Besides doing a full day training on the SQL Server Storage Engine and MDF File Internals, I’ve also submitted two related sessions that present a subset of the training day material, in a much more dense format. Both sessions are very technical deep dives on the storage internals. If you think they sound interesting, I’d appreciate a vote :)
Knowing The Internals, Who Needs SQL Server Anyway?
You’re stuck on a remote island with just a laptop and your main database .MDF file. The boss calls and asks you to retrieve some data, but alas, you forgot to install SQL Server on your laptop. Luckily you have a HEX editor by your side!
In this level 500 deep dive session we will go into the intimate details of the MDF file format. Think using DBCC Page is pushing it? Think again! As a learning experiment, I’ve created an open source parser for MDF files, called OrcaMDF. Using the OrcaMDF parser I’ll go through the primary storage structures, how to parse page headers, boot pages, internal system tables, data & index records, b-tree structures as well as the supporting IAM, GAM, SGAM & PFS pages.
Has your database suffered an unrecoverable disk corruption? This session might just be your way out! Using a corrupt & unattachable MDF file, I’ll demo how to recover as much data as possible. This session is not for the faint of heart, there will be bits & bytes.
Demystifying Database Metadata
You know how to query sys.tables, sys.columns and perhaps even sys.system_internals_allocation_units to discover the metadata contents of a database. But where are these views getting their data from, and how do the core system tables relate?
Based on my work with OrcaMDF, an open source C# parser for MDF files, I will demonstrate how to parse the internal system tables. Using just the boot page as origin, we’ll discover how to traverse the chain of references that ultimately end up in references to the actual system table data, from where we can parse the data records.
Once we’ve got the system table data, I’ll demonstrate how to correlate the different tables to end up with the data we see in common system views.
My picks
Having only 10 votes, it’s tough to pick out the top 10 sessions from a list of almost ~150 sessions. Though it was a struggle, I ended up with the following votes:
Not until now did I notice that three of my sessions are by Chirag Roy, I’ll use this as an opportunity to congratulate him on becoming the latest Microsoft Certified Master!
There are many numeral systems, the most common ones in computer science being binary (base 2), decimal (base 10) and hexadecimal (base 16). All numbers can be expressed in either system and you may now and then need to convert between them.
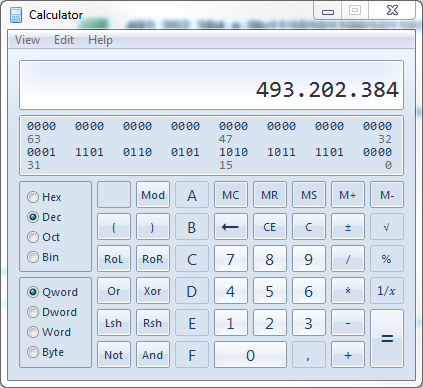
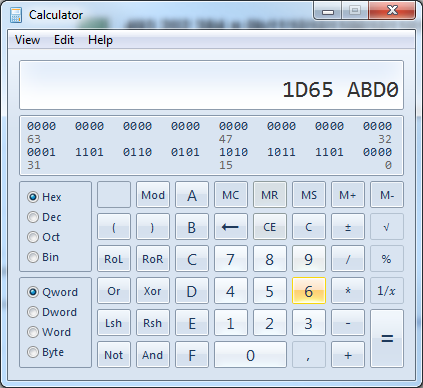
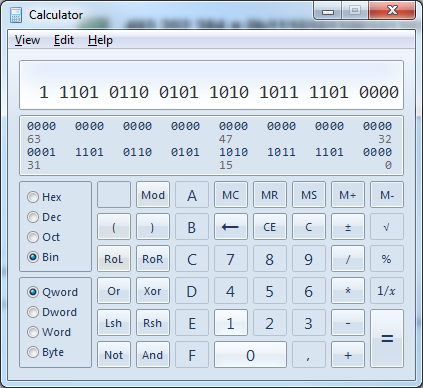
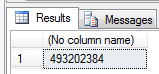
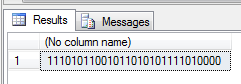
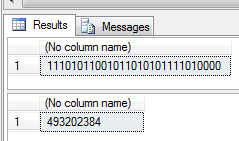
Take the number 493.202.384 as an example, it can be be expressed as either 0n493202384 in decimal, 0x1D65ABD0 in hexadecimal or 0b11101011001011010101111010000 in binary. Note how the 0n prefix declares a decimal value, 0x a hexadecimal and 0b a binary value.
Converting using Google
If you’ve got an internet connection, the quickest and simplest way is often to just use Google. We can convert the above number using “in X” queries:
You can also open Windows Calculator, switch to the programmer mode and type in the decimal value (or the hex/binary value):
And from then on we can just switch the numerical system selector to the left:
Converting between decimal & hex in T-SQL
Sometimes however, it’s just a tad easier if we could do it directly from a T-SQL query. Converting between decimal and hexadecimal is straightforward and can be done using just built in functions:
Converting to/from binary is a bit more tricky though, as there are no built in functions for formatting a decimal number as a binary string, nor converting the latter to the first.
The following function takes in a binary string and returns a bigint with the decimal value:
The function looks at each char in the input string (starting from behind), adding POWER(2, @Cnt) to the result if the bit is set – with special handling of the first (that is, from behind) character since POWER(2, 0) is 1 while we need it to be 0.
The following function takes a bigint as input and returns a varchar with the binary representation, using the short division by two with remainder algorithm:
CREATE FUNCTION [dbo].[DecimalToBinary]
(
@Input bigint
)
RETURNS varchar(255)
ASBEGINDECLARE @Outputvarchar(255) = ''
WHILE @Input > 0BEGINSET @Output = @Output + CAST((@Input % 2) ASvarchar)
SET @Input = @Input / 2END
RETURN REVERSE(@Output)
END
Again usage is straight forward:
SELECT dbo.DecimalToBinary(493202384)
Ensuring correctness
A simple test to ensure correct conversions would be to convert from A to B and back to A again, using both of the above functions. Thus whatever we give as input should be the output as well:
Lately I’ve been working on nonclustered index parsing. One of my test cases proved to be somewhat more tricky than I’d anticipated, namely the parsing of nonclustered indexes for non-unique clustered tables. Working with non-unique clustered indexes, we’ll have to take care of uniquifiers when necessary.
The setup
Using an empty database I create the following schema and insert two rows. Note that the clustered index is created on the (ID, Name) columns and will thus have uniquifiers inserted since my rows aren’t unique. Also note that I’m intentionally creating a schema that will cause all three allocation unit types to be created – IN_ROW_DATA by default, LOB_DATA for the text column and finally ROW_OVERFLOW_DATA due to the overflowing varchar filler columns. This won’t serve any practical purpose besides being eye candy when looking at the data :)
-- Create schemaCREATETABLE Test
(
ID int,
Name varchar(10),
FillerA varchar(8000) DEFAULT(REPLICATE('x', 5000)),
FillerB varchar(8000) DEFAULT(REPLICATE('y', 5000)),
Data text DEFAULT ('')
)
CREATE CLUSTERED INDEX CX_ID_Name ON Test (ID, Name)
CREATE NONCLUSTERED INDEX IX_ID ON Test (ID)
-- Insert dummy data
INSERTINTO
Test (ID, Name)
VALUES
(1, 'Mark'),
(1, 'Mark')
Verifying the presence of uniquifiers in the clustered index
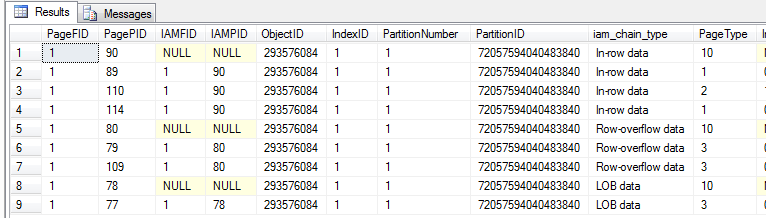
Running a quick DBCC IND on the Test table’s clustered index in the database (I’ve named mine ‘Y’ – I’m lazy), demonstrates the allocation of three allocation unit types as well as their tracking IAM pages.
DBCC IND (Y, 'Test', 1)
What we’re interested in are the two data pages of the clustered index – pages (1:89) and (1:114) in my case. Dumping the contents using dump style 3 shows that both have uniquifiers – one with a NULL value (interpreted as zero) and the other with a value of 1.
Notice how both are represented as slot 0 – this is because they stem from different pages, I’ve just cut out everything but the uniquifier column interpretation of the DBCC PAGE results. Also note how the first record doesn’t have any physical uniquifier value, while the second one uses 4 bytes. Finally make note that the uniquifier columns both reside at column ordinal 0.
Comparing the uniquifiers in the nonclustered index
Now we’ll run DBCC IND to find the single index page for the nonclustered index – page (1:93) in my case (the uniquifier will only be present in the leaf level index pages – which is all we’ve got in this case).
DBCC IND (Y, 'Test', 2)
Dumping the contents of an index page using style 3 works differently for index pages – it returns a table resultset. It does confirm the presence of the uniquifier as well as our clustered index key columns (ID, Name) though:
DBCC PAGE (Y, 1, 93, 1)
Dumping in style 1 reveals the byte contents of the two rows, which is exactly what we need to locate the uniquifier:
DBCC PAGE (Y, 1, 93, 1)
Slot 0, Offset 0x60, Length 16, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 16
Memory Dump @0x0000000009DEC060
0000000000000000: 36010000 00030000 01001000 4d61726b †6...........Mark
Slot 1, Offset 0x70, Length 22, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 22
Memory Dump @0x0000000009DEC070
0000000000000000: 36010000 00030000 02001200 16004d61 †6.............Ma
0000000000000010: 726b0100 0000††††††††††††††††††††††††rk....
Notice how the second record is 6 bytes larger than the first. This is caused by the presence of the uniquifier on the second record. Since the uniquifier is stored as a 4 byte integer in the variable length section, we also need 2 extra bytes for storing the length of the uniquifier in the variable length column offset array – thus causing a total overhead of 6. The primary difference however, lies in the fact that the uniquifier is stored as the last variable length column in the nonclustered index (the 0100 0000 part of the second record), while in the clustered index data page it was stored as the first variable length column. This discrepancy is what caused me headaches when trying to parse both page types – I needed a way of determining what column ordinal the uniquifiers had for both the clustered and the nonclustered index.
Locating the uniquifier in a clustered index
Thankfully there’s a plethora of DMVs to look in, it’s just a matter of finding the right ones. Let’s start out by querying sys.objects to get the object id of our table:
SELECT
*
FROM
sys.objects
WHERE
Name = 'Test'
Armed with the object id, we can find the default partitions for our clustered and nonclustered indexes:
SELECT
*
FROM
sys.partitions
WHERE
object_id = 293576084
Armed with the partition id, we can find the partition columns for our clustered index (index_id = 1):
SELECT
*
FROM
sys.system_internals_partition_columns
WHERE
partition_id = 72057594040483840
Now would you take a look at that marvelous is_uniquifier column (we’ll ignore the alternative spelling for now). Using this output we can see that the first row is the uniquifier – being the third part of our clustered key (key_ordinal = 3). The leaf_offset column specifies the physical order in the record, fixed length columns being positive and variable length columns being negative. This confirms what we saw earlier, that the uniquifier is the first variable length column stored, with the remaining columns coming in at leaf offset –2, –3, –4 and –5.
Locating the uniquifier in a nonclustered index
Well that was easy, let’s just repeat that using the partition id of our nonclustered index (index_id = 2):
SELECT
*
FROM
sys.system_internals_partition_columns
WHERE
partition_id = 72057594040549376
But what’s this, curses! For nonclustered indexes, the is_uniquifier column is not set, even though we can see there are three columns in our nonclustered index (the explicitly included ID, the implicitly included Name column that’s part of the clustered index key as well as the uniquifier which is also part of the clustered index key). So now we know that the uniquifier is shown in the result set, we just can’t trust the is_uniquifier column. However – to the best of my knowledge no other integer columns are stored as a variable length column, besides the uniquifier. Thus, we can add a predicate to the query returning just integers (system_type_id = 56) with negative leaf_offsets:
SELECT
*
FROM
sys.system_internals_partition_columns
WHERE
partition_id = 72057594040549376AND
system_type_id = 56AND
leaf_offset < 0
And that’s it, we now have the uniquifier column offset in the variable length part of our nonclustered index record!
The pessimistic approach
As I can’t find any info guaranteeing that the uniquifier is the only integer stored in the variable length part of a record, I came up with a secondary way of finding the uniquifier column offset. This method is way more cumbersome though and I won’t go into complete details. We’ll start out by retrieving all columns in the nonclustered index that are not explicitly part of the nonclustered index itself (by removing all rows present in sys.index_columns for the index):
DECLARE @TableName sysname = 'Test'
DECLARE @NonclusteredIndexName sysname = 'IX_ID'
SELECT
i.index_id,
pc.*
FROM
sys.objects o
INNERJOIN
sys.indexes i ON i.object_id = o.object_id
INNERJOIN
sys.partitions p ON p.object_id = o.object_id AND p.index_id = i.index_id
INNERJOIN
sys.system_internals_partition_columns pc on pc.partition_id = p.partition_id
WHERE
o.name = @TableName AND
i.name = @NonclusteredIndexName ANDNOTEXISTS (SELECT * FROM sys.index_columns WHERE object_id = o.object_id AND index_id = i.index_id AND key_ordinal = pc.key_ordinal)
These are the remaining columns that are stored as the physical part of the index record. Given that they’re not part of the index definition itself, these are the columns that make up the remainder of the clustered key – the Name and Unuiquifier columns in this example.
Now we can perform the same query for the clustered index, though this time only filtering away those that are not part of the key itself (that is, key_ordinal > 0):
DECLARE @TableName sysname = 'Test'
DECLARE @NonclusteredIndexName sysname = 'CX_ID_Name'
SELECT
i.index_id,
pc.*
FROM
sys.objects o
INNERJOIN
sys.indexes i ON i.object_id = o.object_id
INNERJOIN
sys.partitions p ON p.object_id = o.object_id AND p.index_id = i.index_id
INNERJOIN
sys.system_internals_partition_columns pc on pc.partition_id = p.partition_id
WHERE
o.name = @TableName AND
i.name = @NonclusteredIndexName AND
key_ordinal > 0ORDERBY
key_ordinal
At this point we can compare these two result sets from the highest key_ordinal and downwards. Basically we just need to find the first match between the uniquifier column in the clustered index output and the assumed uniquifier column in the nonclustered index output. Until my assumption of the uniquifier being the only variable length integer, I wouldn’t recommend using this method though.
The hardcore approach – using base tables
All those DMV’s certainly are nifty, but I just can’t help but feel I’m cheating. Let’s try and redo the optimistic (uniquifier being the only variable length integer) approach without using DMVs. Start out by connecting to your database using the dedicated administrator connection, this will allow you to query the base tables:
We’ll start out by querying sys.sysschobjs, which is basically the underlying table for sys.objects:
SELECT
*
FROM
sys.sysschobjs
WHERE
name = 'Test'
Now we’ll query sys.sysrowsets, which is basically the underlying table for sys.partitions. In the base tables, idmajor is the column name we commonly know as object_id and idminor is what we’d usually know as index_id:
SELECT
*
FROM
sys.sysrowsets
WHERE
idmajor = 293576084
Checking out the row with idminor = 2, we’ve now got the rowsetid (partition id) of our nonclustered index. Now we just need to find the columns for the index – and that’s just what sys.sysrscols is for, the base table behind sys.system_internals_partition_columns:
SELECT
*,
CAST(CAST(offset & 0xFFFFAS binary(2)) ASsmallint) AS leaf_offset
FROM
sys.sysrscols
WHERE
rsid = 72057594040549376
Note that the leaf_offset column isn’t persisted as an easily read value – it’s actually stored as an integer in the offset column. The offset column stores not only the value for the leaf_offset column but also for the internal_offset column – we just have to do some masking and conversion to get it out.
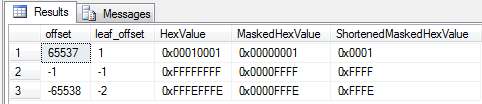
The following query helps to show exactly what we’re doing to extract the leaf_offset value from the offset column value:
SELECT
offset,
CAST(CAST(offset & 0xFFFFAS binary(2)) ASsmallint) AS leaf_offset,
CAST(offset AS binary(4)) AS HexValue,
CAST(offset & 0xFFFFAS binary(4)) AS MaskedHexValue,
CAST(offset & 0xFFFFAS binary(2)) AS ShortenedMaskedHexValue
FROM
sys.sysrscols
WHERE
rsid = 72057594040549376
The HexValue shows the offset column value represented in hex – no magic yet. After applying the 0xFFFF bitmask (0b1111111111111111 in binary), only the first 16 bits / 2 (starting from the right since we’re little endian) bytes will keep their value. Converting to binary(2) simply discards the last two bytes (the 0x0000 part).
0x0001 is easily converted to the decimal value 1. 0xFFFF and 0xFFFE correspond to the decimal values 65.535 and 65.534 respectively. The way storing smallints work, 0 is stored as 0x0, 32.767 is stored as 0x7FFF and from there on the decimal value rolls over into –32.768 with a hex value of 0x8000 – continuing all the way up the –1 = 0xFFFF. And that’s why we can convert the binary(2) representations of the offset columns into the –1 and –2 decimal values.
Join me for a journey into the depths of the SQL Server storage engine. Through a series of lectures and demonstrations we’ll look at the internals of pages, data types, indexes, heaps, extent & page allocation, allocation units, system views, base tables and nightmarish ways of data recovery. We’ll look at several storage structures that are either completely undocumented or very scarcely so. By the end of the day, not only will you know about the most important data structures in SQL Server, you’ll also be able to parse every bit of a SQL Server data file yourself, using just a hex editor! There will be lots of hands on demos, a few of them performed in C# to demonstrate the parsing of data files outside of SQL Server.
It all stems from some experimental coding I did back in March, trying to parse SQL Server data pages using C#. What started out as a learning experiment resulted in me presenting on the Anatomy of an MDF File at the Miracle Open World 2011 conference in April. Since then I’ve continued my experiment and officially christened it OrcaMDF while opening up the source.
During my research for OrcaMDF I’ve reverse engineered data structures, matched up various undocumented base tables and generally achieved a really great understanding of the storage engine and MDF file format. It’s my goal that attendees of my session will have a complete (well, almost) understanding of the on disk structures we’ll see in typical databases. Not just by looking at them through DBCC PAGE, but by taking it a couple of steps further by attempting to parse the contents by hand. You’ll get an understanding of the importance of the sys.sysallocunits base table and how that fuels all metadata in SQL Server.
For the full agenda, please check the official precon description. If you have any questions about the content that you’d like to clear up before signing up for either mine or one of the other precons available, I encourage you to leave a comment here or grab a hold of me on Twitter.
Prerequisites
While I will give brief introductions to the main concepts, I will assume a solid knowledge of what SQL Server does. I won’t spend a long time explaining why you should use clustered tables over heaps, instead I’ll give you the toolset to hopefully make that decision yourself. I’m not exaggerating when I classified the precon as level 500 – there will be 300 content too but we’ll be peaking at 500 several times during the day. We will be looking at hex codes, converting between decimal, hex and binary as needed – so make sure you don’t throw up when you see binary numbers :)
Registration
Registration hasn’t opened yet, but sign up and you’ll be notified as soon as it opens. A three day conference, including a precon day for just £375 really is a steal so make sure to get the early bind discount! I still can’t fathom that Saturday is free, as in £0, no charge – that’s too good an offer to pass up!
When working on OrcaMDF I usually setup a test database, force a checkpoint and then perform my tests on the MDF file. Problem is, you can’t open the MDF file for reading, nor copy it, as long as the database is online in SQL Server. I could shut down SQL Server temporarily while copying the file, but that quickly becomes quite a hassle.
Leveraging Volume Shadow Copy (VSS) through AlphaVSS
AlphaVSS is an excellent library for invoking VSS through .NET. While it can do much more, I’m using it to create a snapshot of a single active file, copy it and then dispose of the snapshot afterwards.
The following class presents a single static method that’ll copy any file (locked or not) and copy it to the desired destination. It would be easy to adapt upon this sample to copy multiple files, directories, etc. Note that while a copy file progress clalback is supported, I don’t really care about the progress and am there sending a null reference when calling CopyFileEx.aspx).
class VssHelper
{
[DllImport("kernel32.dll", SetLastError = true, CharSet = CharSet.Auto)]
privatestaticexternboolCopyFileEx(string lpExistingFileName, string lpNewFileName, CopyProgressRoutine lpProgressRoutine, int lpData, refint pbCancel, uint dwCopyFlags);
privatedelegateuintCopyProgressRoutine(long TotalFileSize, long TotalBytesTransferred, long StreamSize, long StreamBytesTransferred, uint dwStreamNumber, uint dwCallbackReason, IntPtr hSourceFile, IntPtr hDestinationFile, IntPtr lpData);
publicstaticvoidCopyFile(string source, string destination)
{
var oVSSImpl = VssUtils.LoadImplementation();
using (var vss = oVSSImpl.CreateVssBackupComponents())
{
vss.InitializeForBackup(null);
vss.SetBackupState(false, true, VssBackupType.Full, false);
using (varasync = vss.GatherWriterMetadata())
async.Wait();
vss.StartSnapshotSet();
string volume = new FileInfo(source).Directory.Root.Name;
var snapshot = vss.AddToSnapshotSet(volume, Guid.Empty);
using (varasync = vss.PrepareForBackup())
async.Wait();
using (varasync = vss.DoSnapshotSet())
async.Wait();
var props = vss.GetSnapshotProperties(snapshot);
string vssFile = source.Replace(volume, props.SnapshotDeviceObject + @"");
int cancel = 0;
CopyFileEx(vssFile, destination, null, 0, ref cancel, 0);
}
}
}
Earlier today I was doing some ad-hoc querying to retrieve some numbers for the month of May. Not giving it deeper thought, I made a simple query like this:
SELECTSUM(SomeColumn)
FROM
SomeTable
WHERE
SomeDatetime BETWEEN '2011-05-01'AND'2011-05-31 23:59:59.999'
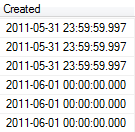
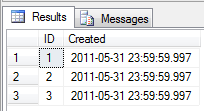
Much to my surprise, the last rows looked like this:
Why in the world are results from June included when I had an explicit predicate limiting the results to May? The answer can be found in one of my earlier posts on parsing dates. As SQL Server stores the millisecond part of a datetime with a precision of 1/300th of a second, with .997 being the highest possible stored value. .998 will be rounded down to .997 while .999 will be rounded up – causing a rollover of the day part.
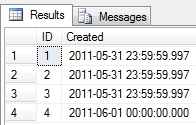
Performing my simple query reveals the same problem as earlier today:
SELECT
*
FROM
DateTest
WHERE
Created BETWEEN '2011-05-01'AND'2011-05-31 23:59:59.999'
Row number 4 is inserted with a date of 2011-06-01 00:00:00.000 since the .999 millisecond part causes a day rollover. Equally, the .999 value causes the last predicate part to be interpreted as 2011-06-01 00:00:00.000 during the CONVERT_IMPLICIT conversion.
A simple rewrite of the query guarantees to return just the results we want:
SELECT
*
FROM
DateTest
WHERE
Created >= '2011-05-01'AND Created < '2011-06-01'
As I continue to add new features & support for new data structures in OrcaMDF, the risk of regressions increase. Especially so as I’m developing in a largely unknown field, given that I can’t plan for structures and relations that I do not yet know about. To reduce the risk of regressions, testing is an obvious need.
Unit testing
Unit testing is the process of testing the smallest parts of the code, which would be functions in object oriented programming. A sample test for the SqlBigInt data type parsing class could look like this:
using System;
using NUnit.Framework;
using OrcaMDF.Core.Engine.SqlTypes;
namespace OrcaMDF.Core.Tests.Engine.SqlTypes
{
[TestFixture]
publicclass SqlBigIntTests
{
[Test]
publicvoidGetValue()
{
var type = new SqlBigInt();
byte[] input;
input = newbyte[] { 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x7F };
Assert.AreEqual(9223372036854775807, Convert.ToInt64(type.GetValue(input)));
input = newbyte[] { 0x82, 0x5A, 0x03, 0x1B, 0xD5, 0x3E, 0xCD, 0x71 };
Assert.AreEqual(8200279581513702018, Convert.ToInt64(type.GetValue(input)));
input = newbyte[] { 0x7F, 0xA5, 0xFC, 0xE4, 0x2A, 0xC1, 0x32, 0x8E };
Assert.AreEqual(-8200279581513702017, Convert.ToInt64(type.GetValue(input)));
}
[Test]
publicvoidLength()
{
var type = new SqlBigInt();
Assert.Throws<ArgumentException>(() => type.GetValue(newbyte[9]));
Assert.Throws<ArgumentException>(() => type.GetValue(newbyte[7]));
}
}
}
This tests the main entrypoints for the SqlBigInt class, testing for over/underflow of the long bigint data type, as well as checking the length. This works great for simple classes like SqlBigInt. Unit testing more complex interrelated classes requires infrastructure support for mocking out called methods, related classes, etc. While this is a working strategy, it arguably requires some effort, especially at the early stage of a project where the architecture is dynamic.
System testing
On the other end of the spectrum, we have system testing. System testing seeks to test the system as a whole, largely ignoring the inner workings of either system, which merits a categorization as black-box testing. In the case of OrcaMDF I’ve estimated that I can catch 90% of all regressions using just 10% of the time, compared to unit testing which would have the reverse properties. As such, it’s a great way to test during development, while allowing for the introduction of key unit & integration tests as necessary.
Say I wanted to test the parsing of user table names in the DatabaseMetaData class, I could mock the values of the SysObjects list, while also mocking MdfFile as that’s a require parameter for the constructor. To do that, I’d have to extract MdfFile into an interface and use a mocking framework on top of that.
Taking the system testing approach, I’m instead performing the following workflow:
Connect to a running SQL Server.
Create test schema in the fixture setup.
Detach the database.
Run OrcaMDF on the detached .mdf file and validate the results.
A sample test, creating two user tables and validating the output from the DatabaseMetaData, looks like this:
using System.Data.SqlClient;
using NUnit.Framework;
using OrcaMDF.Core.Engine;
namespace OrcaMDF.Core.Tests.Integration
{
publicclass ParseUserTableNames : SqlServerSystemTest
{
[Test]
publicvoidParseTableNames()
{
using(var mdf = new MdfFile(MdfPath))
{
var metaData = mdf.GetMetaData();
Assert.AreEqual(2, metaData.UserTableNames.Length);
Assert.AreEqual("MyTable", metaData.UserTableNames[0]);
Assert.AreEqual("XYZ", metaData.UserTableNames[1]);
}
}
protectedoverridevoidRunSetupQueries(SqlConnection conn)
{
var cmd = new SqlCommand(@"
CREATE TABLE MyTable (ID int);
CREATE TABLE XYZ (ID int);", conn);
cmd.ExecuteNonQuery();
}
}
}
This allows for extremely quick testing of actual real life scenarios. Want to test the parsing of forwarded records? Simply create a new test, write the T-SQL code to generate the desired database state and then validate the scanned table data.
The downside to system testing
Unfortunately system testing is no panacea; it has its downsides. The most obvious one is performance. A unit test is usually required to run extremely fast, allowing you to basically run them in the background on each file save. Each of these system tests takes about half a second to run, being CPU bound. Fortunately, they can be run in parallel without problems. On a quad core machine that’ll allow me to run 480 tests per minute. This’ll allow a manageable test time for a complete test set, while still keeping a subset test very quick. Usually a code change won’t impact more than handful of tests.
Earlier this week I provided some details on the forwarding stub that’s left behind when a heap record is forwarded. In this post I’ll look at the second part of a forwarded record – the actual record to which the forwarding stub points.
What’s in a forwarded record?
A forwarded record is just like a normal record, only with a couple of minor differences.
For one, the record type (read from bits 1-3 of the first record status byte, see the earlier post for details) is changed to BlobFragment, decimal value 4. This is important to note when scanning data – as all blob fragment records should be ignored. Instead, blob fragments will automatically be read whenever we scan the forwarding stub which points to the blob fragment. Scanning both directly would result in the records being read twice.
The second part being that there’s an extra variable length column stored in the record. This last variable length column is not part of the table schema, it’s actually a special pointer called the back pointer. The back pointer points back to the forwarding stub that points to this record. This makes it easy to find the original record location, given the blob fragment location. When a blob fragment shrinks in size, we can easily check whether it might fit on the original page again. It’s also used if the blob fragment size increases and we therefore might need to allocate it on a new page. In that case, we’ll have to go back to theforwarding stub and change it so it points to the new location.
The naïve implementation would be to just replace the blob fragment with another forwarding stub, thus creating a chain of forwarding stubs, eventually pointing to the forwarded record itself. However, this is not the case - SQL Server will never chain forwarding stubs.
Parsing the forwarded record
To check out the back pointer storage format, I’ve reused the table sample from the last post. Thus we’ve got a forwarding stub on page (1:114) pointing to the forwarded record on page (1:118). Let’s try and parse the forwarded record at (1:118:0):
3200 The first two bytes are the two status bytes, indicating that this is a blob fragment record, it’s got a null bitmap and it’s got variable length columns.
0800 The next two bytes indicates the total length of the fixed length portion of this record.
02000000 Next up is the first and only fixed length column, an integer field with a decimal value of 2.
0200 Indicates the total number of columns in this record – decimal value 2.
00 The next byte is the null bitmap. As there are no nullable columns in this table, no columns have a null bit set, thus the value of 0.
0200 The next two bytes specify the number of variable length columns contained in the record. Hold up - this doesn’t add up! The total number of columns was two, and we’ve got a single fixed length column. So how can there be two variable length columns, adding up to a total of three columns? This extra variable length column is the special back pointer field, as we’ll look at in just a bit.
9913a393 The next four bytes, in pairs of two, is the variable length column offset array. They hold the offsets (and thus the length) of each variable length field. The first offset is 0x1399 = 5.017. The second offset is a bit more tricky. 0x93a3 has a decimal value of 37.795, clearly above the valid threshold. If we convert that value to binary, we get a value of 0b1001001110100011. No variable column length offset will ever need the high order bit and it’s thus used as an indicator for a pointer column – just like it’s used to indicate a row-overflow pointer. If we flip the high order bit, we get a value of 0b0001001110100011 = 5.027. Subtracting 5.017 from 5.027 gives us a column size of 10 bytes – the size of the back pointer.
5.000 x 0x62 I’ve snipped the next 5.000 bytes as those are just 5.000 ‘b’s repeated – the data in the Data column.
0004 The first two bytes indicates the special column ID with a decimal value of 1.024, indicating that it’s a back pointer.
72000000 Is the beginning of the back pointer page location. 0x72 = 114 in decimal, which is the page ID of the referencing forwarding stub.
0100 Indicates the file ID with a decimal value of 1.
0100 Finally the last two bytes indicates the slot number with a decimal value of 1.
And so, with the above, we’ve now parsed the complete forwarded record. We can conclude that the back pointer takes up a total of 10 bytes, in this case pointing to the slot (1:114:1)
A forwarded record occurs whenever a record in a heap increases in size and it no longer fits on the page. Instead of causing a page split, as would happen had the table not been a heap, the record is moved onto another with enough free space, or onto a newly allocated page. Forwarded records can wreak havoc to your performance due to fragmentation, but I’ll leave not cover that here as many other more skilled people havealreadydoneso.
Test setup
As a test table we’ll use a simple table with three wide records, taking up almost a full page of data.
-- Create test tableCREATETABLE ForwardedRecordTest
(
ID intidentity,
Data varchar(8000)
)
-- Insert dummy data
INSERTINTO
ForwardedRecordTest (Data)
VALUES
(REPLICATE('a', 2000)),
(REPLICATE('b', 2000)),
(REPLICATE('c', 2000))
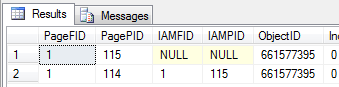
Firing up DBCC IND shows us a single IAM page tracking a single data page:
DBCC IND (Test, ForwardedRecordTest, -1)
Now, to force a forwarded record, we’ll update one of the columns so it’ll no longer fit on the page with the other records:
UPDATE
ForwardedRecordTest
SET
Data = REPLICATE('b', 5000)
WHERE
Data = REPLICATE('b', 2000)
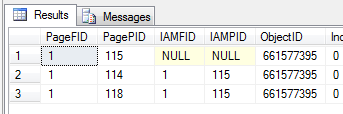
Invoking DBCC IND again confirms that a new page has been allocated to our table:
The FORWARDING_STUB
By using DBCC PAGE we can take a look at the forwarded recorded, or at least what’s left of it on the original page 114:
DBCC TRACEON (3604)
DBCC PAGE (Test, 1, 114, 3)
Identifying a forwarding stub is done by looking at the first status byte of the record. Specifically, bits 1-3 will tell us the record type:
While other record types will have two status bytes, a forwarding stub only has a single status byte. Thus, if we identify the record to be a forwarding stub, we know that the next 8 bytes will be a page pointer.
Parsing the forwarding stub
Once we know the format, parsing a forwarding stub record is straight forward.
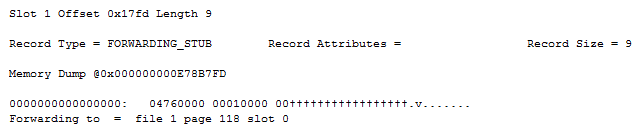
The first byte has a value of 0x04, or 0b100 in binary. Looking at bits 1-3 we get 0b10 or decimal 2 – which matches RecordType.ForwardingStub.
Looking at the next 8 bytes we have 7600000000010000. I’ve divided them into three groups – in order they contain the page ID, the file ID and finally the slot number.
76000000 byte swapped = 0x76 = 118 in decimal.
0001 byte swapped = 0x01 = 1 in decimal.
0000 byte swapped = 0x00 = 0 in decimal.
Thus we have the position of the forwarded record: (1:118:0).
Eric Lawrence’s Fiddler has many uses. I use it every day for debugging our client/server interaction, caching behavior, etc. What many don’t realize is that Fiddler is also an excellent platform for scripting, enabling you to modify requests and responses as they go out and come back. I made a quick script to automatically download streamed MP3 files as they were played, naming them automatically from the ID3 information contained in them.
As I’m lazy, and most likely you are too, we’ll use the excellent TagLib Sharp library for parsing the ID3 information in the downloaded MP3 files. You can get the latest version (2.0.4.0 as of this writing) from here.
To gain access to the TagLib Sharp library from Fiddler, add a reference to it in the Fiddler Options dialog:
Setting up the script
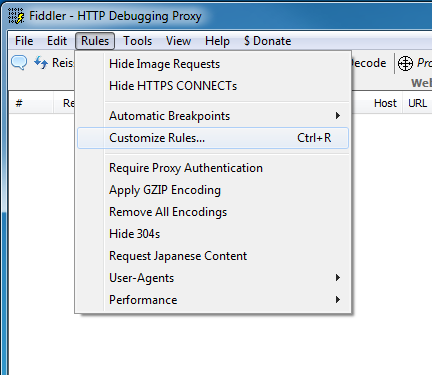
Now go to to Rules menu and click “Customize Rules…” to open the CustomRules.js file in the FiddlerScript Editor that we installed before.
Go to the OnBeforeResponse function and add the following bit of code to the end:
The first line identifies the requests that are for MP3 files. Depending on where you’re streaming from, you’ll obviously need to change this line to match your specific requirements.
Once an MP3 response has been detected, we save the file using a GUID as the name. If TagLib Sharp detects a song title, the file is renamed in the “AlbumArtists – Title.mp3” form. If no title is present, we just let the file stay with the GUID name for manual renaming later on.
Save the CustomRules.js file and Fiddler will automatically pick up on the changes and start saving those precious MP3s!
Disclaimer
Obviously the above code should only be used to save MP3 files from streams to which you own the rights.

 Having only 10 votes, it’s tough to pick out the top 10 sessions from a list of almost ~150 sessions. Though it was a struggle, I ended up with the following votes:
Having only 10 votes, it’s tough to pick out the top 10 sessions from a list of almost ~150 sessions. Though it was a struggle, I ended up with the following votes: