deep dive session I’ll give a run through of the MDF file format, what kind of page types exists? How are records stored on pages? How can we use this knowledge for optimizing performance and (catastrophic) disaster recovery? This session is not for the faint of heart. There will be bytes!
GUIDs make our lives simpler in lots of ways - reducing rountrips, decentralized ID generation, pseudo-security, etc. However, they come with a hefty price that may be overlooked untill it’s too late.
In this session I will give a thorough review of the hidden costs of using GUIDs in your systems. As they may be required, I will look at ways to alleviate the cost of GUIDs while still maintaining the semantic functionality
Testing mail functionality in code using external mail servers has always been a hassle. If the mail manages to dodge antispam and various other mischievous services, it’ll probably take several minutes to receive. On our Exchange servers it’ll typically take 10-15 minutes before a locally sent mail actually arrives back in my inbox. We can do better!
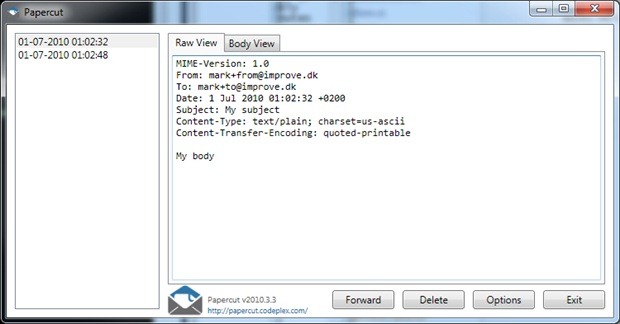
Papercut and smtp4dev are both applications that’ll emulate a remote SMTP server on your local machine. Instead of actually sending the mail onwards like a normal SMTP server, they’ll simply catch the mail and notify you. This means you’ll receive the mail instantly without any risks of being caught in spam filters or dying of old age before receiving the mail. I’ve tried out both Papercut and smtp4dev and here are some thoughts on both.
For the testing I’m using this rather simple piece of code:
Program.cs
using System.Net.Mail;
namespace MailTest
{
class Program
{
staticvoid Main()
{
var sc = new SmtpClient();
sc.Host = "127.0.0.1";
var mail = new MailMessage("mark+from@improve.dk", "mark+to@improve.dk")
{
Subject = "My subject",
Body = "My body"
};
sc.Send(mail);
}
}
}
Papercut
+ Xcopy deployment
I love the fact that I can just unzip the download and run the .exe right away, no installation, no configuration.
+ Dead simple
It lacks some features, but when all you need is to quickly check the contents of a sent email, the simplicity of Papercut makes it extremely fast to use.
+ HTML view directly in interface
Unlike smtp4dev, Papercut will display HTML email contents directly in the interface without having to open the mail in Outlook (which I don’t even have on my machine).
+ Forwarding option
If you need to forward the mail to a colleague you can do it right in the interface. It’ll prompt you for an SMTP server to use - unfortunately it’s not possible to provide authentication credentials.
- HTML view should open links in new window
When checking out HTML emails I often want to verify that links are correct. Papercut will open them directly in the Papercut interface, making it hard to verify the address.
- Lacks simple connection status in interface
There’s no green bar/indicator for whether Papercut is actively listening of if it’s been obstructed or failed to bind to the port on startup.
- Lacks simple way to open .eml files
Both Papercut and smtp4dev save the emails as .eml files that can easily be opened by Outlook or antoher compatible mail client. In Papercut you have to find the executable folder and open the files directly though. A simple double-click function would be nice.
- No way to quickly delete all mails
You have to delete all incoming mails one by one.
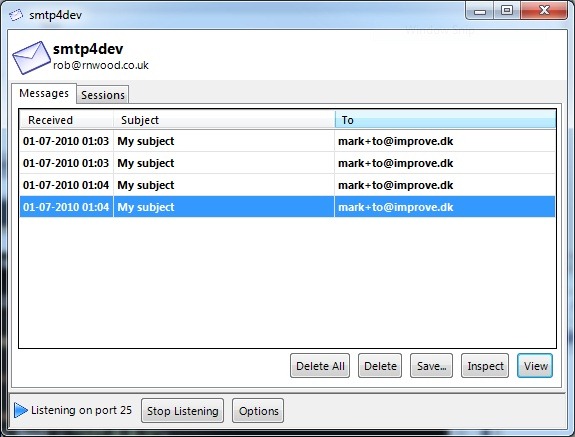
smtp4dev
+ Inspection shows formatted headers
The inspection view lists headers in a table for easier reading.
+ Inspection shows mime parts
If your mail contains multiple mime parts, they can easily be seen separately in the inspection interface.
+ More UI options
smtp4dev enables you to delete all mails easily, has context menu options when right clicking the notification icon as well as generally more UI options than Papercut.
+ Lots more options
smtp4dev has vastly more options than Papercut. smtp4dev supports authentication, SSL and various other options, while Papercut only supports defining the listening port.
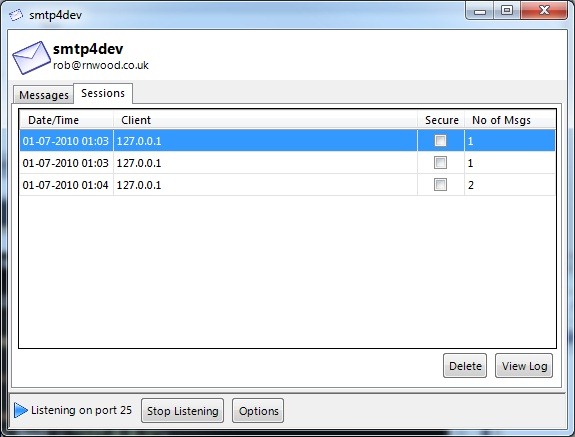
+ List of SMTP sessions
Using the sessions tab you can easily see how many SMTP sessions have occurred, as well as how many mails were sent as part of that session.
+ More activity on Codeplex
smtp4dev has somewhat more discussion activity as well as recent commit activity, whereas Papercut seems somewhat more abandoned.
- Cumbersome message viewing
Viewing the actual email messages requires either opening the .eml files in a mail viewer application or opening up the inspection interface. Papercut is much faster since you can view the body directly in the list interface. A reading pane option would be nice.
- Requires installation
An application like this is meant to be lightweight and easily fired up when required. smtp4dev requires installation and even offers you to let it start on bootup. It might be a matter of preferences, but I really like Papercuts xcopy deployment.
- Autoupdate
Expanding on the point above; a tool like this is not a tool that I really need to have checking for updates automatically. I know, I can’t really make this a minus, but still, KISS.
- Crashes
While I haven’t been able to make a reproduction case, smtp4dev crashed on me a couple of times, seemingly while running in the background without SMTP activity.
Conclusion
So which is best? It depends! I use both… If all I need is to quickly check a single mails contents then I’ll fire up Papercut. If I need to catch multiple emails and perhaps inspect the contents more thoroughly, I’ll use smtp4dev. Generally I prefer to use Papercut if I don’t need any further features.
Both projects’ source code seems decent, though I’ve just skimmed quickly. smtp4dev generally seems more robust and also includes a limited amount of unit tests.
In this post I’ll walk you through how to setup IIS Application Request Routing so that any requests for a /wiki/ subdirectory are routed onto a separate server, while all other requests are handled by the server itself.
Let’s imagine a fictional scenario where I want to add a wiki to my website. Thus, all requests to improve.dk/wiki/* are mapped to a dedicated LAMP based server that runs some kind of wiki software. All other requests should be served by the normal improve.dk webserver.
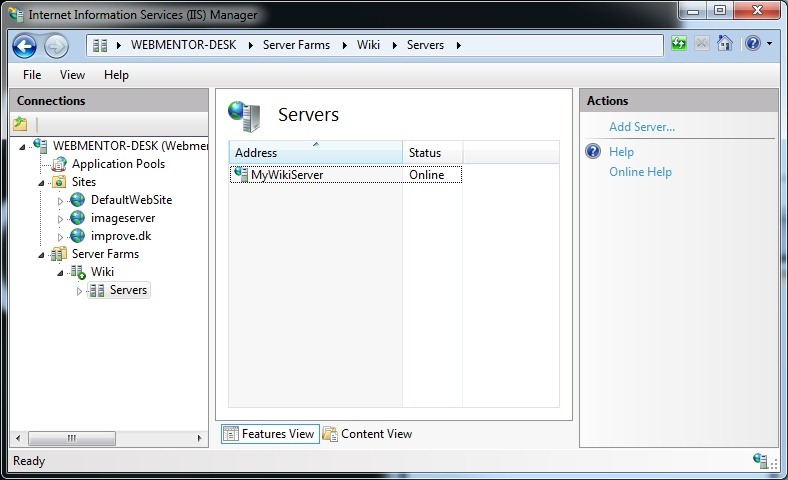
The first task is to setup a new server farm, called Wiki in my case. Add the server to the list of servers, using its hostname, MyWikiServer in this case. If you setup (temporarily, for testing) improve.dk so it maps to the wiki server, requesting http://improve.dk/Wiki/ should return back the expected result from the wiki server, if requested from the normal webserver.
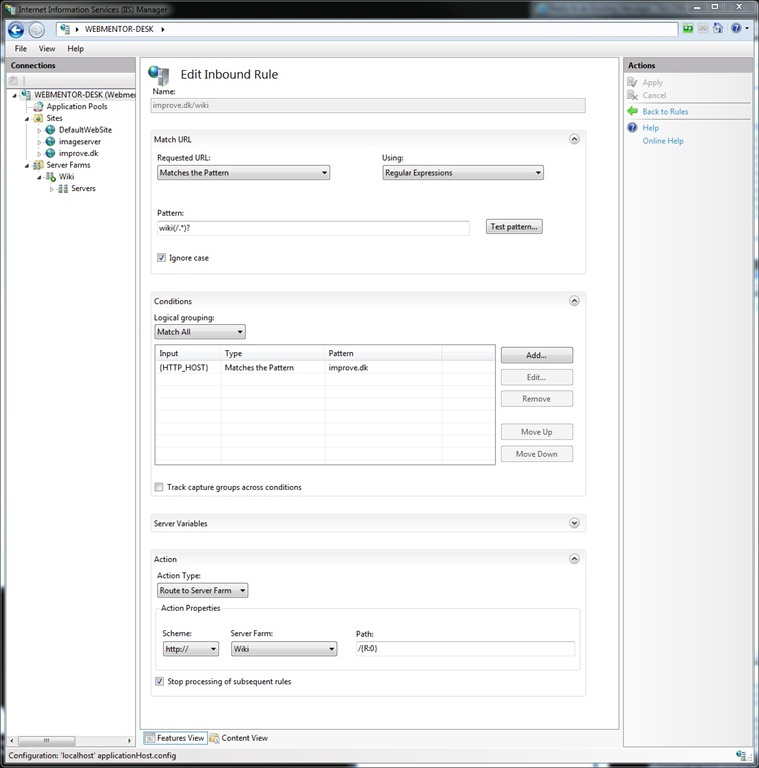
Next, setup a URL Rewrite rule at the global level like the following:
The rule matches all requests for the /wiki/ directory, whether there’s a trailing slash or further subdirectories. It ensures not to match a request like /wikipedia/. The request is routed onto the Wiki webfarm which sends the request onto the MyWikiServer server. Note that there’s a condition ensuring this rule will only match requests for the improve.dk domain so other websites aren’t affected. There are no changes to the actual improve.dk website setup.
Correction: As noted by Rob Hudson, the regular expression should actually be:
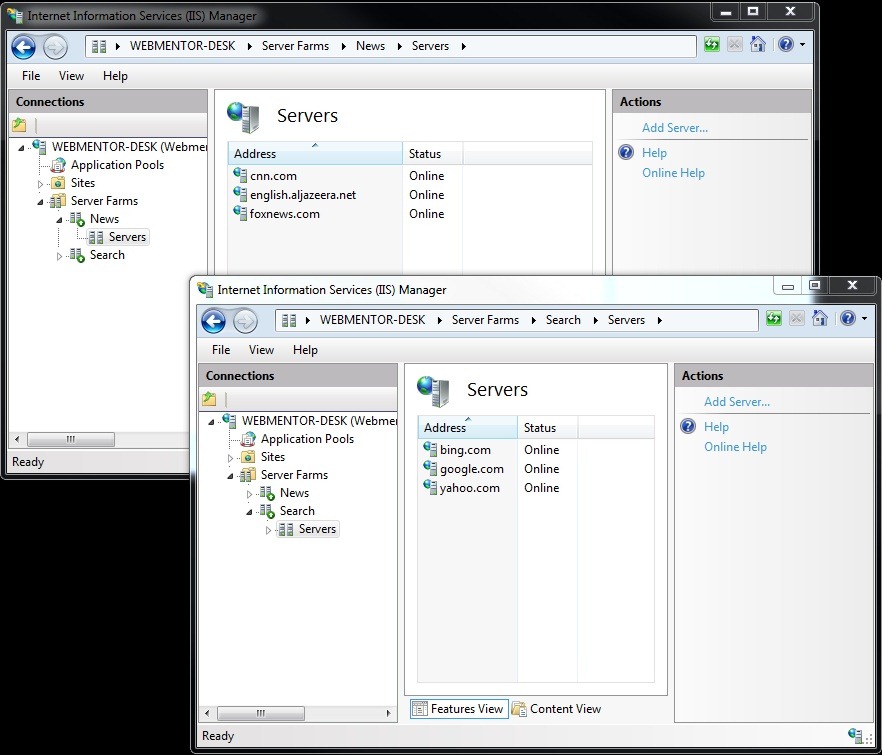
I own a bunch of search engines, bing.com, google.com and yahoo.com. Likewise, I own a bunch of news sites cnn.com, english.aljazeera.net and foxnews.com(alright, bear with me on that last one, just using it as an example). Luckily, my users don’t really care which search engine or news site they go to, as long as they end up at “a” search engine or “a” news site. To help me distribute the load we’ll setup two IIS ARR web farms that’ll load balance between the news sites and search engines.
Setting up the farms
Start by installing the Application Request Routing module if you haven’t done so already. Now create two sever farms called “News” and “Search”. Add the search & news websites to each of their server farms like so:
You may also setup the farms directly in applicationHost.config:
Go to the IIS level “URL Rewrite” settings page. If any default rules were created in the installation of IIS ARR, delete them now. Create a new rule from the blank template and call it “search.local”. Set the Match URL to use Wildcards and enter a pattern of “*”. This ensures that the rule matches and URL that we send to the server - no matter the hostname.
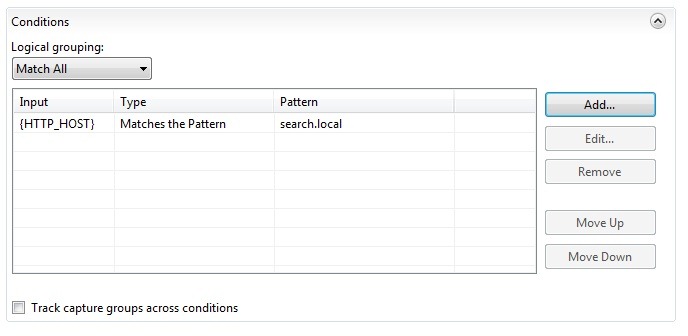
Expand the Conditions pane and add a new condition. Set the input to “{HTTP_HOST}” and type the pattern “search.local”. The {HTTP_HOST} condition ensures that this rule only matches requests to the search.local hostname.
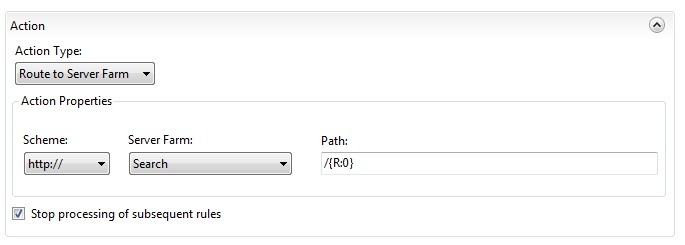
Finally set the action type to “Route to Server Farm” and choose the Search server farm. Tick the “Stop processing of subsequent rules” as the request should be routed onto the server farm as soon as this rule matches.
As the last step, create a second identical rule except it should be named news.local and have an {HTTP_POST} condition matching the news.local hostname. Setting up the rewrite rules can also be done in applicaitonHOst.config directly:
Create two host entries in your %windir%System32Driversetchosts file that makes news.local and search.local point to 127.0.0.1. Now when you open a browser and enter news.local or search.local, you should hit the search engines and news sites we setup earlier. By default IIS ARR will distribute the requests to the server with the least current requests - and since we’re the only ones hitting them we’ll basically always just hit the first server. To alleviate this you can change the load distribution mode to a weighted round robin with even distribution, that’ll ensure you hit the sites one by one in turn.
Note that this’ll only load CNN and Bing correctly as several of the other domains only listen to their configured domains (IIS ARR will proxy the reuqest onto the origin servers with a hostname request of search & news.local respectfully). I’ll follow up on how to fix that later on.
A common scenario in RIA’s is to show a large amount of small pictures on a single page. Let’s say we want to show 100 images in a grid. While the simplest approach is to just put in 100 image objects and load in the images one by one, I believe it can be done smarter…
The cost of a request
Each and every request will have a header overhead of about ~400 bytes outgoing and ~200 bytes ingoing - both varying depending on the host, cookies, headers etc. Multiply that by 100 requests and we’ve got about 60KB of data overhead, just for the headers. Even worse is the actual roundtrip time of sending the packets to the server and getting a reply back; Even with reuse of the connections, there’s a large cost involved.
Bundling requests
Imagine if we could just make a single request to the server - “Hey, please send me these 100 images, ty” - and then we’ll get back a single response containing all the images. One way of doing this would be to zip the images on the server and then unzip them on the client - there’s open zip libraries for both Silverlight and Flash. However, this has a large CPU cost on not only the server, but also on the client. Furthermore, images usually don’t compress much so it’s basically just a waste. In this post I’ll present a C# class for bundling images as well as an AS3 class for reading the bundled image stream. While the RIA sample is in Actionscript, it’s easily applicable to Silverlight as well - should anyone feel like implementing the client side in Silverlight, please let me know so I can link you.
Generating sample images
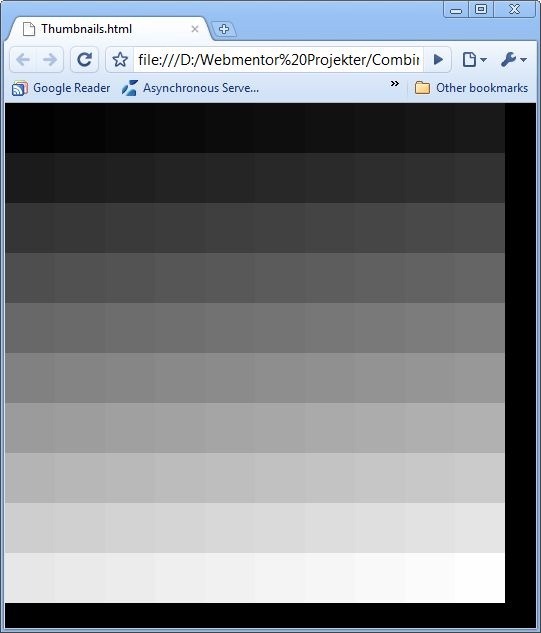
Our first task is to generate some sample images. The following code will create 100 images named 1-100.jpg containing the greytones from #000000 (well, almost) to #FFFFFF.
The ImageStream class contains a dictionary that’ll hold references to the files untill we’re ready to write them out. Each added file consists of a key as well as a filepath. To keep things simple, I’m limiting the key names to ASCII codes between 32 and 126 to avoid unprintable characters.
The class has a Write method that’ll write all the added images to the provided stream. Each image consists of four parts:
4 bytes (int) that contains the combined length of the key and payload plus two extra bytes for specifying the key length.
2 bytes (short) that contains the key length.
X bytes containing the key using UTF8Encoding. I’ll explain later why I’m using UTF8Encoding and not ASCIIEncoding.
X bytes containing the actual file contents.
ImageStream.cs
publicclass ImageStream
{
IDictionary files = new Dictionary();
publicvoidAddFile(string key, string filePath)
{
files.Add(key, new FileInfo(filePath));
if (key.ToCharArray().Any(x => x < 32 || x > 126))
thrownew ArgumentException("Invalid character used in key.");
}
publicvoidWrite(Stream stream)
{
// For each file, write the contentsforeach (var file in files)
{
// Write payload length
stream.Write(BitConverter.GetBytes((int)file.Value.Length + file.Key.Length), 0, 4);
// Write key length
stream.Write(BitConverter.GetBytes((ushort)file.Key.Length), 0, 2);
// Write key
stream.Write(Encoding.UTF8.GetBytes(file.Key), 0, file.Key.Length);
// Write file
stream.Write(File.ReadAllBytes(file.Value.FullName), 0, (int)file.Value.Length);
}
}
}
On the server side: Image.ashx
All we need now is a file to serve the ImageStream. I’m using an HttpHandler called Image.ashx to loop through all the files (located in “/Imgs/“) and add them to the ImageStream before writing them out to the output stream.
Image.ashx
publicclass Image : IHttpHandler
{
publicvoidProcessRequest(HttpContext context)
{
context.Response.ContentType = "application/octet-stream";
context.Response.Buffer = false;
var imgc = new ImageStream();
for(int i=1; i<=100; i++)
imgc.AddFile("img" + i, context.Server.MapPath("Imgs/" + i + ".jpg"));
imgc.Write(context.Response.OutputStream);
}
publicbool IsReusable
{
get { returntrue; }
}
}
On the client side: CombinedFileReader.as
The CombinedFileReader class takes a url in the constructor, pointing to the stream we want to retrieve. Once we call load() we spawn a URLStream and listen for the PROGRESS and COMPLETE events. The core of the class is the onProgress method, being invoked on both PROGRESS and COMPLETE events. We don’t really care which event it is as both means there’s new data for us to consume.
The onProgress method works as a simple state machine. This could be done much cleaner by abstracting away the state functionality, but it’s simple enough to be easily understood. There are just two states we can be in:
header
In this state we’re currently waiting for there to be 4 bytes available, meaning we can read the first integer containing the number of bytes required to load the current file. Once this has been loaded into the currentFileLength variable, we change the state to “payload”.
payload
In this state we’re waiting for the remaining bytes to be available. As soon as they become available, we read the key using the readUTF() method on the URLStream class. readUTF automatically reads a short first and expects these two bytes to contain the length of the string to be read in UTF format - thus the use of UTF8Encoding over ASCIIEncoding. As both encodings take up the same amount of bytes, it’s purely a matter of convenience. After this we read in the payload - the image. It’s important to explicitly set the ByteArray endianness to avoid problems since the ByteArray by default uses little endian while our ImageStream uses big endian. Note that the header bytes contains the combined length of the key + payload, thus we should only read in currentFileLength - currentKey.length bytes. Finally we dispatch a custom FileReadEvent (see code further down) taking in the key and payload bytes as parameters.
The final part of demoing the bundled image stream is to actually consume the stream by using the CombinedFileReader AS3 class. Once the application loads we instantiate a new CombinedFileReader, passing in the url to the Image.ashx HttpHandler I mentioned earlier. Before calling the load() method we subscribe to the ON_LOADED event that’s dispatched by the CombinedFileReader.
Once we’ve read in a file and onFileLoaded() is called, we first need to create a new Loader object and pass the bytes into it using loadBytes(). Before loading the bytes we store a position object in a dictionary. The position object will contain the x & y coordinates for the image once it’s loaded. We can count on the onFileLoaded function to be called in the same order as the images are streamed. Due to the asynchronous nature of loadBytes() the onLoadComplete() function will be called at random times and will thus not be sequential. Once the bytes are loaded in and onLoadComplete is called, we create a new Image, set the source to the loaded content, set the size and coordinate. Finally we add the image to the current application as an element. Note that the images are 100x100px but to conserve space I’m resizing the client side to 50x50px.
Thumbnails.mxml
<?xml version="1.0" encoding="utf-8"?><?xml:namespace prefix = s />
<?xml:namespace prefix = fx />
The result
If all goes well, the result should look like this:
On April 28th I’ll be giving a presentation at Aarhus .NET User Group on SharedCache. The presentation will be part of a combined event where Morten Jokumsen will be presenting Velocity and Jakob Tikjøb Andersen will be presenting Cassandra.
I’ll give a quick run through of what SharedCache is and what it’s not, how to use it and what you can expect from it. If all goes well, I’ll have my EC2 SharedCache cluster up and running for demo purposes :)