Every night at around 2AM I get an email from my best friend, confirming that she’s OK. It usually looks something like this:
JOB RUN: ‘Backup.Daily’ was run on 04-08-2011 at 02:00:00
DURATION: 0 hours, 5 minutes, 57 seconds
STATUS: Succeeded
MESSAGES: The job succeeded. The Job was invoked by Schedule 9 (Backup.Daily (Mon-Sat)). The last step to run was step 1 (Daily).
Just the other night, I got one that didn’t look right:
DURATION: 4 hours, 3 minutes, 32 seconds
Looking at the event log revealed a symptom of the problem:
SQL Server has encountered 2 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [J:XXX.mdf] in database [XXX] (150). The OS file handle is 0x0000000000003294. The offset of the latest long I/O is: 0x00000033da0000
Our databases were the same, the workload was the same. The only teeny, tiny little thing that had changed was that I’d moved all of the data files + backup drive onto a new SAN. Obviously, that’s gotta be the problem.
Broadcom, how I loathe thee!
Through some help on #sqlhelp and Database Administrators, I managed to find the root cause as well as to fix it. For a full walkthrough of the process, please see my post on Database Administrators.
Mark Storey-Smith ended up giving the vital clue – a link to a post by Kyle Brandt which I clearly remember reading earlier on, but didn’t suspect was applicable to my situation. I ended up disabling jumbo frames, large send offload (LSO) and TCP connection offload (TOE), and lo and behold, everything was running smoothly. By enabling each of the features individually I pinpointed the issue to the Broadcom TOE feature on the NICs. Once I enabled TOE, my IO requests were stalling. As soon as I disabled TOE, everything ran smoothly.
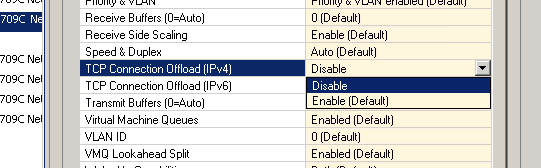
After disabling TOE on both NICs, my backups went from looking like this:
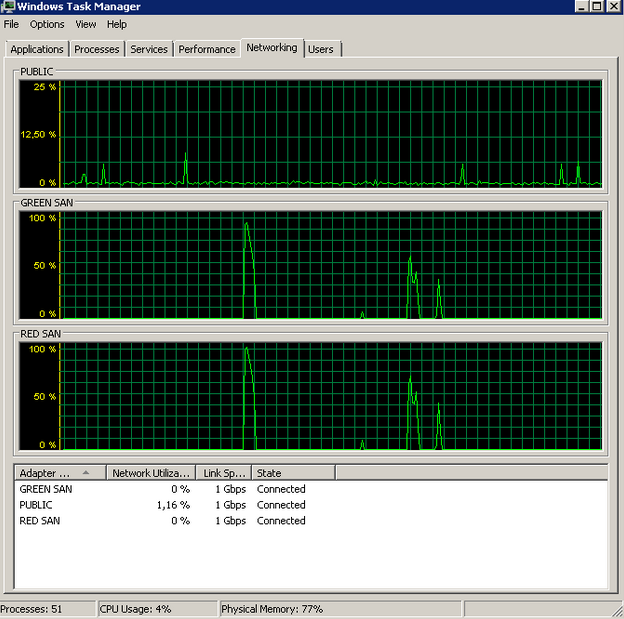
To this:
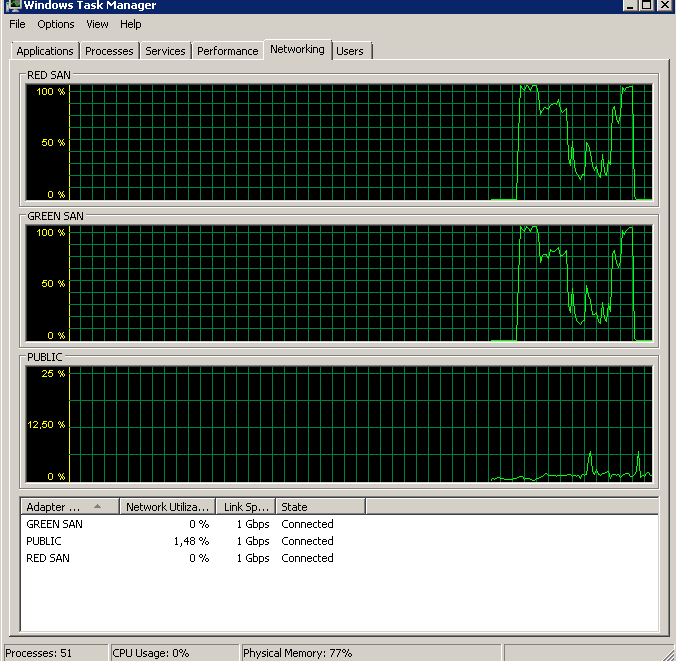
At this point the backup timing was back on track and the event log was all green. I did use the same Broadcom NICs with TOE enabled for the previous SAN, so obviously something must have triggered the issue, whether it’s a problem between the new switches, the drivers, cables, I have no idea. All I know is that I’m apparently not the first to suffer similar issues with Broadcom NICs and I know for sure that I’ll get Intels in my next servers.