While adding some extra sparse column tests to the OrcaMDF test suite, I discovered an bug in my parsing of records. While the problem was simple enough, it took me a while to debug. Running the test, it worked about 40% of the time while failing the remaining 60% of the time. As I hadn’t picked up on this pattern I happily fixed (or so I thought) the bug, ran my test and verified that it was working. Shortly after the test failed – without me having changed any code. After having the first few strains of hair turn grey, I noticed the pattern and subsequently fixed the bug.
The normal bitmap
Creating a table like the following results in a record with both a null bitmap and a variable length column for the sparse vector:
CREATE TABLE Y (A int SPARSE, B int NULL)
INSERT INTO Y VALUES (5, 2)
Outputting the lone record in the lone data pages yields the following:
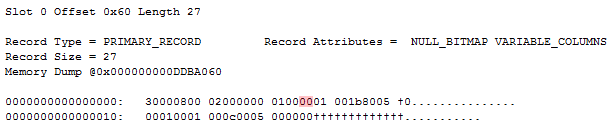
The only thing of interest is the null bitmap. It has a value of 0, indicating that all columns are non null. The only column that actually uses the null bitmap is the B column. While the B column has a column index of 1, it’s represented by index 0 in the null bitmap, given that it’s the first column utilizing the null bitmap. Since the null bitmap has a value of 0x00, we know that the remaining (and unused) 7 bits all have a value of 0 – as would be expected.
The garbage bitmap
Now consider another schema, akin to the previous one:
CREATE TABLE DifferingRecordFormats (A int SPARSE)
INSERT INTO DifferingRecordFormats VALUES (5)
ALTER TABLE DifferingRecordFormats ADD B int NULL
UPDATE DifferingRecordFormats SET B = 2
While ending up with the exact same table schema, values and record layout, the null bitmap differs. The following are three sample records, resulting from running the above script three times, dropping the table in between to start on a fresh:

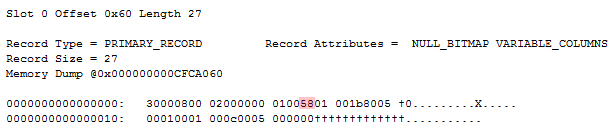
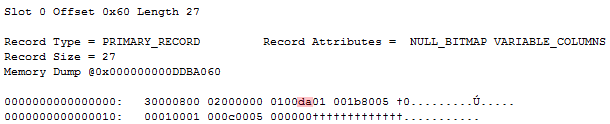
Notice how all three records are exactly the same, except for the null bitmap. It’s even identical to the “The normal bitmap” record that I fixed showed, except for the null bitmap value. Let’s try and convert those three null bitmaps to binary:
0x5C = 0b0101110**0**
0xDA = 0b1101101**0**
0x16 = 0b0001011**0**
All three bitmaps hold valid values for the bit we’re interested in – the very first (rightmost) bit. The remaining bits seem to be random garbage. While this doesn’t affect parsing as we’re not touching those spare bits, I find it interesting that the bitmap behaves differently depending on how it’s added. I’m guessing there’s an internal byte in memory that’s spilling through, having only the necessary bits flipped, instead of creating a new zeroed out byte and flipping bits as necessary on the clean byte.
Thou shalt not trust the null bitmap blindly!
Having garbage in the null bitmap raises some interesting questions. Usually when we add a nullable column to a schema, we don’t have to touch the data pages since we can determine the new columns data is not present in the record, hence it must be null. This is not done using the null bitmap however. Imagine this scenario:
CREATE TABLE Garbage (A int sparse)
INSERT INTO Garbage VALUES (5)
ALTER TABLE Garbage ADD B int NULL
UPDATE Garbage SET B = 2
ALTER TABLE Garbage ADD E varchar(10)
We start out as before, causing a garbage null bitmap that might have a value of 0b01011000, meaning the third three columns are non-null – that is, B and E (since A is sparse and therefor doesn’t utilize the null bitmap). But E is null, even though the null bitmap says otherwise. This is the record as it may (given that the null bitmap value can vary) look after the above queries have been run:
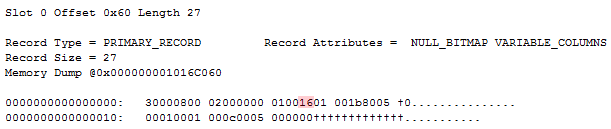
So according to the null bitmap, both B and E are null – doing a select confirms that that is not the case however:
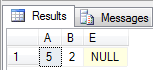
So how do we determine that E is in fact null? By ignoring the null bitmap and realizing there’s no data for E. The column count for the record has a value of 1. It’s important to note that the column count counts the total number of non-sparse columns present in the record, including variable length. Since this has a value of 1 and there’s a fixed-length column present, that’s the one it’s counting. While there’s also a variable length column, that’s the sparse vector – identified by the fact that the column count didn’t include it, and that the variable length offset array entry identifies it as a complex column.
Conclusion
I’m having some fun causing all kinds of edge cases due to sparse columns, even more fun trying to reason why what’s happening is happening. I haven’t seen garbage bitmaps before working with sparse columns and causing the specific scenario where the bitmap is added to a data record that doesn’t already have one. The most important thing to realize is that it doesn’t matter, at all. When doing reads of a record, the first thing we should check is not the null bitmap, but whether to expect the column in the record and afterwards whether there is a null bitmap at all (it may not be present in these sparse scenarios, as well as for index records).
Below is a pseudo code presentation of how I’m currently parsing records, passing all current tests. Note that it’s leaving out a lot of details, but the overall logic follows the actual implementation. Also note that I’m continually updating this as I discover new edge cases that I haven’t taken into account.
foreach column in schema {
if(sparse) {
if(record has sparse vector) {
Value = [Read value from sparse vector, possibly NULL]
} else {
Value = NULL
}
} else {
if(non-sparse column index < record.NumberOfColumns) {
if(record does not have a null bitmap OR null bitmap indicates non NULL) {
if(column is variable length) {
Value = [Read value from variable length data section]
} else {
Value = [Read value from fixed length data section]
}
} else {
Value = NULL
}
} else {
Value = NULL
}
}
}