Note that the DecimalColumn has a precision of five and a scale of two. That basically boils down to 999.99 being the largest number we can store and -999.99 being the smallest. The precision of five defines the maximum number of digits in the number, scale defines the number of digits to the right of the decimal point. If we insert an integer value of 999 it’ll have .00 stored implicity, thus we can’t insert neither 1000 nor 10000 without any decimal digits. Knowing the configured precision and scale is important, as we’ll see in just a moment.
Let us insert a single row into the tblDecimalTest table.
This is the result if we perform a select on the table:
SELECT * FROM tblDecimalTest
DecimalColumn
0.74
Both decimal variables were declared as dec(5,2) so it matches the column in the table. Calculating 20.5 / 27.52 on a standard calculator gives a result of 0.7449127, but as we’re storing this with a scale of two, the value is rounded off to 0.74.
We just inserted a value of 20.5 / 27.52 into a dec(5,2) column. Let’s make a select using those same variables:
What is that? No results! Why does this happen? After all, we just inserted @Decimal1 / @Decimal2, so surely we should be able to select that row again? The key lies in how SQL Server converts decimal datatypes during math operations. What we’re looking for is the divison operator which defines the following precision and scale calculations:
Thus, our division of two dec(5,2) variables is implicitly converted into a dec(13,8) value! Similar conversions are made for addition, subtraction and multiplication.
When performing the WHERE clause, we’re in fact comparing a dec(5,2) column with a dec(13,8) value. Behind the scenes, SQL Server will implicitly convert the values to a common datatype that fits both - which is dec(13,8). With a precision of 13 and a scale of 8, 0.74 and 0.74491279 are not equal, and thus we don’t get any results back. If we were to cast the divison as a dec(5,2) explicitly, we would find the row:
While testing in SQL Server Management Studio, this might be an obvious problem. When encountering the same problem from code, it’s much more difficult to notice - especially if you don’t know the precise schema you’re working against. Observe the following code working on an empty tblDecimalTest table.
Based on my previous post on how to implement a simple genetic algorithm, I got some great comments pointing out that the algorithm might not be the most pure form of a genetic algorithm. I won’t disagree, though I will point out that evolution also does occur due to mutation alone, so genetic algorithms may come in different forms.
Making it more “genetic”
The basic point is that I was only mutating my chromosomes, I wasn’t actually pairing them up and reproducing via a crossover function).
I’ve changed my GeneticAlgorithm class slightly to give more control to the subclasses of how reproduction works, whether it be by mutation and/or crossover. What I’ve done is to change the Mutate method into a Reproduce method, taking in the complete survivor enumeration of IChromosome’s instead. That way, the implementing subclass has full control over the selection and breeding of the survivors.
///<summary>/// Creates an arbitrary number of mutated chromosomes, based on the input chromosome.///</summary>protectedabstract IEnumerable<IChromosome<T>> Reproduce(IEnumerable<IChromosome<T>> survivors);
The PerformEvolution method has been changed as well. Instead of selecting the survivor to mutate here, we let it be up to the subclass. Thus, we just loop until we’ve reached our ChromosomePopulationSize, while passing the survivors into the Reproduce method.
///<summary>/// Performs an evolution by picking up the generation survivors and mutating them.///</summary>publicvoidPerformEvolution()
{
IList<IChromosome<T>> newGeneration = new List<IChromosome<T>>();
// Get the survivors of the last generation
IEnumerable<IChromosome<T>> survivors = GetGenerationSurvivors();
// Add the survivors of the previous generationforeach (var survivor in survivors)
newGeneration.Add(survivor);
// Until the population is full, add a new mutation of any two survivors, selected by weighted random based on their fitness.
Random rnd = new Random();
while (newGeneration.Count < ChromosomePopulationSize)
foreach (var offspring in Reproduce(survivors))
{
newGeneration.Add(offspring);
if (newGeneration.Count == ChromosomePopulationSize)
break;
}
// Overwrite current population
ChromosomePopulation = newGeneration;
// Increment the current generation
CurrentGenerationNumber++;
}
Instead of overriding Mutate() in the RgbGuesser class, we’re now overriding Reproduce. Given that we have three basic genes in each of our chromosomes (R, G & B), we can produce 2^3 different combinations, including the original two combinations AAA and BBB. Each time Reproduce is called, we’ll create all eight different combinations and mutate them slightly, before returning them to the GeneticAlgorithm. This way we’re producing eight children of each parent pair of chromosomes, and thus, as Matt^2 pointed out, allowing the chromosomes of developing partial solutions themselves more efficiently.
protectedoverride IEnumerable<IChromosome<Rgb>> Reproduce(IEnumerable<IChromosome<Rgb>> survivors)
{
// Get two random chromosomes from the survivorsvar chromA = survivors
.OrderBy(c => random.NextDouble() * c.Fitness)
.First();
var chromB = survivors
.OrderBy(c => random.NextDouble() * c.Fitness)
.Where(c => c != chromA)
.First();
// Now generate and return each different combination based on the two parents, with slight mutationvar aaa = new RgbChromosome(chromA.ChromosomeValue.R, chromA.ChromosomeValue.G, chromA.ChromosomeValue.B);
mutateChromosome(aaa);
yieldreturn aaa;
var aab = new RgbChromosome(chromA.ChromosomeValue.R, chromA.ChromosomeValue.G, chromB.ChromosomeValue.B);
mutateChromosome(aab);
yieldreturn aab;
var abb = new RgbChromosome(chromA.ChromosomeValue.R, chromB.ChromosomeValue.G, chromB.ChromosomeValue.B);
mutateChromosome(abb);
yieldreturn abb;
var aba = new RgbChromosome(chromA.ChromosomeValue.R, chromB.ChromosomeValue.G, chromA.ChromosomeValue.B);
mutateChromosome(aba);
yieldreturn aba;
var baa = new RgbChromosome(chromB.ChromosomeValue.R, chromA.ChromosomeValue.G, chromA.ChromosomeValue.B);
mutateChromosome(baa);
yieldreturn baa;
var bba = new RgbChromosome(chromB.ChromosomeValue.R, chromB.ChromosomeValue.G, chromA.ChromosomeValue.B);
mutateChromosome(bba);
yieldreturn bba;
var bab = new RgbChromosome(chromB.ChromosomeValue.R, chromA.ChromosomeValue.G, chromB.ChromosomeValue.B);
mutateChromosome(bab);
yieldreturn bab;
var bbb = new RgbChromosome(chromB.ChromosomeValue.R, chromB.ChromosomeValue.G, chromB.ChromosomeValue.B);
mutateChromosome(bbb);
yieldreturn bbb;
}
privatevoidmutateChromosome(IChromosome<Rgb> chromosome)
{
chromosome.ChromosomeValue.R = Math.Min(255, Math.Max(0, chromosome.ChromosomeValue.R + random.Next(-5, 6)));
chromosome.ChromosomeValue.G = Math.Min(255, Math.Max(0, chromosome.ChromosomeValue.G + random.Next(-5, 6)));
chromosome.ChromosomeValue.B = Math.Min(255, Math.Max(0, chromosome.ChromosomeValue.B + random.Next(-5, 6)));
}
Reducing the chance of mutation
As weenie points out in the comments, reducing the chance of mutation will actually improve results. By changing the mutateChromosome slightly, we only mutate it for every 1/3 reproductions.
At this point we’ve got several variables to tune - population size, survivor count, mutation probability & mutation severeness. This sounds like an optimal problem for an evolutionary algorithm :)
In this blog post I’ll give a quick introduction to what genetic algorithms are and what they can be used for. We’ll implement a genetic algorithm that attempts to guess an RGB color by evolving upon a random set of initial guesses, until it at some point evolves into the correct RGB value.
What are genetic algorithms?
Contrary to other types of algorithms, genetic algorithms do not have a clear path of improvement for solution candidiates, and it’s not an exhaustive search. A genetic algorithm requires a few base components:
A representation of a candidate solutions.
A way of calculating the correctness of a candidate solution, commonly referred to as the fitness function.
A mutation function that changes a candidate solution slightly, in an attempt to obtain a better candidate.
There are many different ways of implementing genetic algorithms, and there are usually many variables to adjust in a genetic algorithm. How large should the initial population be? How many solutions survives each generation? How do the survivors reproduce? In reproduction, does each survivor give birth to a single child, or multiple? As is noticeable from the terminology, genetic algorithms closely simulate biology.
The building blocks
What we’re trying to accomplish with this demo implementation, is to guess a random RGB value. The RGB values are stored in what is basically a triple class. The only added functionality is an override of the ToString function to make it easier for us to print the solution candidates.
class Rgb
{
internalint R { get; set; }
internalint G { get; set; }
internalint B { get; set; }
publicoverridestringToString()
{
returnstring.Format("({0}, {1}, {2})", R, G, B);
}
}
Next up, we have an interface that represents a basic chromosome. In this implementation, a chromosome is basically a candidate solution. The chromosome is also the type that implements the fitness function, to evaluate it’s own correctness. The fitness is returned as an arbitrary double value, the higher the value the better a candidate. The ChromosomeValue property is the actual value being tested - in this case, an instance of Rgb.
I’ve implemented the genetic algorithm using the template pattern for easy customization and implementation of the algorithm. The algorithm itself is an abstract generic class. This means we have to subtype it before we can use it, a requirement due to the abstract template based implementation.
publicabstractclass GeneticAlgorithm<T>
There’s a number of properties that are rather self explanatory, given the commenting.
///<summary>/// This is the amount of chromosomes that will be in the population at any generation.///</summary>protectedint ChromosomePopulationSize;
///<summary>/// This is the number of chromosomes that survive each generation, after which they're mutated.///</summary>protectedint GenerationSurvivorCount;
///<summary>/// This list holdes the chromosomes of the current population.///</summary>protected IList<IChromosome<T>> ChromosomePopulation;
///<summary>/// This is the current generation number. Incremented each time a new generation is made.///</summary>publicint CurrentGenerationNumber;
///<summary>/// This is the current generation population.///</summary>public IEnumerable<IChromosome<T>> CurrentGenerationPopulation
{
get { return ChromosomePopulation.AsEnumerable(); }
}
The constructor takes in two parameters, the size of the population at any given generation, as well as the number of survivors when an evolution is performed - and a new generation is created, based on the survivors of the old generation.
Lastly, we set the current generation as generation number 1, and then we call createInitialChromosomes to instantiate the initial generation 1 population.
///<summary>/// Initializes the genetic algorithm by evolving the initial generation of chromosomes.///</summary>///<param name="chromosomePopulationSize">The size of any generation.</param>///<param name="generationSurvivorCount">The number of chromosomes to survive the evolution of a generation.</param>publicGeneticAlgorithm(int populationSize, int generationSurvivorCount)
{
if (generationSurvivorCount >= populationSize)
thrownew ArgumentException("The survival count of a generation must be smaller than the population size. Otherwise the population will become stagnant");
if (generationSurvivorCount < 2)
thrownew ArgumentException("Where would we be today if either Adam or Eve were alone?");
ChromosomePopulationSize = populationSize;
GenerationSurvivorCount = generationSurvivorCount;
// Create initial population and set generation
CurrentGenerationNumber = 1;
createInitialChromosomes();
}
The createInitialChromosome initializes the ChromosomePopulation list, and then it’ll continue adding new chromosomes to it until the current population reaches the specified ChromosomePopulationSize. The initial random chromosomes are returned from the CreateInitialRandomChromosome function.
///<summary>/// Creates the initial population of random chromosomes.///</summary>privatevoidcreateInitialChromosomes()
{
ChromosomePopulation = new List<IChromosome<T>>();
for (int i = 0; i < ChromosomePopulationSize; i++)
ChromosomePopulation.Add(CreateInitialRandomChromosome());
}
There are three abstract methods that must be implemented by any subclass, CreateInitialRandomChromosome being one of them. I’ll go over the actual implementations later on.
///<summary>/// Creates an arbitrary number of mutated chromosomes, based on the input chromosome.///</summary>protectedabstract IEnumerable<IChromosome<T>> Mutate(IChromosome<T> chromosome);
///<summary>/// Creates a single random chromosome for the initial chromosome population.///</summary>protectedabstract IChromosome<T> CreateInitialRandomChromosome();
///<summary>/// Selects the surviving chromosomes of the current generation.///</summary>///<returns>Returns a list of survivors of the current generation.</returns>protectedabstract IEnumerable<IChromosome<T>> GetGenerationSurvivors();
The last method that’s implemented in the abstract GeneticAlgorithm class is PerformEvolution. PerformEvolution will create a new population for the next generation. First the survivors of the old generation are selected by calling the GetGenerationSurvivors method, which is to be implemented by a subclass. All survivors of the old generation are automatically added to the new generation population.
Then we’ll select a random survivor based on an weighted average of their fitness. The randomly selected survivor will be mutated, and the result of the mutation is added to the new generation population. The Mutate function may return an arbitrary number of results, so technically a single survivor could be the parent of all children in the new generation.
Finally we set the current population and increment the generation number.
///<summary>/// Performs an evolution by picking up the generation survivors and mutating them.///</summary>publicvoidPerformEvolution()
{
IList<IChromosome<T>> newGeneration = new List<IChromosome<T>>();
// Get the survivors of the last generation
IEnumerable<IChromosome<T>> survivors = GetGenerationSurvivors();
// Add the survivors of the previous generationforeach (var survivor in survivors)
newGeneration.Add(survivor);
// Until the population is full, add a new mutation of any two survivors, selected by weighted random based on their fitness.
Random rnd = new Random();
while (newGeneration.Count < ChromosomePopulationSize)
{
// Get two random survivors, weighted random sort based on fitnessvar randomSurvivor = survivors
.OrderBy(c => rnd.NextDouble() * c.Fitness)
.First();
foreach (var offspring in Mutate(randomSurvivor))
{
if (newGeneration.Count == ChromosomePopulationSize)
break;
newGeneration.Add(offspring);
}
}
// Overwrite current population
ChromosomePopulation = newGeneration;
// Increment the current generation
CurrentGenerationNumber++;
}
The rgb guessing implementation
The actual implementation is a class inheriting from GeneticAlgorithm, specifying Rgb as the generic type we’ll be working with.
class RgbGuesser : GeneticAlgorithm<Rgb>
The constructor just calls the base class directly, specifying the population size to be 100, and that there should be 10 survivors of each generation.
publicRgbGuesser()
: base(100, 10)
{ }
The CreateInitialRandomChromosome method just returns a new Rgb instance with random R, G and B vlaues between 1 and 255.
I’ve implemented an optimization that makes sure the most fit candidate chromosome is always included in the survivors of each generation. This’ll make sure we’ll never have a new generation with a worse candidate solution that the last.
After returning the top candidate, we then return the remaining candidates based on a weighted random selection of the remaining population. The reason why we’re not just returning the “top GenerationSurvivorCount” chromosomes is to avoid premature convergence. Premature convergence is basically a fancy way to describe inbreeding. When our gene pool diversity is limited, so is the range of candidates that may come out of it. It’s not a really big issue in the RGB guessing implementation, but premature convergence can be a big issue in other implementations - especially depending on the mutation implementation.
protectedoverride IEnumerable<IChromosome<Rgb>> GetGenerationSurvivors()
{
// Return the best chromosomevar topChromosome = this.ChromosomePopulation
.OrderByDescending(c => c.Fitness)
.First();
// Return the remaining chromosomes from the poolvar survivors = this.ChromosomePopulation
.Where(c => c != topChromosome)
.OrderByDescending(c => random.NextDouble() * c.Fitness)
.Take(this.GenerationSurvivorCount - 1);
yieldreturn topChromosome;
foreach (var survivor in survivors)
yieldreturn survivor;
}
The final method to implement is the Mutate method. This is the one that’s responsible for mutating a survivor into a new candidate solution that’ll hopefully be better than the last. The implementation is really simple. We just make a new RgbChromosome and set it’s R, G and B values to the same value as the parent chromosome, added a random value between -5 and 5. The Math.Max and Math.Min juggling is to avoid negative and 255+ values.
The final class is the one implementing the IChromosome interface.
class RgbChromosome : IChromosome<Rgb>
In this case I’ve hardcoded a target RGB value that we wish to guess. Note that this is only for demonstrations sake - usually in genetic algorithms we don’t know the “answer” and will therefor have to base the fitness function on a set of rules that evaluate the fitness of the candidate.
private Rgb targetRgb = new Rgb { R = 127, G = 240, B = 50 };
The fitness function calculates the total difference in RGB values and subtracts that from the maximum difference. As a result, we get a fitness value with lower values indicating a worse solution.
publicdouble Fitness
{
get
{
int maxDiff = 255 * 3;
int rDiff = Math.Abs(chromosome.R - targetRgb.R);
int gDiff = Math.Abs(chromosome.G - targetRgb.G);
int bDiff = Math.Abs(chromosome.B - targetRgb.B);
int totalDiff = rDiff + gDiff + bDiff;
return maxDiff - totalDiff;
}
}
Here is the full IChromosome implementation:
class RgbChromosome : IChromosome<Rgb>
{
private Rgb targetRgb = new Rgb { R = 127, G = 240, B = 50 };
private Rgb chromosome;
publicRgbChromosome(int r, int g, int b)
{
this.chromosome = new Rgb { R = r, G = g, B = b };
}
publicdouble Fitness
{
get
{
int maxDiff = 255 * 3;
int rDiff = Math.Abs(chromosome.R - targetRgb.R);
int gDiff = Math.Abs(chromosome.G - targetRgb.G);
int bDiff = Math.Abs(chromosome.B - targetRgb.B);
int totalDiff = rDiff + gDiff + bDiff;
return maxDiff - totalDiff;
}
}
public Rgb ChromosomeValue
{
get { return chromosome; }
}
}
Running the algorithm
Running the algorithm is as simple as instantiating a new RgbGuesser and then calling PerformEvolution on it repeatedly. Note that there’s no built in stop criteria in the algorithm, so it’ll continue to evolve the candidates even though a perfect candidate may already have been evolved. This I’ve introduced a simple check to see whether a perfect candidate exists:
if (topChromosomes.Where(c => c.Fitness == 255 * 3).Count() > 0)
The full code can be seen below:
// Setup RgbGuesser
RgbGuesser rgbGuesser = new RgbGuesser();
// For each generation, write the generation number + top 5 chromosomes + fitnessfor (int i = 1; i < 100000; i++)
{
Console.WriteLine("Generation: " + rgbGuesser.CurrentGenerationNumber);
Console.WriteLine("-----");
// Get top 5 chromosomesvar topChromosomes = rgbGuesser.CurrentGenerationPopulation
.OrderByDescending(c => c.Fitness)
.Take(5);
// Get bottom 5 chromosomesvar bottomChromosomes = rgbGuesser.CurrentGenerationPopulation
.OrderBy(c => c.Fitness)
.Take(5);
if (topChromosomes.Where(c => c.Fitness == 255 * 3).Count() > 0)
{
Console.WriteLine();
Console.WriteLine();
Console.WriteLine();
Console.WriteLine("### Perfect match found at generation " + rgbGuesser.CurrentGenerationNumber + "!");
Console.Read();
return;
}
// Print out top 5 and bottom 5 chromosomesforeach (var chromosome in topChromosomes)
Console.WriteLine(Convert.ToInt32(chromosome.Fitness).ToString().PadLeft(3) + ": " + chromosome.ChromosomeValue);
Console.WriteLine("-----");
foreach (var chromosome in bottomChromosomes.OrderByDescending(c => c.Fitness))
Console.WriteLine(Convert.ToInt32(chromosome.Fitness).ToString().PadLeft(3) + ": " + chromosome.ChromosomeValue);
Console.WriteLine();
Console.WriteLine();
// Homage to Charles Darwin
rgbGuesser.PerformEvolution();
}
Console.WriteLine("Done");
Console.ReadLine();
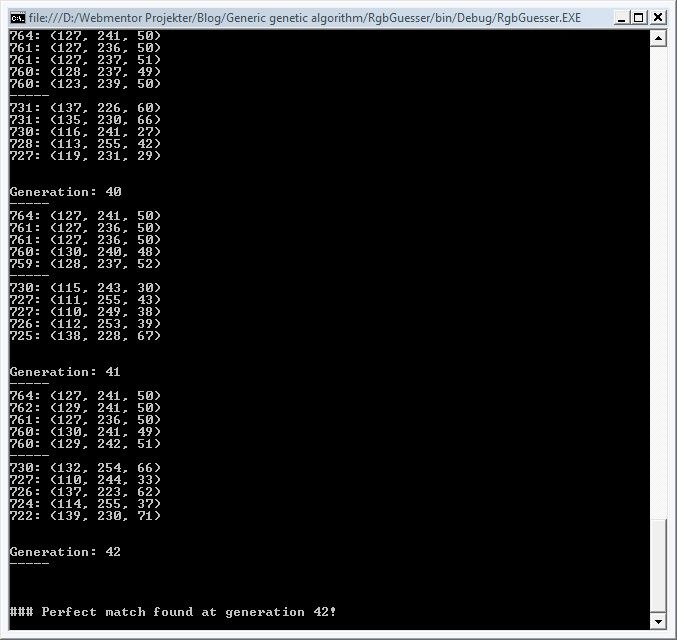
Running the application should eventually result in a perfect candidate being found. If you’re lucky, you’ll find it at generation 42 :)
Doing the numbers
There are different ways of guessing an RGB value. We could just randomly guess until we hit the correct one - with a probability of 1/(255^3).
We could also iterate over all 255^3 solutions, eventually hitting one. Provided the target is completely random, we should hit it after 50% of the solutions have been tested - that is, after just about 8 million tests.
Another more clever approach, given the fitness function would be to just increment each RGB value once and fine the point at which an increment results in a lower score - then we’ve solved one of the RGB values. Using this approach, we can solve the problem in just 255*3 number of tries at most. But really, that’s no fun!
Based on a quick series of tests, 50 seems to be the average max generation we’ll have to hit before we’ve guess the correct RGB value. That’s 50 generations of 100 candidates, for a total candidate count of 5000 - somewhat less than the random guessing and iterative solutions. To conclude - in this case, a genetic algorithm is far from the optimal solution, but it’s an interesting way of approaching hard-to-define problems that may not have a single optimal solution that can be calculated within a certain time restraint. In those cases genetic algorithms can be a great way of approximating a close-to-perfect solution.
I am hastily nearing my third year blogging at improve.dk. Before reinventing my blog, I wrote articles and tutorials at the same address, though in Danish. When I rebooted my blog I completely ditched my old material and started blogging in English. After discussing the concept of blogging a lot recently, I’ve gathered up my thoughts on the subject.
Why blog?
I generally recommend starting a blog to all of my peers. But why do it? There’s no single answer, as it’s very much a subjective matter resulting in different goals.
I recently had a discussion with Daniel from Microsoft Denmark regarding the language of blogs, a discussion that later merged into a discussion on the topic of blogging itself. The discussion originated from a blog post of Daniels (in Danish unfortunately), on why he felt Danish people should blog in Danish. In the following discussion on Twitter, one of Daniels tweets stood out:
danielovich: Why should I write blogposts if no one wanted to read them? Then I would write a word document for myself!
The above was written as answer to a statement I made on the benefits of blogging:
improvedk: You measure benefit only in readers! I benefit by improving my writing skill, using the blog as an incentive to learn new stuff.
These quotes really show the core issue that we were debating, and at the same time explain why we will never agree. We have different goals. Neither goal is superior, though they have vastly different foundations.
As a presenter, your job isn’t to learn things. Your job is to pass on things you’ve already learned.
I absolutely agree with Brent Ozar. As a presenter, your job isn’t to learn things - it’s to pass on the things you’ve already learned. However, this begs the question, am I a presenter? Do I want to be a presenter?
Though I am starting to do more live presentations, I still don’t see myself as a presenter when it comes to my blog.
improvedk: Even if there were nobody to read my blog, I would benefit tremendously by blogging.
When I blog, I do it as a means of improving my own learning ability. If I reach a level of knowledge where I’m able to share that knowledge and explain it so others can understand it, then I know that I’ve understood the material. By forcing myself to blog about new knowledge I acquire, I also force myself to fully understand it, and hence improve my ability to learn.
While broadening my knowledge is the primary goal of my blog, it is of course not the only one. There’s a reason I haven’t put an IP restriction on the blog, why I have an RSS feed, why I’m running Google Analytics. Of course it does provide encouragement, seeing that people actually read what I write. It does confirm to me that my secondary mission of giving something back to the community is working out. Reader, I thank thee.
The choice of language
My native language is Danish, a language that’s quite foreign to the English speaking population of the internet. Given that there’s only about 6 million Danish speaking people in the world, it’s a basic fact that the potential reach of my blog will be humongous when written in English, compared to Danish.
At iPaper, most of our daily communication is in English, both written and spoken. We’re an international company with partners all around the world, and we have employees at our office that don’t speak Danish at all. Thus, speaking English becomes second nature, and why not continue the trend on my blog? After all, being able to speak and write English is not a transient requirement in the industry.
When I search for the solution to a problem, then I search in English through Google
There are just that many more blogs in English out there, the chances of finding a result quickly diminish if I start searching in Danish. I am but a drop in the ocean, there’s a lot of extremely skilled bloggers out there with non-English native languages. I’d be very saddened if they stopped blogging in English. What great blogs am I missing out on at the moment because they’re not written in English?
While I compare Danish and English in this post, I believe my arguments are universal, whether it be Swedish, Hebrew, Finnish etc.
Blogs need not be unique
One final quote from the discussion with Daniel is perhaps the one I oppose the strongest.
danielovich: Yes, if you don’t have anything unique to offer you shouldn’t even try!
danielovich: … And that’s in terms of blogging in English. It will just be pollution in the end!
If your blogging goal is mostly selfish, to improve your own learning ability, then you should not care the least about the uniqueness of your content. Neither should you care about spelling, grammar etc. If you can combine your own goals with producing unique content, then that is of course the ultimate goal, just like improving spelling & grammar should also be a goal itself.
I subscribe to a number of blogs I find interesting, it’s a way for me to keep myself up to date on what’s happening, and to ensure I read the blog entries of the people I admire. For all other content, I find it through Google. As we all know, Google is extremely good at sorting away pollution. Thus, even if your non-unique content could be perceived as pollution, it does not matter! Please do blog, if not for our sakes, then for yours!
I am presenting a session called “Using Network Load Balancing for Availability & Scalability” - I know, original naming is not really part of my skillset. During the session, I will be introducing NLB and demoing how to set it up using a multitude of VMs (might have to get an extra 4 gigs of memory in my laptop). I will also cover some of the basic characteristics scalable & available websites must possess, and how to solve the issue of reliable session state when we start to load balance our webservers - without resorting to SQL Server.
I look forward to attending devLink 2009, it’s an awesome list of sessions & speakers! Hope to see some of you there.
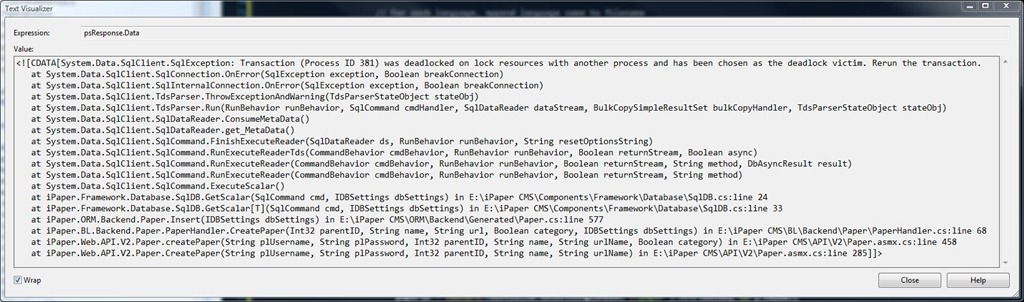
Deadlocks in any database can be a hard beast to weed out, especially since they may hide latently in your code, awaiting that specific moment when they explode. An API website, exposing a series of webservices, had been working fine for months, until I decided to run my client app with a lot more threads than usual.
Great. So we have a deadlock, what’s the first step in fixing it? I’ve outlined the code in PaperHandler.cs that caused the issue, though in pseudo code format:
using (var ts = new TransactionScope())
{
if ((SELECT COUNT(*) FROM tblPapers WHERE Url = 'newurl') > 0)
thrownew UrlNotUniqueException();
// ... Further validation checks
INSERT INTO tblPapers ... // This is where the deadlock occurred
}
To see how the above code may result in a deadlock, let’s test it out in SQL Server Management Studio (SSMS). Open a new query and execute the following, to create the test database & schema:
-- Create new test database - change name if necessaryCREATEDATABASE Test
GO
USE Test
-- Create the test tableCREATETABLE tblPapers
(
ID intidentity(1,1) NOTNULL,
Url nvarchar(128) NOTNULL
)
-- Make the ID column a primary clustered keyALTERTABLE dbo.tblPapers ADDCONSTRAINT PK_tblPapers PRIMARYKEY CLUSTERED
(
ID ASC
)
ON [PRIMARY]
-- Add a nonclustered unique index on the Url columnto ensure uniqueness
CREATEUNIQUE NONCLUSTERED INDEX NC_Url ON tblPapers
(
Url ASC
)
ON [PRIMARY]
The tblPapers table contains a number of entities, and each of them must have a unique Url value. Therefore, before we insert a new row into tblPapers, we need to ensure that it’s going to be unique.
Now open two new query windows and insert the following query text into both of them:
USE Test
SETTRANSACTIONISOLATIONLEVEL SERIALIZABLE
BEGIN TRAN
-- Ensure unique URL
DECLARE @NewUrl varchar(128);SET @NewUrl = 'newurl'SELECTCOUNT(*) FROM tblPapers WHERE Url = @NewUrl
-- Insertrowif above query returned 0 <=> URL isuniqueDECLARE @NewUrl varchar(128);SET @NewUrl = 'newurl'INSERTINTO tblPapers (Url) VALUES (@NewUrl)
In SQL Server 2005/2008, READ COMMITTED is the default transaction level - we’re being explicit about using the SERIALIZABLE isolation level, however. The reason we’re going to use the SERIALIZABLE isolation mode is that while READ COMMITTED is the default mode in SQL Server, whenever you create an implicit transaction using TransactionScope, it’s using the SERIALIZABLE isolation mode by default!
Now, observe what happens if you run two queries concurrently in the following order:
Query A
USE Test
SETTRANSACTIONISOLATIONLEVEL SERIALIZABLE
BEGIN TRAN
Query B
USE Test
SETTRANSACTIONISOLATIONLEVEL SERIALIZABLE
BEGIN TRAN
Query A
-- Ensure unique URL
DECLARE @NewUrl varchar(128); SET @NewUrl = 'newurl'SELECTCOUNT(*) FROM tblPapers WHERE Url = @NewUrl
Query B
-- Ensure unique URL
DECLARE @NewUrl varchar(128); SET @NewUrl = 'newurl'SELECTCOUNT(*) FROM tblPapers WHERE Url = @NewUrl
Query A
-- Insert row since URL is unique
DECLARE @NewUrl varchar(128); SET @NewUrl = 'newurl'INSERTINTO tblPapers (Url) VALUES (@NewUrl)
Query B
-- Insert row since URL is unique
DECLARE @NewUrl varchar(128); SET @NewUrl = 'newurl'INSERTINTO tblPapers (Url) VALUES (@NewUrl)
After executing the last query, you should get the following error in one of the windows:
Msg 1205, Level 13, State 47, Line 4
Transaction (Process ID 53) was deadlocked on lock resources with another process and has been chosen asthe deadlock victim. Rerun thetransaction.
While in the second window, you’ll notice that the insertion went through:
(1 row(s) affected)
What happened here is that the two transactions get locked up in a deadlock. That is, neither one of them could continue without one of them giving up, as they were both waiting on a resource the other transaction had locked.
But what happened, how did this go wrong? Isn’t the usual trick to make sure you perform actions in the same order, and you’ll avoid deadlocks? Unfortunately it’s not that simple, your isolation level plays a large part as well. In this case we know which queries caused the deadlock, but we could’ve gotten the same information using the profiler. Perform a rollback of the non-victimized transaction so the tblPapers table remains unaffected.
Startup the profiler and connect to the database server. Choose the TSQL_Locks template:
Make sure only the relevant events are chosen, to limit the amount of data we’ll be presented with. If necessary, put extra filters on the database name so we avoid queries from other databases. You can also filter it on the connection ID’s from SSMS if necessary:
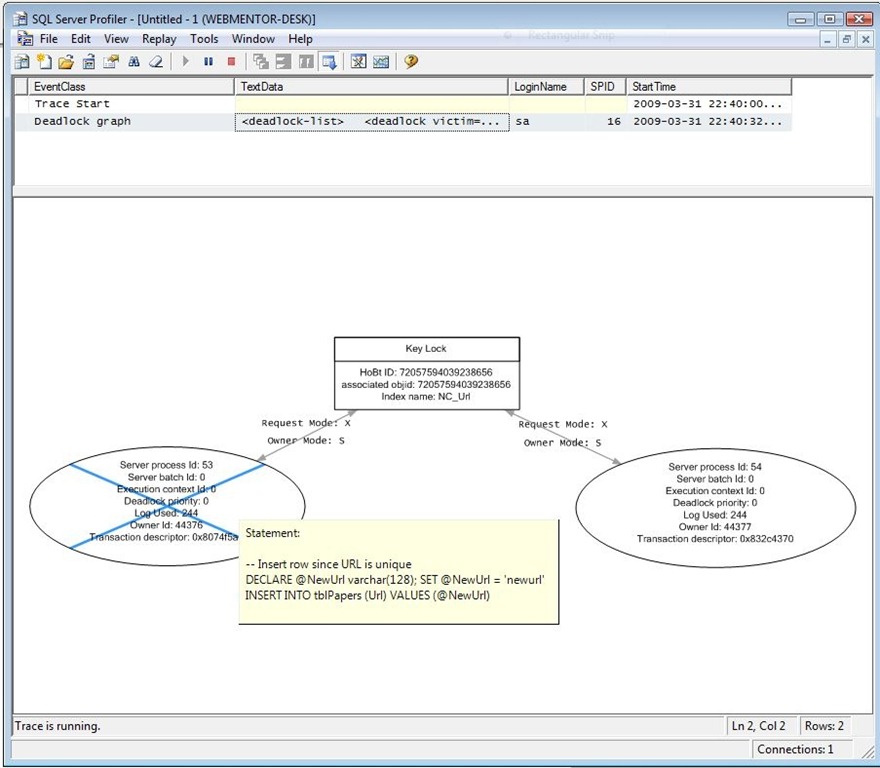
If we run the profiler in the background while executing all steps in SSMS in the meantime, we’ll notice a an important event in the profiler, the Deadlock graph. If we hover the mouse over either of the circles representing the two individual processes, we’ll get a tooltip showing the exact query that was run when the deadlock occurred - the two insert queries:
Ok, so now that we know what step caused the deadlock, the question now is, why did it occur? Perform a rollback of the non-victimized transaction. Now run step 1-3 again, and run the following query in window A:
sp_lock @@SPID
The result should resemble this (ID’s will be different):
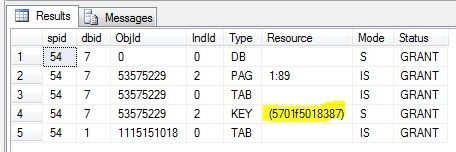
Notice the highlighted object ID. Now right click on the deadlock graph in the profiler results table and select “Extract event data”. Save the file somewhere and open it in Visual Studio (as XML).
What these lines tells us is that both processes are waiting on the same resource, namely 5701f5018387. Looking at our sp_locks result from before, we can see that that particular resource has a shared lock (S) on it.
And this brings us down to the core issue - the SERIALIZABLE isolation mode. Different isolation modes provide different locking levels, serializable being one of the more pessimistic ones. SERIALIZABLE will:
Request shared locks on all read data (and keep them until the transaction ends), preventing non-repeatable reads as other transactions can’t modify data we’ve read.
Prevent phantom reads - that is, a SELECT query will return the same result even if run multiple times - other transactions can’t insert data while we’ve locked it. SQL Server accomplishes this by either locking at the table or key-range level.
If we look at the Lock Compatibility chart.aspx), we’ll see that “Shared (S)” locks are compatible with other S & IS (Intent Shared) locks. This means both of the processes are able to perform a shared lock on the initial SELECT COUNT(*) key range. When the INSERT statement is then performed, the database will then attempt to get an exclusive (X) lock on the data - but since the other process has a shared lock, we’ll have to wait for it to be released. When the second process tries to perform an INSERT as well, it’ll try to get an exclusive lock on the same data. At this point we have two processes that both have a shared lock on the same piece of data, and they both want an exclusive lock on the data. The only way to get out of this situation is to dedicate one of the transactions as a victim and perform a rollback. The unaffected process will perform the INSERT and will be able to commit.
How do we then get rid of the deadlock situation? We could change the isolation mode to the default READ COMMITTED like so:
var tsOptions = new TransactionOptions();
tsOptions.IsolationLevel = IsolationLevel.ReadCommitted;
using (var ts = new TransactionScope(TransactionScopeOption.Required, tsOptions))
{
...
ts.Complete();
}
However, that will result in another problem if we run the same steps as before:
Msg 2601, Level 14, State 1, Line 3
Cannot insert duplicate key row in object 'dbo.tblPapers' withuniqueindex 'NC_Url'.
The statement has been terminated.
As READ COMMITTED does not protect us against phantom reads, it won’t take shared locks on read data. Thus the second process is able to perform the insert without us knowing (we still think COUNT(*) is = 0). As a result, we’ll fail by violating the unique NC_Url index constraint.
What we’re looking for is an even more pessimistic isolation level - we not only need to protect ourselves against phantom reads, we need to protect against locks on the same data as we’ve read (we don’t care if someone reads our data using READ UNCOMMITTED, that’s their problem - as long as they don’t lock our data). However, SERILIZABLE is the most pessimistic isolation level in SQL Server, so we’re outta luck. That is… Unless we use a locking hint.
Locking hints tell the database engine what kind of locking we would like to use. Take note that locking hints are purely hints - they’re not orders. In this case however, SQL Server does obey our command. What we need is the UPDLOCK hint. Change the query so it includes an UPDLOCK hint in the first SELECT statement:
-- Ensure unique URL
DECLARE @NewUrl varchar(128); SET @NewUrl = 'newurl'SELECTCOUNT(*) FROM tblPapers (UPDLOCK) WHERE Url = @NewUrl
The UPDLOCK hint tells SQL Server to acquire an update lock on the key/range that we’ve selected. Since shared locks and update locks are not compatible, the second process will have to wait until the first transaction either commits or performs a rollback. The second process won’t return the result of the first SELECT COUNT(*) query until the first process is done - or a timeout occurs.
Note that while this method protects us against the deadlocks & constraint violations, it does so at the cost of decreased concurrency. This will result in other operations being blocked until the insertion procedure is done. In my case, this is a rather rare procedure, so it does not matter. One way to alleviate this problem would be to use the READ COMMITTED SNAPSHOT isolation level in other parts of the application where it’s applicable. YMMV!
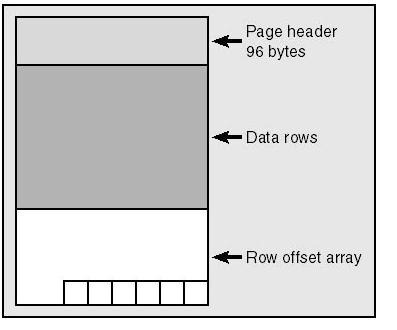
SQL Server stores all of it’s data in what is basically a large array of “pages”. Each page is exactly 8kb and can contain various kinds of data, depending on the page type. In this entry we’ll explore how to decipher a data page.
As mentioned, all data in SQL Server is stored in pages, this includes data, index data and various other page types (GAM/SGAM/IAM/PFS etc) to support the operations of SQL Server. Each page type has a unique page content and will thus require separate analysis to understand their content. In this entry I’ll concentrate on a normal data page, that is, the pages that contain the data of either heap tables or clustered indexes.
A page has a basic structure consisting of a header, the actual page content and finally an array noting the locations of the individual rows in the content section.
First of all, we need to create a new empty database for this to work:
CREATEDATABASE Test
To make it easier to reset & redo the examples, you should start a new transaction by running “BEGIN TRAN” as the first command (I’m assuming you’re running these queries in SSMS). When you want to reset / start over, just run “ROLLBACK” and nothing will be saved.
First we will look at the structure of data pages for a heap table. We’ll create a simple table containing only a single int (identity) field:
CREATETABLE tmp
(
ID intidentity(1,1)
)
Now, let’s insert 2 rows into the table:
INSERTINTO tmp DEFAULTVALUESGO2
If you do a SELECT on the tmp table at this point, you should get two rows with values 1-2 in the ID column. At this point we want to retrieve a list of the pages used to store the contents of the tmp table. We can do this by using the undocumented DBCC IND command:
DBCC IND(Test, tmp, -1)
The first parameter is the database name, Test in our case. The next parameter is the name of the table, while the last parameter is an index ID - using -1 as the ID will return all indexes, which is fine in our case. Running the above command should yield a result like the one below:
The only two important columns at this point are the PagePID, IAMPID and PageType columns. PagePID is the unique (within this database file) page ID for a specific page. IAMPID defines a parent/child relationship between pages. PageType defines the type of page that we’re looking at. The most common page types you’ll run into are:
At this point we’re interested in the root IAM (page type = 10) page with page ID 119. This is the root page of our heap table index. This is the page that currently tracks all of the data pages belonging to the tmp table. Currently there’s only one IAM page, but if necessary, there can be multiple nested IAM pages to support more data pages than can be referenced on a single IAM page.
The root page has a NULL IAMPID, signaling that it doesn’t have any parent pages. The second page has an IAMPID of 119 - the ID of the root page. Thus the second page is a child page of the root page. We can also see that the second page is a data page since it’s page type is = 1. Notice the page ID of the second page, as both the root and child page ID’s will most likely be different in your test!
Before we can retrieve the contents of the page, we have to turn on a specific trace flag, otherwise we won’t see any results of the following command, as they’re sent only to the error log by default:
DBCC TRACEON(3604)
After the trace flag has been turned on, we’re ready to run the undocumented DBCC PAGE command. The DBCC PAGE command takes four parameters, the first one being the database name. The second is the file number in the database - this will be 1 since there’s only a single file per database by default. The third parameter is the page ID we want to analyze - notice that this varies and will most likely be different in your situation. The final parameter defines the level of detail (0-3) to be included in the output. The most common levels are 0 and 1, 0 outputting only the header values while 1 also includes the actual row data.
I’ll elegantly jump over the buffer & header parts as they’re begging for posts on their own, and I can’t realistically show them the respect they need in this post. Instead we’ll concentrate on the DATA & OFFSET TABLE parts.
Let’s start out from the bottom up and look at the OFFSET TABLE:
Notice that it should be read from the bottom up as well, row 0 being the first, 1 being the second. The row offset table is basically an integer array pointing out the to locations in the 8KB page of the individual row locations. As we have two rows in our table, and they both fit on this page, there’s two entries in the offset table. The first row starts at byte index 96 - the first byte after the 96 byte header. The second row starts at index 107, 11 bytes after the first row. Let’s take a look at the first row (the rows are identical):
Slot0, Offset0x60, Length11, DumpStyle BYTE
Record Type = PRIMARY_RECORD RecordAttributes = NULL_BITMAP
Memory Dump @0x000000000B05C0600000000000000000: 10000800010000000100fe†††††††††††††...........
The first row has slot 0, it’s offset is 0x60 (96) and we already know the length is 11 bytes, from the offset table. Let’s take a look at the rows actual content, to understand what is stored.
10000800 01000000 0100FE The first byte is a status byte that contains info on how to parse the row contents. The value 0x10 defines the inclusion of a NULL_BITMAP, as indicated by the record attributes.
10000800 01000000 0100FE The next byte is currently (MSSQL2005) unused, but may be used in future versions.
10000800 01000000 0100FE The next two bytes store the byte index position of where to find the number of columns in this row, within the rows data. SQL Server stores numbers with the low order byte first, so the bytes must be switched around to get the position. Thus 0x0800 becomes 0x0008 (8 in decimal).
10000800 01000000 0100FE The next four bytes are the contents of the first column, a four byte integer. This is our identity column, and you’ll notice that the first row has a value of 0x00000001 while the second has a value of 0x00000002.
10000800 01000000 0100FE The next two bytes store the number of columns. Notice that this is stored at byte index 8, as indicated by the third and fourth bytes in the row.
10000800 01000000 0100FE Finally the null bitmap is stored in the last byte. 0xFE converted to binary is 1111 1110, indicating that the first column value is not null (the first 0, read backwards). The rest have a default value of 1, actually indicating that it is null. But since there’s only one column, these bits are never read. Note that one byte in the null bitmap can support up to 8 columns. The formula for determining the null bitmap size is (#cols+7)/8, using integer division.
Let’s do a rollback and create a new table with a slightly changed schema and values:
CREATETABLE tmp
(
ID int
)
CREATE CLUSTERED INDEX CI ON tmp (ID)
INSERTINTO tmp (ID) VALUES (1)
GO2
We still have a single ID column, but this time it’s not an identity column, and we’re manually inserting the value “1” into the column. Thus both rows will have the same value. If we runn DBCC IND to get the page id, and then DBCC PAGE on the data page, we’ll get the following two rows:
Slot0, Offset0x60, Length11, DumpStyle BYTE
Record Type = PRIMARY_RECORD RecordAttributes = NULL_BITMAP
Memory Dump @0x000000000D90C0600000000000000000: 10000800010000000200fc†††††††††††††...........
Slot1, Offset0x6b, Length19, DumpStyle BYTE
Record Type = PRIMARY_RECORD RecordAttributes = NULL_BITMAP VARIABLE_COLUMNS
Memory Dump @0x000000000D90C06B0000000000000000: 30000800010000000200fc01 00130001 †0...............
0000000000000010: 000000†††††††††††††††††††††††††††††††...
The first row is almost identical to the last. It’s still 11 bytes long and its status bits indicate there’s only a null bitmap. One thing has changed however.
10000800 01000000 0200FC The number of columns indicater now has a value of 0x0002, indicating there is now two columns. How can that be? We only defined one column, and the row length is still 11 bytes.
If we take a look at the second row, we’ll see that the length is 19 bytes, an extra 8 bytes. Furthermore, the status byte has changed its value to 0x30, indicating there’s both a null bitmap, as well as a “variable columns” section. Take a look at the row data (note that I’ve concatenated the two lines to make it more readable):
30000800 01000000 0200FC01 00130001 000000 Obviously the value in this row is also 1, meaning both rows have the same value in the clustered index.
30000800 01000000 0200FC01 00130001 000000 The null bitmap has changed into the value 0xFC or 1111 1100, indicating that the first two (in other words, all) columns do not have null values.
30000800 01000000 0200FC01 00130001 000000 The last four bytes is a “uniqueifier” value that is added since the clustered key value is identical for multiple rows. Why wasn’t this added before? On the first table we didn’t define a clustered index, and therefore it was a heap table. In heap tables, pages are referenced by their phyiscal location and not their clustered key value. In a clustered table, rows are always referenced by their clustered key value. To uniquely reference a column, it’s important that each clustered key value is unique (which is why the clustered key is usually also the primary key, as is also the default in SSMS). If a clustered key is not unique, SQL Server adds its own uniqueifier value that makes the key unique - note that this only occurs when necessary, thus the lack of a uniqueifier on the first row, since that one is already unique. The uniqueifier is treated as a variable length column as we can potentially have more than 2^31-1 rows with the same value, at which point the uniqueifier will have to utilize eight bytes to ensure unique clustered key values.
30000800 01000000 0200FC01 00130001 000000 The previous four bytes are used to support the variable length column(s) in the row. The first two bytes indicate the number of variable length columns in the row (0x0001 - the single uniqueifier column), while the second pair of bytes indicate the end index of the first variable length column, that is 0x0013 (19 in decimal, which is also the total length of the row).
To elaborate on the variable length columns, consider the following table and values:
30000400 0200FC02 000f0011 00610062 00 The first bytes are used for the status & unused bytes, as well as the “number of columns” index.
30000400 0200FC02 000f0011 00610062 00 The next two bytes at index 0x0004 indicate there’s two columns.
30000400 0200FC02 000f0011 00610062 00 The null bitmap indicates that no columns have null values.
30000400 0200FC02 000f0011 00610062 00 The next two bytes indicate the number of variable length columns, 0x0002.
30000400 0200FC02 000f0011 00610062 00 The next two bytes indicate the ending position of the first variable length column, 0x000f (15).
30000400 0200FC02 000f0011 00610062 00 Likewise, the next two bytes indicate the ending position of the second variable length column, 0x0011 (17). If there were more variable length columns, each one of them would have a two-byte length indicator here, before the actual contents.
30000400 0200FC02 000f0011 00610062 00 After the variable length column end index indicators, the actual content is stored. We know that the first variable length column value ends at index 15, which gives us the value 0x0061 which happens to be a lowercase ‘a’.
30000400 0200FC02 000f0011 00610062 00 Likewise, we know that the second column ends at index 17, giving us the value 0x0062, being a lowercase ‘b’.
As a final example, let’s look at what happens when we have null values in our columns.
Slot0, Offset0x60, Length17, DumpStyle BYTE
Record Type = PRIMARY_RECORD RecordAttributes = NULL_BITMAP VARIABLE_COLUMNS
Memory Dump @0x000000000DB0C0600000000000000000: 300004000200fc02 000f0011 00610062 †0............a.b
0000000000000010: 00†††††††††††††††††††††††††††††††††††.
Slot1, Offset0x71, Length15, DumpStyle BYTE
Record Type = PRIMARY_RECORD RecordAttributes = NULL_BITMAP VARIABLE_COLUMNS
Memory Dump @0x000000000DB0C0710000000000000000: 300004000200fd02 000d000f 006200††††0............b.
Slot2, Offset0x80, Length13, DumpStyle BYTE
Record Type = PRIMARY_RECORD RecordAttributes = NULL_BITMAP VARIABLE_COLUMNS
Memory Dump @0x000000000DB0C0800000000000000000: 300004000200fe01 000d0061 00††††††††0..........a.
Slot3, Offset0x8d, Length9, DumpStyle BYTE
Record Type = PRIMARY_RECORD RecordAttributes = NULL_BITMAP
Memory Dump @0x000000000DB0C08D0000000000000000: 100004000200ff00 00†††††††††††††††††.........
As a proof of SQL Server only adding fields when needed, there are no variable_columns attributes in the fourth row, since both columns are null and we therefore do not need to keep track of the length of the columns.
30000400 0200FC02 000F0011 00610062 00 The first row is identical to what we saw before.
30000400 0200FD02 000D000F 006200 In the second row the null bitmap is different: fd (1111 1101), indicating that the first column is null. We can also see that there’s two bytes missing from the row (0x0061) compared to the first row. 0d00 indicates that the first variable length column ends at index 0x000d (13), while the second variable length column ends at index 0f00 / 0x000f / 15. What’s interesting is that the variable column length indicators themselves end at index 13, and thus the first row ends where it starts - that is, it’s not there at all, it’s null. The second column is stored at index 14 + 15, the 6200 / 0x0062 / ‘b’ value.
30000400 0200FE01 000D0061 00 The third row takes up two bytes less, even though it has only a single null field like the second row. The null bitmap is slightly different (fe / 1111 1110) since it’s now the second column that’s null. What’s interesting is that in this row, only a single variable length column is present, not two. Thus there’s only a single variable length column end index identifier, 0d00 / 0x000d / 13. From that we can conclude that columns are handled in order, and thus one might want to consider the order of columns, if a specific column is usually null, it might be more efficient to have it ordered last.
10000400 0200FF00 00 The fourth row takes up just 9 bytes, this time sparing the data of both variable length columns since they’re both null according to the null bitmap (ff / 1111 1111).
Conclusion
By using the undocumented DBCC commands IND and PAGE, we can get the actual page data from any page in the database.
SQL Server uses a fixed and deterministic row layout, depending on the table metadata and column contents.
By understanding the way SQL Server stores data, we’re able to optimize our storage even further than we would normally be able to.
Data pages are just one of many page types in SQL Server. Later on, I might introduce other page types.
Yesterday I did an interview with Søren Spelling Lund for ANUG (Aarhus .NET User Group) on SQL Server Optimization, as a followup to my recent talk on that subject. He asked me an interesting question - what is the normal process of determining the need of an optimization, and how to actually do it? This is a case study from today.
The issue started out by one of the sales people telling me the catalogs were loading slowly. Being a limited number of people in a small office, my usual first resolution is to simply ask if anyone in the office are downloading/uploading files, since that’ll usually exhaust our rather limited network connection. Unfortunately, that was not the reason. Next step - locate the exact location of the issue. I asked which catalogs specifically were loading slowly, and whether it was all of it loading slowly, just the images or anything else that might narrow down the issue.
The response was quite a bit more precise than I’d hoped for:
So it wasn’t a matter of things loading slowly… It was a matter of things not loading at all! Funny thing is, during the ANUG interview, Søren asked me how one could detect when optimizations were needed - part of my answer was “When SqlCommands start timing out”.
Armed with a precise error message and the location of the error, I detected the exact operation that caused the timeout. It’s a simple statistics page, showing the number of page views during the last 7 days - nothing exotic, but yet it failed.
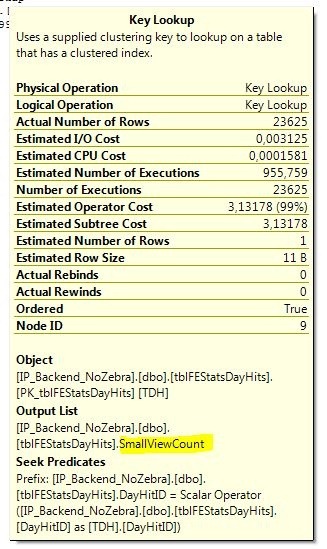
SELECTSUM(TDH.SmallViewCount)
FROM
tblFEStatsDayHits TDH
INNERJOIN
tblFEStatsDays TD ON TD.DayID = TDH.DayID
WHERE
TDH.PaperID = 304275AND
DATEDIFF(dd, TD.Day, GETDATE()) < 7
The query is rather basic, it tries to sum up the SmallViewCount (containing the number of views of a single page) from the table tblFEStatsDayHits. This table has a reference to the helper table tblFEStatsDays, containing a single row per day. Thus tblFEStatsDays is a very small table which is only used for getting the actual day this event occurred on. We filter on a PaperID (which is basically a specific catalog) as well as on DATEDIFF(dd, TD.Day, GETDATE()) being below 7 - making sure we only consider data for the last 7 days. So given a rather simple query, how can this be so bad?
This confirms that tblFEStatsDays isn’t of interest to us since it only had 10 page reads. tblFEStatsDayHits on the other hand had 484959 page reads. That’s around 3,7 (484959 * 8KB per page) gigs of data being read. Though it’s logical reads (that is, from memory), that’s still an insane amount, especially since they’re most likely physical reads the first time they’re read. The database server is running on a RAID1 15k SAS mirror, giving us at most about 150MB/sec of IO performance - ignoring any other active tasks. That’s about 25 seconds of uninterrupted IO read time - that’s bound to blow up at some point.
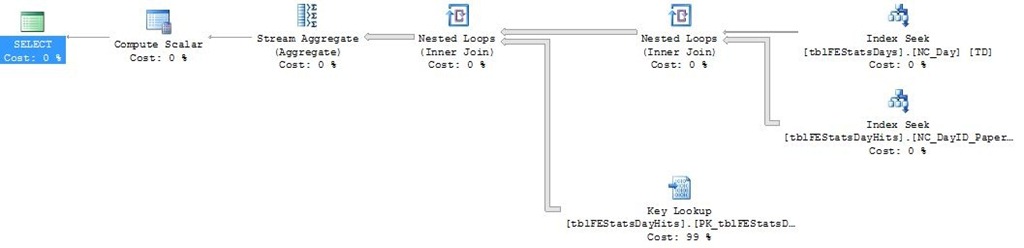
Let’s look at the execution plan:
This pretty much confirms the issue lies in the Clustered Index Scan - which is more or less the last operation you want to see in an exceution plan. It represents a complete read of the whole clustered index - an operation that scales rather linearly with the amount of data you have in your tables. So how big is this table?
It’s got a bit short of 60M rows, 3,7 gigs of data (matching up to our 3,7 gig read earlier), and an additional ~3 gigs of extra index data. Clearly, if this operation is to be fast, we need to use indexes wisely so we avoid reading all of this data.
If we look at the execution plan in SQL Server Management Studio 2008 (won’t work in SMS2005), it’ll actually give us a recommendation for a specific index that it could’ve used:
CREATE NONCLUSTERED INDEX
[<Name of Missing Index, sysname,>]
ON
[dbo].[tblFEStatsDayHits] ([PaperID])
INCLUDE
([DayID],[SmallViewCount])
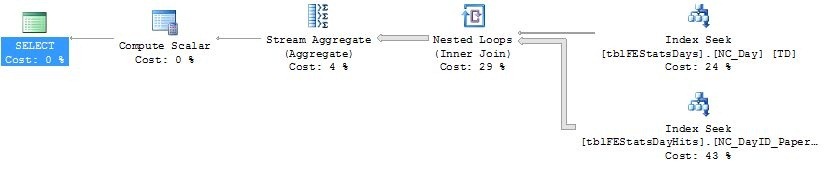
That specific index would allow us to filter on the PaperID while including the DayID and SmallViewCount columns at the leaf level. The PaperID column has a rather high cardinality, so by filtering on that, we’ve already reduced the data amount considerably. SMS predicts adding this index will optimize the query by about 99% - sounds good, let’s try:
CREATE NONCLUSTERED INDEX [NC_PaperID] ON [dbo].[tblFEStatsDayHits]
(
[PaperID] ASC
)
INCLUDE
(
[DayID],
[SmallViewCount]
)
After adding the index and rerunning the query, these are the new IO statistiscs:
We’re down from 484959 to only 1770 page reads, that’s an optimization of 99,6%, not too shabby. Let’s look at the new execution plan:
Comparing the two plans reveals that we’ve now replaced that nasty clustered index scan with an index seek - one of the most efficient operations that exist. Now most of the time is spent in the parallelism/hash match operations. These operations make individual sums of the SmallViewCount column for all rows with the same DayID value. It’s running on multiple threads as indicated by the presence of a parallelism operator.
Now, we’re still spending quite a lot of time reading in all of the rows for that specific PaperID and grouping them together by DayID. If a catalog has been having visitors for a year, that’s basically 358 extra days of data we’re reading in for no reason. How about if we change the query to this semantically identical one (given that it’s the 12th of March 2009, 09:52 AM):
SELECTSUM(TDH.SmallViewCount)
FROM
tblFEStatsDayHits TDH
INNERJOIN
tblFEStatsDays TD ON TD.DayID = TDH.DayID
WHERE
TDH.PaperID = 304275AND
TD.Day > '2009-03-12 09:52:00'
What does this change give us? The “DATEDIFF(dd, TD.Day, GETDATE()) < 7” predicate requires SQL Server to look at each row, performing the DATEDIFF operation to determine whether it should be part of hte final sum aggregate. Doing it this way severely limits the usability of our indexes since we can no longer make an index seek on the Day column. If we from the application instead take the current date and subtract 7 days, that’s basically the cutoff point that we’re interested in. Thus we’ve now changed the predicate to only select columns with a Day value higher than the current date minus 7 days.
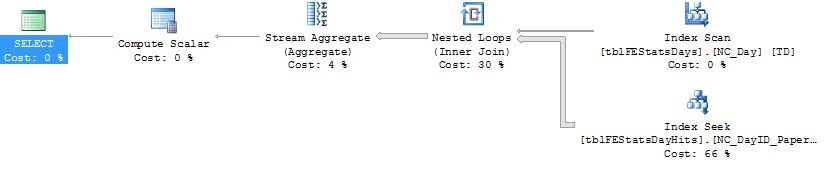
Take a look at the resulting execution plan:
It’s dramatically simpler. One important point is that if we look at the index seek on tblFEStatsDayHits, it’s now using the index called NC_DayID_PaperID! This is not the one we made just before, this is another lingering index on the table. Let’s look at it’s definition:
CREATE NONCLUSTERED INDEX [NC_DayID_PaperID] ON [dbo].[tblFEStatsDayHits]
(
[DayID] ASC,
[PaperID] ASC
)
Why is it suddenly using this index? To understand, we first have to know what’s actually happening. The whole process has been turned upside down compared to the last plan. In the last plan, we first read in the actual data filtered by PaperID, and then we filtered on the relevant days. Now we’re first finding the relevant DayIDs by joining the tblFEStatsDays table with the NC_DayID_PaperID index, and for each relevant row, we perform a bookmark lookup in the tblFEStatsDayHits table. So why is it not using the NC_PaperID index we made just before? NC_PaperID had a single index column and two included ones (and the implicitly contained clustered key, which is irrelevant as it’s also included in the NC_DayID_PaperID index). Thus, NC_PaperID has three int columns, totalling at 12 bytes of index data per row. The NC_DayID_PaperID only has two keys - PaperID and DayID, totalling at 8 bytes per row. If we add the implicit 4 bytes for the clustered key, thats 16 and 12 bytes per row. With a page size of 8060 bytes of index data, that’s either 503 rows per page or 671 rows per page. That’s about 30% IO saved by using the smaller index. Let’s take a look at the IO statistics for this plan:
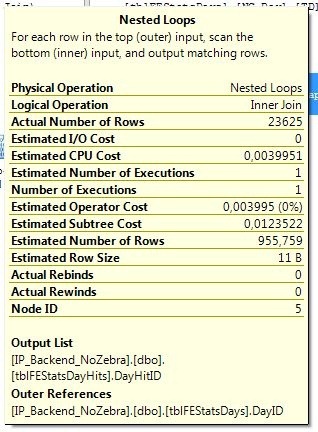
Now what happened here? We went from 1770 page reads to just short of 100K reads! If we hover our mouse on the nested loops step of the query plan, we can see there’s about 23,5K rows being returned:
Thus, for each of those 23,5K rows, we have to perform a bookmark lookup in the tblFEStatsDayHits table, that’s about 4 page lookups per resulting row (since the predicate at this point is a DayID, there may be several relevant rows in the tblFEStatsDayHits table, thus the large amount of page reads). The only reason that this is still reasonably fast is that all the pages are already present in memory, so this is a pure CPU operation. But having 100K pages (100000 * 8KB = ~780MB) of data in memory just for this purpose is definitely not optimal! Granted, there’s most likely a lot of reuse in these pages, so the sum may not be 780MB’s (we’d have to count the number of unique pages that were needed for that), but it’s bad nonetheless.
If we hover the mouse on the bookmark lookup operator, we get some extra information:
If we look at the output section, we see that the only column that’s actually being returned from these bookmark lookups is the SmallViewCount column. Given that we’re already using the NC_DayID_PaperID index, how about we add the SmallViewCount column as an included column in that index:
CREATE NONCLUSTERED INDEX [NC_DayID_PaperID] ON [dbo].[tblFEStatsDayHits]
(
[DayID] ASC,
[PaperID] ASC
)
INCLUDE ([SmallViewCount])
Let’s check the execution plan again:
Now we’re starting to get somewhere! Now we’re doing two highly effective index seeks on the tblFEStatsDayHits and tblFEStatsDays tables before we join them together. Let’s take a look at the IO statistics as well:
83 page reads! If we compare that to the original 484959 page reads, that’s an optimization of 99,982%! A query that took upwards of 30 seconds now takes milliseconds. There’s the added reward of having to cache less data in memory (thereby allowing other more important data to stay in memory) and reducing IO load considerably.
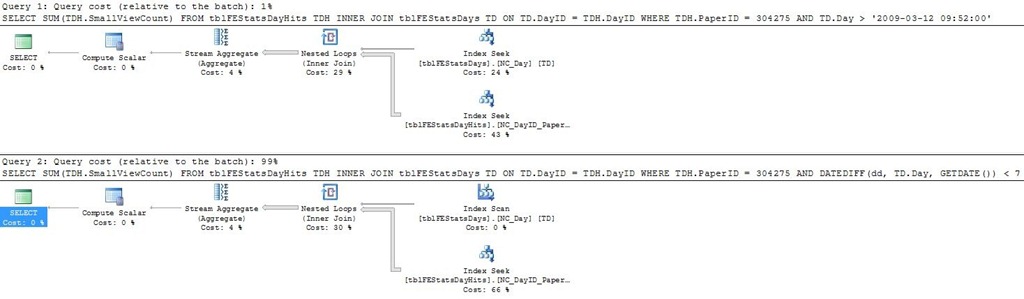
Let’s for the kicks of it try and run the original DATEDIFF() query and see the resulting execution plan:
Using the function predicate requires us to scan the whole tblFEStatsDays.NC_Day index, instead of performing a seek. If we run both queries alongside in SMS, we can see a rather large performance advantage of the non-DATEDIFF query (1 : 99 performance ratio):
Conclusion
Locate the exact cause of the issue before optimizing.
Do consider SMS’s (and other tools for that sakes) suggestions, but don’t take for granted that it’s the best solution!
Just because a query plan looks simple, check out the IO statistics to get a better feeling for what actually happens.
Avoid using functions & other advanced predicates that avoid you from taking advantage of your indexes.
Watch out for your query changing mind about what indexes to utilize when you make changes to the query.
Tonight I held my SQL Server Optimization talk at ANUG. There was an impressive turnout of almost 50 people, and based on the feedback I’ve received so far, I think it went alright :)
You can download the slides, code and sample database (with sample data) below. Note that slides are in Danish.
I’m afraid the query scripts are not in text format, they’re only included as images in the slides. I’ll probably be presenting some of the topics on my blog over time, where the scripts will also be included.