Being a proponent of carefully choosing your data types, I’ve often longed for the mediumint data type that MySQL has. Both smallint and int are signed data types, meaning their ranges are –32,768 to 32,767 for smallint and –2,147,483,648 to 2,147,483,647 for int. For most relational db schemas, positive identity values are used, meaning we’re looking at a possible 32,767 vs 2,147,483,647 values for smallint vs int. That’s a humongous difference, and it comes at a storage cost as well – 2 vs 4 bytes per column. If only there was something in between…
You say mediumint, I say binary(3)
While there’s no native mediumint data type in SQL Server, there is a binary data type. Internally it’s basically just a byte array, just as any other data type. An int is just a binary(4) with some custom processing on top of it, smallint being a binary(2) and nvarchar being a binary(length * 2). What that means is there’s no stopping us from saving whatever bytes we want into a binary(3) column, including numbers. Using the following sample table:
CREATE TABLE ThreeByteInt
(
MediumInt binary(3),
Filler char(20) NULL
)
CREATE CLUSTERED INDEX CX_ThreeByteInt ON ThreeByteInt (MediumInt)
We can insert values through SQL either using byte constants or using numbers as normal:
INSERT INTO ThreeByteInt (MediumInt) VALUES (0xC9DF48)
INSERT INTO ThreeByteInt (MediumInt) VALUES (0x000000)
INSERT INTO ThreeByteInt (MediumInt) VALUES (0xFFFFFF)
INSERT INTO ThreeByteInt (MediumInt) VALUES (13229896)
INSERT INTO ThreeByteInt (MediumInt) VALUES (1500)
INSERT INTO ThreeByteInt (MediumInt) VALUES (0)
INSERT INTO ThreeByteInt (MediumInt) VALUES (16777215)
And querying works like normal as well:
SELECT * FROM ThreeByteInt
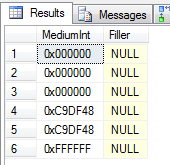
Scans ahoy!
However, take a look at the plans for these two queries:
SELECT * FROM ThreeByteInt WHERE MediumInt = 1500
SELECT * FROM ThreeByteInt WHERE MediumInt = 0x0005DC
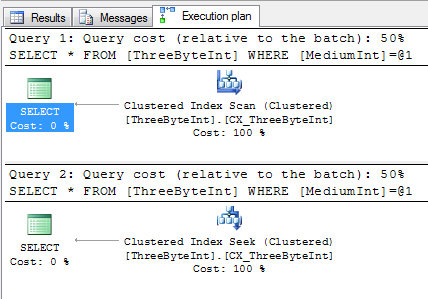
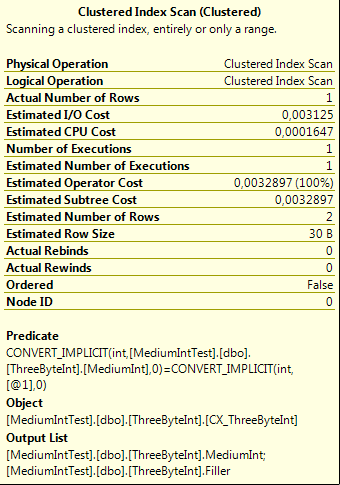
They both contain a predicate looking for a value of 1500, one written as an integer constant, the other as a hex constant. One is causing a scan, the other is using a seek. Taking a closer look at the scan reveals an IMPLICIT_CONVERT which renders are index useless and thus causing the scan:
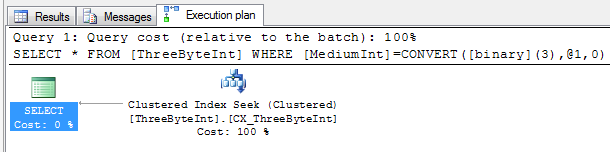
The easiest way of avoiding this is just to replace the implicit conversion with an explicit cast in the query:
SELECT * FROM ThreeByteInt WHERE MediumInt = CAST(1500 as binary(3))
Unsigned integers & overflow
Whereas smallint, int and bigint are all signed integer types (the ability to have negative values), tinyint is not. Tinyint is able to store values in the 0-255 range. Had it been a signed type, it would be able to handle values in the –128 to 127 range. Just like tinyint, binary(3)/mediumint is an unsigned type, giving us a range of 0 to 16,777,215.
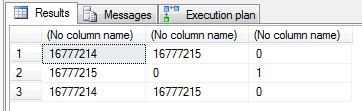
Most developers & DBAs have experienced integer overflow at some point, usually causing havoc in the application. In short, an overflow occurs when you assign a value larger or smaller than what the data type can handle. In our case, that might be –1 or 16,777,216. We can easily demonstrate what’s happening by casting an integer to binary(3) and back to int again like so:
SELECT
CAST(CAST(16777214 AS binary(3)) AS int),
CAST(CAST(16777215 AS binary(3)) AS int),
CAST(CAST(16777216 AS binary(3)) AS int)
UNION ALL
SELECT
CAST(CAST(-1 AS binary(3)) AS int),
CAST(CAST(0 AS binary(3)) AS int),
CAST(CAST(1 AS binary(3)) AS int)
UNION ALL
SELECT
CAST(CAST(33554430 AS binary(3)) AS int),
CAST(CAST(33554431 AS binary(3)) AS int),
CAST(CAST(33554432 AS binary(3)) AS int)
Working with binary(3) on the client side
Now that we’ve got our mediumint data type, all we need is to be able to insert & query data from the client.
Inserting is easy – just send values is as integers and it’ll be converted as appropriate – just make sure to check for over/underflows as necessary:
using(var conn = new SqlConnection("Data Source=.;Initial Catalog=MediumIntTest;Integrated Security=SSPI;"))
{
var insert = new SqlCommand("INSERT INTO ThreeByteInt (MediumInt) VALUES (@MediumInt)");
insert.Parameters.Add("@MediumInt", SqlDbType.Int).Value = 439848;
insert.Connection = conn;
conn.Open();
insert.ExecuteNonQuery();
conn.Close();
}
Querying requires slightly more effort. We’ll still pass in the value as an integer, but we’ll have to perform a CAST in the query to avoid scans. We could also pass the value in as a three byte array, but provided we have access to the query text, it’s easier to perform the conversion there. Furthermore there’s no standard three byte integer type in C#, so we’ll have do perform some ugly magic to convert the three bytes into a normal .NET integer:
using(var conn = new SqlConnection("Data Source=.;Initial Catalog=MediumIntTest;Integrated Security=SSPI;"))
{
var select = new SqlCommand("SELECT MediumInt FROM ThreeByteInt WHERE MediumInt = CAST(@MediumInt AS binary(3))");
select.Parameters.Add("@MediumInt", SqlDbType.Int).Value = 439848;
select.Connection = conn;
conn.Open();
byte[] bytes = (byte[])select.ExecuteScalar();
int result = BitConverter.ToInt32(new byte[] { bytes[2], bytes[1], bytes[0], 0 }, 0);
conn.Close();
Console.WriteLine(result);
}
Summing it up
As I’ve shown, we can easily create our own mediumint data type, just as we can create a 5 byte integer, 6 byte… Well, you get it. However, there are obviously some trade offs in that you’ll have to manage this data type yourself. While you can query it more or less like a normal data type, you have to be wary of scans. Finally, retrieving values will require some extra work, though that could easily be abstracted away in a custom type.
So should you do it? Probably not. Saving a single byte per column will gain you very little, unless you have a humongous table, especially so if you have a lot of columns that fit in between the smallint and int value range. For those humongous archival tables, this might just be a way to shave an extra byte off per mediumint column.