For an introduction to the anatomy of records, I suggest you read this post by Paul Randal.
Not all variable length columns are the same. Some are more… Complex than others. An example of a complex column could be the 24 byte row-overflow pointer that are used when SLOB types overflow. Kalen Delaney has an excellent post detailing how to detect overflowing columns. There are more than one complex column type though, and the technique outlined in Kalen’s post can be generalized a bit further.
Complex columns containing row-overflow pointers
Technically I don’t this is a complex column as it doesn’t follow the normal format. It is however identified the same way, so I’ll treat it as a complex column in this post. Let’s create a simple table, cause one of the columns to overflow and then check the record contents:
CREATE TABLE OverflowTest (A varchar(8000), B varchar(8000))
INSERT INTO OverflowTest VALUES (REPLICATE('a', 5000), REPLICATE('b', 5000))
DBCC IND (X, OverflowTest, -1)
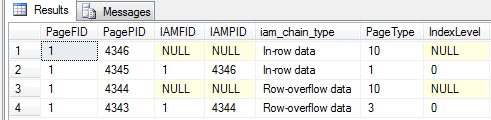
Outputting the contents of page (1:4345) shows the following (cropped to only show the first 36 bytes of the lone record body:
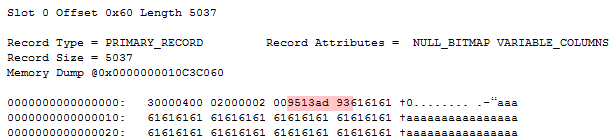
The four colored bytes make up the variable length offset array – two bytes for each offset. The first offset has a value of 0x1395 == 5013, which fits perfectly with there being 5000 characters in the first column, plus 13 for the record overhead. The second offset has a value of 0x93AD == 37.805. Converted to binary that’s a value of 0b1001001110101101. Note how the high order bit is set to 1 – indicating a complex column. Getting the actual offset requires us to mask out the high order bit like so: 0n37805 & 0b011111111111111 == 5.037. Now we can easily calculate the complex column length as being 5.037 – 5.013 == 24 bytes.
At this point we know that the column contains a complex column and we know that it’s 24 bytes long. Row-overflow pointers only use a single byte to identify the type of complex column – this is what distinguishes it from “normal” complex columns, hence why I’m reluctant to call it a complex column.

The very first byte determines the type of complex column that this is. For row-overflow/LOB pointers this can either be 1, indicating a LOB pointer, or 2, indicating a row-overflow pointer. In this case the value is 2, which confirms that we’re looking at a row-overflow pointer.
Complex columns containing forwarded record back pointers
I’ve previously blogged about the anatomy of a forwarded record back pointer. The important thing to note are the first two bytes in the pointer, marked with red:
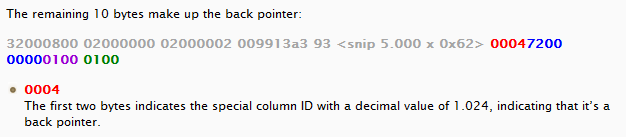
All complex columns use the first two bytes to identify the kind of complex columns. In this case a complex column ID of 1.024 indicates a back pointer.
Complex columns containing sparse vectors
Let’s create a simple table containing some sparse columns:
CREATE TABLE Sparse
(
ID int,
A int SPARSE,
B int SPARSE,
C int SPARSE,
D int SPARSE,
E int SPARSE
)
Taking a look at a dump of a record looks like this:
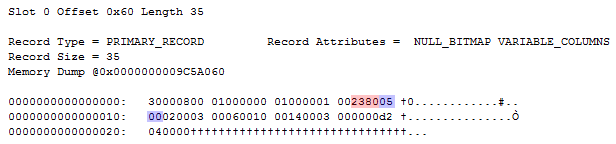
Note that there are no variable length columns in the table definition. However, the sparse vector is stored as a variable length field, thus we have a variable length offset array. The red bytes make up the offset array value of 0x8023 = 32.803. Flipping the high order bit yields a value of 35, indicating that all remaining bytes in the record belong to the sparse vector.
Since the high order bit was flipped, we know that this is a complex column. Checking out the first two bytes (marked with blue) yields a value of 0x0005. A value of 5 is exactly what indicates that we’re dealing with a sparse vector.
Conclusion
In general, variable length columns that contain some kind of special data will be indicated by having their high order bit flipped in the variable length offset array. While row-overflow pointers are not technically complex columns, that act similarly, except only using a single byte to indicate the column type.
Forwarded record back pointers are stored in complex columns having a complex column ID of 1.024.
Sparse vectors use a complex column ID of 5.
I do not know of any more complex columns as of yet, but the documentation is rather non existent except for what’s mentioned in the SQL Server 2008 Internals book.