In just a couple of weeks SQLSaturday #196 will be happening on April 20th in Copenhagen, Denmark. This is a free day smack-filled with great speakers, many of them international! Just check out the schedule.
I cannot recommend attending SQLSaturdays enough, especially so if they’re close to you. Whether you’re a SQL Server or .NET developer, DBA or a BI person, there’s relevant content for you. Looking beyond the schedule, SQLSaturdays are excellent networking opportunities where people from very different business areas meet and mingle.
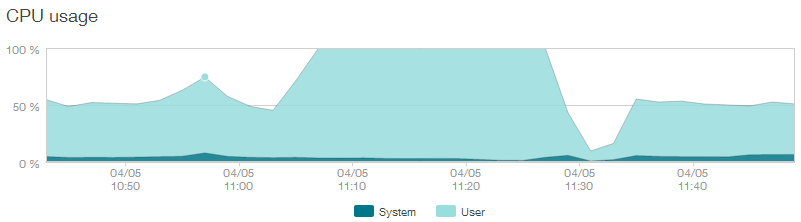
This is the story of how a simple oversight resulted in a tough to catch bug. As is often the case, it worked on my machine and only manifested itself in production on a live site. In this series we will look at analyzing 100% CPU usage using Windbg.
The Symptom
Some HTTP requests were being rejected by one of our servers with status 503 indicating that the request queue limit had been reached. Looking at the CPU usage, it was clear why this was happening.
Initially I fixed the issue by issuing an iisreset, clearing the queue and getting back to normal. But when this started occurring on multiple servers at random times, I knew there was something odd going on.
Isolating the Server and Creating a Dump
To analyze what’s happening, I needed to debug the process on the server while it was going on. So I sat around and waited for the next server to act up, and sure enough, within a couple of hours another one of our servers seemed to be stuck at 100% CPU. Immediately I pulled it out of our load balancers so it wasn’t being served any new requests, allowing me to do my work without causing trouble for the end users.
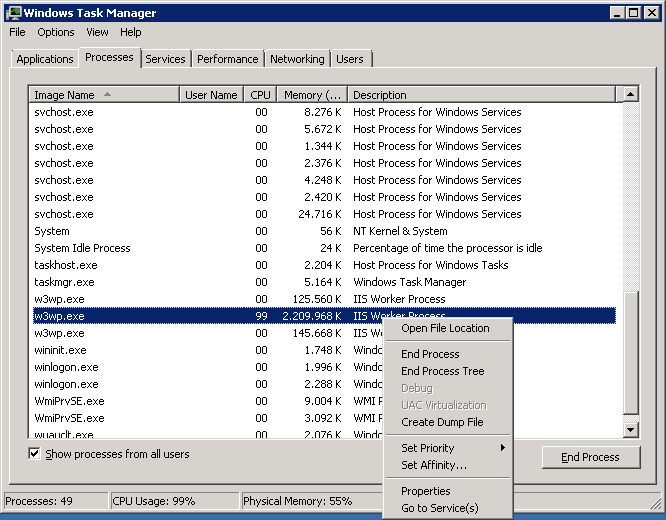
In server 2008 it’s quite easy to create a dump file. Simply fire up the task manager, right click the process and choose “Create Dump File”.
Do note that task manager comes in both an x64 and an x86 version. If you run the x64 version and make a dump of an x86 process, it’ll still create an x64 dump, making it unusable. As such, make sure you use whatever task manager that matches the architecture of the process you want to dump. On an x64 machine (with Windows on the C: drive) you can find the x86 task manager here: C:\Windows\SysWOW64\taskmgr.exe. Note that you can’t run both at the same time, so make sure to close the x64 taskmgr.exe process before starting the x86 one.
Once the dump has been created, a message will tell you the location of the .DMP file. This is roughly twice the size of the process at the time of the dump, so make sure you have enough space on your C: drive.
Finding the Root Cause Using Windbg
Now that we have the dump, we can open it up in Windbg and look around. You’ll need to have Windbg installed in the correct version (it comes in both x86 and x64 versions). While Windbg can only officially be installed as part of the whole Windows SDK, Windbg itself is xcopy deploy-able, and is available for download here.
To make things simple, I just run Windbg on the server itself. That way I won’t run into issues with differing CLR versions being installed on the machine, making debugging quite difficult.
Once Windbg is running, press Ctrl+D and open the .DMP file.
The first command you’ll want to execute is this:
!loadby sos clr
This loads in the Son of Strike extension that contains a lot of useful methods for debugging .NET code.
Identifying Runaway Threads
As we seem to have a runaway code issue, let’s start out by issuing the following command:
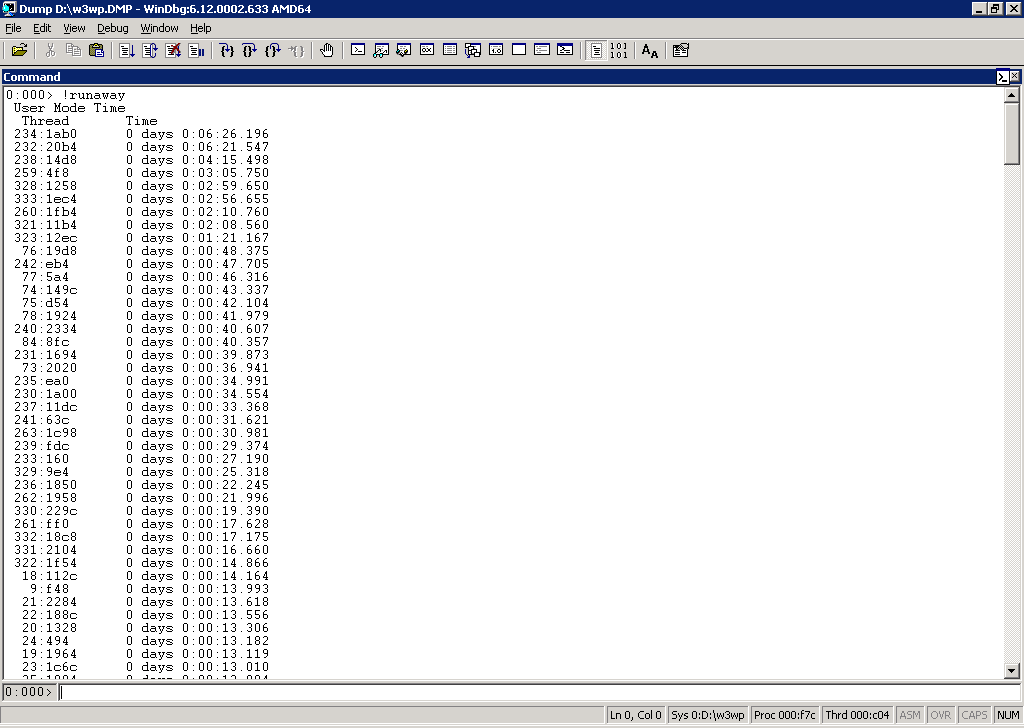
!runaway
This lists all the threads as well as the time spent executing user mode code. When dealing with a 100% CPU issue, you’ll generally see some threads chugging away all the time. In this case it’s easy to see that looking at just the top four threads, we’ve already spent over 20 (effective) minutes executing user mode code - these threads would probably be worth investigating.
Analyzing CLR Stacks
Now that we’ve identified some of the most interesting threads, we can select them one by one like so:
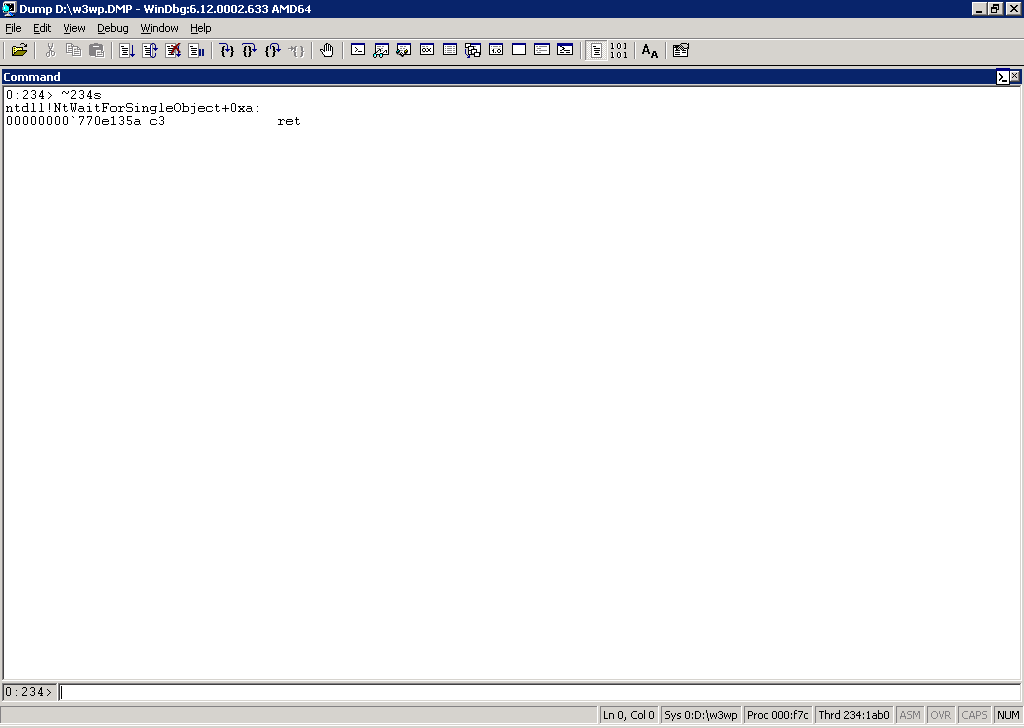
~Xs
Switching X out with a thread number (e.g. 234, 232, 238, 259, 328, etc.) allows us to select the thread. Notice how the lower left corner indicates the currently selected thread:
Once selected, we can see what the thread is currently doing by executing the following command:
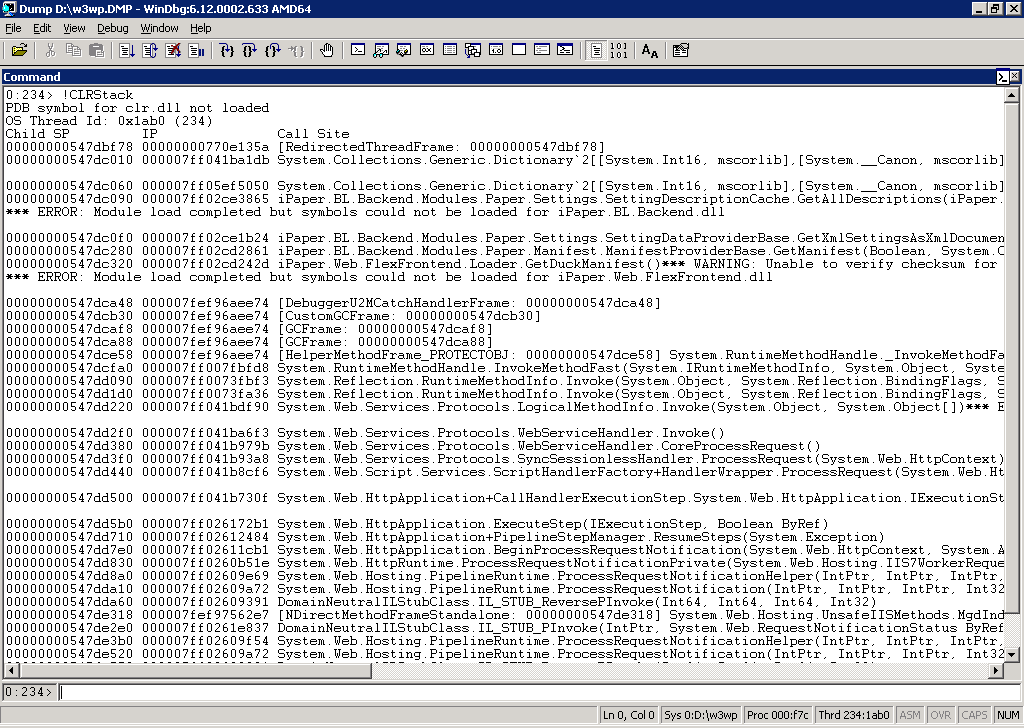
!CLRStack
Looking at the top frame in the call stack, it seems the thread is stuck in the BCL Dictionary.FindEntry() method:
Interestingly, all of the threads are stuck inside internal methods in the base class library Dictionary class. All of them are invoked from the user SettingDescriptionCache class, though from different methods.
At my job we’ve got a product that relies heavily on Flash. The last couple of days I’ve had a number of users complain that, all of a sudden, they couldn’t view Flash content any more. Common for all of them were their browser - Chrome. It would seem that, somehow, the native Chrome Flash player got disabled by itself all of a sudden.
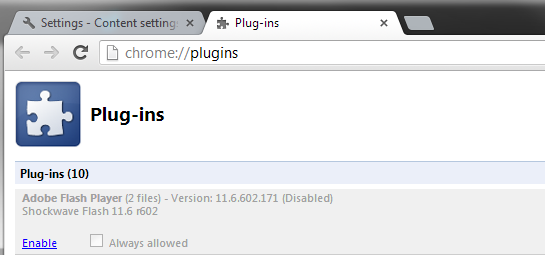
What’s especially unusual about this is that Chrome has a built-in Flash player, so if anyone, Chrome users should be able to view Flash content. Digging deeper I found that the built-in Flash player extension had been disabled. To check if that’s the case, see here:
By just clicking “Enable”, everything is working again. But how did it get disabled? This is such a convoluted place to find that I know the users haven’t done so themselves. Looking at Twitter, it seems we’re not alone in seeing this:
… I think you get the picture. It seems that all of our users had just had their Flash player auto update itself. I’m wondering, could the Internet Explorer Flash plugin perhaps updated itself and, by mistake, disabled the Chrome plugin? If the built-in Chrome Flash player is disabled, Chrome will try to use the regular Flash plugin. However, the Internet Explorer version won’t work in Chrome, so that won’t work.
Anyone else experienced this? Any tips on what’s causing it? The fix is simple, but I’d really like to understand what’s causing this, as well as knowing how widespread the issue is.
Seeing SQLSaturday events sprawling up all over the world makes me all warm and fuzzy inside. Long have I been considering whether one might happen in Denmark, but to be honest, I didn’t think the audience would be big enough. I’m biased though as I’ve mainly attended events outside of Denmark, and thus most of my acquaintances have been non-Danish. But lo and behold, Régis Baccaro just announced that SQLSaturday #196 now has 101 registered attendees! And best of all, it’s held in Copenhagen on the 20th of April.
Having just about 100 people attend my Top X SQL Server Developer Mistakes session at Warm Crocodile recently made me realize just how popular SQL Server really is. Nosql might be the hype, but when it comes to business, quite a lot of developers are “stuck” with SQL Server on a daily basis. For the same reason, I absolutely cannot recommend going to SQLSaturday #196 enough! It’s free, it’s an excellent networking opportunity and it’s sure to be full of great speakers and content. Go ahead - register here!
I’ll have the pleasure and honor of presenting my A Deep Dive Into the Depths of the SQL Server Storage Engine and MDF File Format precon on the 19th of April, the day before the SQLSaturday event itself. It’s not the first time I’m presenting this precon, in fact, this’ll be my fifth time. This means I’ve now had a number of chances to test my content and optimize the format to ensure you get maximum value out of the day. If you’re planning on attending and have any special requests or questions regarding the content, please do let me know in the comments here!
Having been at it for almost 11 years, I’ve been through a number of blog revamps through the time. And here we are, once again.
I first launched the blog back in 2002, though it was in Danish back then. In 2006 I decided to start over, removed all my Danish content and began blogging in English - at that time, I wrote my own blog engine in a couple of days on a couch in Henderson, Nevada, anxiously waiting to turn 21 so I could participate in the World Series of Poker.
Back in 2011 I chose to migrate all my content onto Subtext. What I failed to notice was that the project was pretty much dead, so it was a migration doomed to be still born. It did however allow me access to Windows Live Writer which served its purpose - it got me blogging again due to its simplicity in use. However, I quickly started to struggle with Subtext as templating was beyond difficult and I had to resort to ugly hacks to make it work the best I could.
And so it was time for yet another revamp, this time, hopefully the last. Converting everything into Wordpress ought to be a simple task, if it wasn’t for the fact that I had almost 250 posts and 700 comments. Most of them stemming from my homebrewed system, later haphazardly migrated to Subtext, and now lying before Wordpress. I had to write a custom exporter to get most of my content from Subtext into the Wordpress WXR format. Dealing with attachments, encoding and comments was a major pain. Once I had everything into Wordpress, I had to go through each and every post and manually format the contents - having seven years of legacy left little to no structure, making it impossible to style.
At this point, all I needed to do was to find a good theme and I was up and running. Unfortunately I tend to be quite picky, so I couldn’t find anything I really liked. In the end, I ended up writing my own theme, which I’ve just published to Github. My main priority has been to create a very simplistic theme that worked great across devices, while allowing me to post easily readable code snippets. If you have any suggestions for improvements, I’d love to hear them!
It’s been a long day, and I’m finally on my way home from Copenhagen to Aarhus. Unfortunately I wasn’t able to attend the first day of the Warm Crocodile conference yesterday. Thankfully I was able to attend today, and even better, I got a chance to present my “Top X SQL Server Developer Mistakes” session today, and I’d like to thank everybody who showed up and helped fill the room to its limit. I got a lot of excellent questions during, as well as after, the session. If I missed yours, please do get in touch.
Seeing as most of my presentations are rather technical, I like to start by pointing out the fact that I have no finished higher education (though in progress), no major certifications or recognitions/awards. This leaves a perfect opportunity for me to explain, from the ground up, why I still feel qualified to be standing in front of the audience.
Today I can no longer use that introduction, as I’ve been awarded as a Microsoft MVP (SQL Server) for 2013. I’m honored to receive the award, but mostly, I’m thankful to my friends in the SQL Family.
The last couple of years have been busy, 2012 definitely taking the cake, by my standards. Through my SQL Server engagement I’ve made countless of friends across the world - The Netherlands, Slovenia, Denmark, Germany, Austria, Sweden, all over the US, South Africa, UK, and many more. I remember how my parents worried about how you couldn’t make friends through the computer… While generally being right, on this point, they were not.
As 2012 neared its end, I also promised myself that I would slow down a tad in 2013. I will still try to keep that promise. I simply cannot afford to travel around as much as I did last year, and I really want to trade just a bit of conference travel for pure leisure travel time. However, this doesn’t mean I’ll go into hibernation for the duration of 2012. Currently I’m scheduled to be presenting at the Warm Crocodile conference in Copenhagen on January 17th and I know I’ll do my utmost to attend the PASS Summit this year, having missed it in 2012. What else 2013 will bring, time will tell :)
At the moment I’m working on extending OrcaMDF Studio to not only list base tables, DMVs and tables, but also stored procedures. That’s easy enough, we just need to query sys.procedures – or that is, the sys.sysschobjs base table, since the sys.procedures DMV isn’t available when SQL Server isn’t running.
However, I don’t want to just list the stored procedures, I also want to present the source code in them. That brings up a new task – retrieving said source code. Where is it stored? I wasn’t able to find anything on Google, so let’s take a look for ourselves!
I’ve created a new empty database with a data file of three megabytes. In this database, I’ve created a single stored procedure like so:
SET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGO
-- =============================================
-- Author:
-- Createdate:
-- Description:
-- =============================================
CREATEPROCEDURE XYZ
ASBEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering withSELECT statements.
SET NOCOUNT ON;-- Insert statements for procedure hereSELECT'AABBCC'ASOutputEND
Now when I select from sys.procedures, we can see that the procedure has object ID 2105058535:
select * from sys.procedures
So far so good. We can then retrieve the definition itself as an nvarchar(MAX) by querying sys.sql_modules like so:
select * from sys.sql_modules where object_id = 2105058535
And there you have it, the source code for the XYZ procedure! But hold on a moment, while I’ve gotten the object ID for the procedure by querying the sys.sysschobjs base table, I don’t have access to sys.sql_modules yet, as that’s a view and not a base table. Let’s take a look at where sys.sql_modules gets the definition from:
I happen to remember that sys.sql_modules is a replacement for the, now deprecated, sys.syscomments legacy view. Let’s take a look at where that one gets the source from:
SELECT
o.id AS id,
convert(smallint, casewhen o.type in ('P', 'RF') then1else0end) ASnumber,
s.colid,
s.status,
convert(varbinary(8000), s.text) AS ctext,
convert(smallint, 2 + 4 * (s.status & 1)) AS texttype,
convert(smallint, 0) ASlanguage,
sysconv(bit, s.status & 1) AS encrypted,
sysconv(bit, 0) AS compressed,
s.text
FROM
sys.sysschobjs o
CROSS APPLY
OpenRowset(TABLE SQLSRC, o.id, 0) s
WHERE
o.nsclass = 0AND
o.pclass = 1AND
o.type IN ('C','D','P','R','V','X','FN','IF','TF','RF','IS','TR') AND
has_access('CO', o.id) = 1UNIONALLSELECT
c.object_id AS id,
convert(smallint, c.column_id) ASnumber,
s.colid,
s.status,
convert(varbinary(8000), s.text) AS ctext,
convert(smallint, 2 + 4 * (s.status & 1)) AS texttype,
convert(smallint, 0) ASlanguage,
sysconv(bit, s.status & 1) AS encrypted,
sysconv(bit, 0) AS compressed,
s.text
FROM
sys.computed_columns c
CROSS APPLY
OpenRowset(TABLE SQLSRC, c.object_id, c.column_id) s
UNIONALLSELECT
p.object_id AS id,
convert(smallint, p.procedure_number) ASnumber,
s.colid,
s.status,
convert(varbinary(8000), s.text) AS ctext,
convert(smallint, 2 + 4 * (s.status & 1)) AS texttype,
convert(smallint, 0) ASlanguage,
sysconv(bit, s.status & 1) AS encrypted,
sysconv(bit, 0) AS compressed,
s.text
FROM
sys.numbered_procedures p
CROSS APPLY
OpenRowset(TABLE SQLSRC, p.object_id, p.procedure_number) s
UNIONALLSELECT
o.id AS id,
convert(smallint, casewhen o.type in ('P', 'RF') then1else0end) ASnumber,
s.colid,
s.status,
convert(varbinary(8000), s.text) AS ctext,
convert(smallint, 2) AS texttype,
convert(smallint, 0) ASlanguage,
sysconv(bit, 0) AS encrypted,
sysconv(bit, 0) AS compressed,
s.text
FROM
sys.sysobjrdb o
CROSS APPLY
OpenRowset(TABLE SQLSRC, o.id, 0) s
WHERE
db_id() = 1AND
o.type IN ('P','V','X','FN','IF','TF')
Bummer. It doesn’t use object_definition, but instead another internal function in the form of OpenRowset(TABLE SQLSRC, o.id, 0). I’m not one to give up easily though – I’ve previously reverse engineered the OpenRowset(TABLE RSCPROP) function.
Let’s take a different approach to the problem. Everything in SQL Server is stored on 8KB pages in a fixed format. As the procedures aren’t encrypted, they must be stored in clear text somewhere in the database – we just don’t know where. Let’s detach the database and crack open a hex editor (I highly recommend HxD):
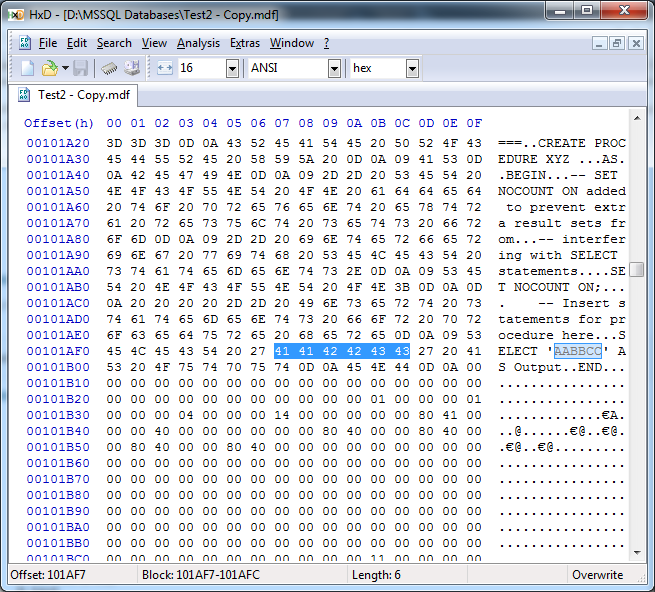
Now let’s see if we can find the procedure. On purpose I made it return “SELECT ‘AABBCC’ AS Output” as that would be easy to search for:
And whadda ya know, there it is:
OK, so now we know that the source is stored in the database, just not where specifically. The data is stored at offset 0x00101AF0 in the data file. In decimal, that’s offset 01055472. As each data page is exactly 8KB, we can calculate the ID of the data page that this is stored on (using integer math):
01055472 / 8192 = 128
Aha! At this point we know that the source is stored on page 128 – how about we take a look at that page using DBCC PAGE? After reattaching the database, run:
dbcc traceon (3604)
dbcc page(Test2, 1, 128, 0)
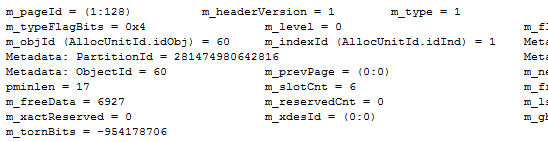
Note that I’m using style 0 for the DBCC PAGE command. At this point, I just want to see the header – there just might be something interesting in there:
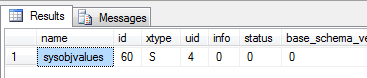
As expected, it’s a normal data page, as indicated by the m_type field having a value of 1 (which is the internal page type ID for a data page). More interesting though, we can see that the page belongs to object ID 60! Let’s have a look at what lies behind that object ID:
select * from sys.sysobjects where id = 60
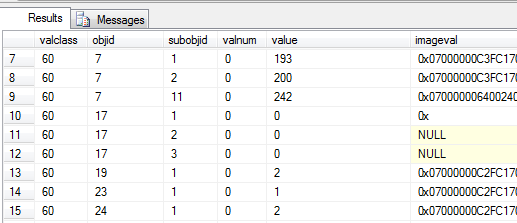
And all of a sudden, the hunt is on! Let’s have a look at the contents of sys.sysobjvalues. Note that before you can select from this table, you’ll have to connect using a dedicated administrator connection, seeing as it’s an internal base table:
select * from sys.sysobjvalues
There’s obviously a lot of stuff in here we don’t care about, but let’s try and filter that objid column down to the object ID of our procedure – 2105058535:
select * from sys.sysobjvalues where objid = 2105058535
I wonder what that imageval column contains, if I remember correctly 0x2D2D would be “—“ in ASCII, which reminds me quite a lot of the beginning of the XYZ procedure. Let’s try and convert that column into human:
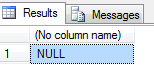
select convert(varchar(max), imageval) from sys.sysobjvalues where objid = 2105058535
And there you have it my dear reader; the source code for the XYZ stored procedure, as stored in the sys.sysobjvalues base table. As a final example, here’s how you’d retrieve a list of user stored procedures with their source code, without using neither object_definition nor sys.sql_modules:
select
p.name,
cast(v.imageval asvarchar(MAX))
from
sys.procedures p
innerjoin
sys.sysobjvalues v on p.object_id = v.objid
I’ve been to Slovenia many times, though only recently in a professional context, as I presented at NT Konferenca earlier this year. Several times, and from multiple people, I’ve heard about a local conference named Bleeding Edge, and how it was put together with nothing but level 400+ content with top quality speakers.
This summer, I happened to drop by Ljubljana to visit some friends of mine, as I was in the area on vacation. At some point in the evening, the talk turned to Bleeding Edge again, and before I knew it, Mladen Prajdić said he’d introduce me to one of the organizers, Matija Lah.
Today, I’m excited to announce that I’ll be presenting my Revealing the Magic session at Bleeding Edge 2012 on the 23-24th of October in Laško, Slovenia.
I’ve presented the session before at other venues, and this one will follow the usual fast and furious format. There are 10 hours of content compressed into just one hour. I will be showing the latest OrcaMDF bits during the session and my usual warning goes: This session is not meant to teach as much as it’s meant to inspire you. Inspire you to realize how simple SQL Server really is at its core, once you master the immediate complexity. For a full description of the session, I recommend you go to the Bleeding Edge site.
The official announcement was made a couple of days ago and I’m embarassingly late to follow up myself. “Unfortunately” this is what I’m doing right now, and I must say that achieving a proper 3G connection in the middle of the Dolomites has proven rather difficult…
Anyways, I’m happy and honored to say that I’ll be presenting my A Deep-Dive into the depths of the SQL Server storage engine and MDF file format precon at SQLSaturday #162 in Cambridge. I’ll be presenting my precon alongside SQL Server authorities like Jen Stirrup and Buck Woody, not to mention all of the regular session speakers, which have yet to be announced.
Allow me to present some of the feedback I got on my Revealing the Magic session, which is a 1-hour version of my precon, at the last SQLBits:
It was perhaps too much detail to cram into a 1 hour session.
A bit rushed. I can say it is probably the first time I felt my knowledge was not enough to keep up with mark’s content.
Great pace of session - very fast, no messing about - excellent - more sessions should get on with it, like this. Loved the session and very technical - exactly what the benefit of having this stuff delivered face-to-face.
I know he said it at the beginning. but at times it was just too fast. Maybe let the people digest what was said.
I love receiving constructive feedback, and this is so spot on! I definitely need to weed out a bit of content from my 1-hour session as there’s simply too much to go through in just one hour. Having a full day to present the same content is a much more fitting format, and it will allow me to go at a somewhat more normal pace, as well as leaving plenty of time for Q&A during the presentation.
I will however still warn you that this is a level 500 precon. I will go very in depth and there will be plenty of bits and bytes to show – documented as well as undocumented.
Please check out the Cambridgeshire SQL Server User Group page for more information on mine, Jen Stirrup and Buck Woodys precons. Make sure to register, if not for mine then for one of the other excellent precons!