As I write this I’m finishing the last details on a new website project I’m working on for a client. A couple of months ago I made the easy decision of going with Umbraco as the underlying CMS. I’ve had excellent experiences with Umbraco previously and the community is amazing.
Umbraco was at a split road however, version 4.7 being a widely deployed and tested version, while the brand new 5.0 rewrite had just been released as a release candidate. It was made clear that 5.0 would not be upgradable from previous versions, so I could basically go with 4.7 and be stuck, or go with a release candidate version. To my luck, 5.0 was finally released as RTM before I had to make the decision, rendering my following decision easy – 5.0 was heralded as being production ready.
Performance, oh my
Fast forward a month or so, development well underway. It was clear that there were performance issues. The forums were full of posts asking how to get performance equivalent to what people were used to in 4.7. Unfortunately, there wasn’t really a solution yet. Thankfully 5.1 was released, promising better performance. After spending a couple of days fighting a 5.0 –> 5.1 upgrade bug, I finally got 5.1 running. Much to my dismay, performance was still dismal.
This is me requesting the front page of the website:
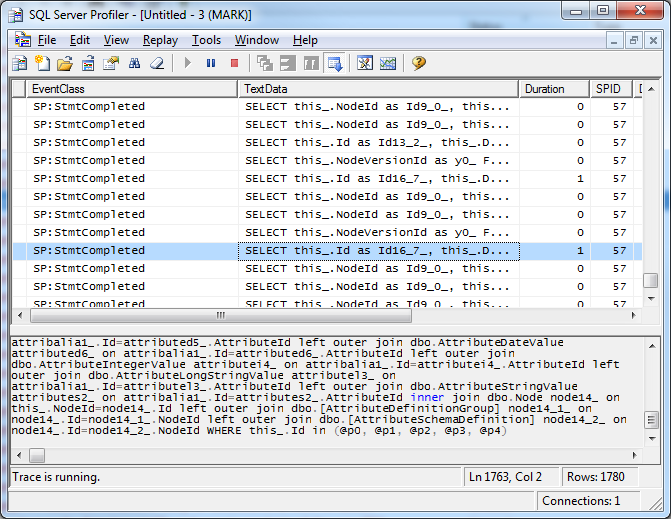
1780 individual requests to the database, with several interesting queries like the following:
SELECT this_.Id as Id16_7_, this_.DateCreated as DateCrea2_16_7_, this_.DefaultName as DefaultN3_16_7_,
this_.AttributeSchemaDefinition_id as Attribut4_16_7_, this_.NodeId as NodeId16_7_, attribalia1_.NodeVersionId
as NodeVers3_9_, attribalia1_.Id as Id9_, attribalia1_.Id as Id5_0_, attribalia1_.AttributeDefinitionId as
Attribut2_5_0_, attribalia1_.NodeVersionId as NodeVers3_5_0_, attributed5_.AttributeId as Attribut4_10_,
attributed5_.Id as Id10_, attributed5_.Id as Id1_1_, attributed5_.Value as Value1_1_, attributed5_.ValueKey
as ValueKey1_1_, attributed5_.AttributeId as Attribut4_1_1_, attributed5_.LocaleId as LocaleId1_1_,
attributed6_.AttributeId as Attribut4_11_, attributed6_.Id as Id11_, attributed6_.Id as Id0_2_, attributed6_.Value
as Value0_2_, attributed6_.ValueKey as ValueKey0_2_, attributed6_.AttributeId as Attribut4_0_2_, attributed6_.LocaleId
as LocaleId0_2_, attributei4_.AttributeId as Attribut4_12_, attributei4_.Id as Id12_, attributei4_.Id as
Id3_3_, attributei4_.Value as Value3_3_, attributei4_.ValueKey as ValueKey3_3_, attributei4_.AttributeId
as Attribut4_3_3_, attributei4_.LocaleId as LocaleId3_3_, attributel3_.AttributeId as Attribut4_13_,
attributel3_.Id as Id13_, attributel3_.Id as Id4_4_, attributel3_.Value as Value4_4_, attributel3_.ValueKey as
ValueKey4_4_, attributel3_.AttributeId as Attribut4_4_4_, attributel3_.LocaleId as LocaleId4_4_,
attributes2_.AttributeId as Attribut4_14_, attributes2_.Id as Id14_, attributes2_.Id as Id6_5_, attributes2_.Value
as Value6_5_, attributes2_.ValueKey as ValueKey6_5_, attributes2_.AttributeId as Attribut4_6_5_,
attributes2_.LocaleId as LocaleId6_5_, node14_.Id as Id9_6_, node14_.DateCreated as DateCrea2_9_6_,
node14_.IsDisabled as IsDisabled9_6_, node14_1_.Alias as Alias10_6_, node14_1_.Description as Descript3_10_6_,
node14_1_.Name as Name10_6_, node14_1_.Ordinal as Ordinal10_6_, node14_1_.AttributeSchemaDefinitionId as
Attribut6_10_6_, node14_2_.Alias as Alias11_6_, node14_2_.Description as Descript3_11_6_, node14_2_.Name as
Name11_6_, node14_2_.SchemaType as SchemaType11_6_, node14_2_.XmlConfiguration as XmlConfi6_11_6_, case when
node14_1_.NodeId is not null then 1 when node14_2_.NodeId is not null then 2 when node14_.Id is not null then
0 end as clazz_6_ FROM dbo.NodeVersion this_ left outer join dbo.Attribute attribalia1_ on this_.Id=attribalia1_.NodeVersionId
left outer join dbo.AttributeDecimalValue attributed5_ on attribalia1_.Id=attributed5_.AttributeId left outer join
dbo.AttributeDateValue attributed6_ on attribalia1_.Id=attributed6_.AttributeId left outer join dbo.AttributeIntegerValue
attributei4_ on attribalia1_.Id=attributei4_.AttributeId left outer join dbo.AttributeLongStringValue attributel3_
on attribalia1_.Id=attributel3_.AttributeId left outer join dbo.AttributeStringValue attributes2_ on
attribalia1_.Id=attributes2_.AttributeId inner join dbo.Node node14_ on this_.NodeId=node14_.Id left outer
join dbo.[AttributeDefinitionGroup] node14_1_ on node14_.Id=node14_1_.NodeId left outer join dbo.[AttributeSchemaDefinition]
node14_2_ on node14_.Id=node14_2_.NodeId WHERE this_.Id in (@p0, @p1, @p2, @p3, @p4, @p5, @p6, @p7, @p8,
@p9, @p10, @p11, @p12, @p13, @p14, @p15, @p16, @p17, @p18, @p19, @p20, @p21, @p22, @p23, @p24, @p25, @p26, @p27,
@p28, @p29, @p30, @p31, @p32, @p33, @p34, @p35, @p36, @p37, @p38, @p39, @p40, @p41, @p42, @p43, @p44, @p45, @p46,
@p47, @p48, @p49, @p50, @p51, @p52, @p53, @p54, @p55, @p56, @p57, @p58, @p59, @p60, @p61, @p62, @p63, @p64, @p65,
@p66, @p67, @p68, @p69, @p70, @p71, @p72, @p73, @p74, @p75, @p76, @p77, @p78, @p79, @p80, @p81, @p82, @p83, @p84,
@p85, @p86, @p87, @p88, @p89, @p90, @p91, @p92, @p93, @p94, @p95, @p96, @p97, @p98, @p99, @p100, @p101, @p102, @p103,
@p104, @p105, @p106, @p107, @p108, @p109, @p110, @p111, @p112, @p113, @p114, @p115, @p116, @p117, @p118, @p119, @p120,
@p121, @p122, @p123, @p124, @p125, @p126, @p127, @p128, @p129, @p130, @p131, @p132, @p133, @p134, @p135, @p136, @p137,
... <snip: some 700 other parameters> ...
@p882, @p883, @p884, @p885, @p886, @p887, @p888, @p889, @p890, @p891, @p892, @p893, @p894, @p895, @p896, @p897, @p898,
@p899, @p900, @p901, @p902, @p903, @p904, @p905, @p906, @p907, @p908, @p909, @p910, @p911, @p912, @p913, @p914, @p915,
@p916, @p917, @p918, @p919, @p920, @p921, @p922, @p923, @p924, @p925, @p926, @p927, @p928, @p929, @p930, @p931, @p932,
@p933, @p934, @p935, @p936, @p937, @p938, @p939, @p940, @p941, @p942, @p943, @p944, @p945, @p946, @p947, @p948, @p949,
@p950, @p951, @p952, @p953, @p954, @p955, @p956) and this_.Id in (SELECT this_0_.Id as y0_ FROM dbo.NodeVersion this_0_ WHERE this_0_.NodeId = @p957)
It’s clearly obvious we’re dealing with a serious N+1 problem, made worse by a lack of set based operations as evidenced by the above query. At the same time this query is a ticking time bomb – as soon as it hits the 2100 parameter limit, problems will arise unless they’re handled. The culprit seems to be the fact that the database is queried through a LINQ provider on top of Umbracos own Hive layer, on top of NHibernate. The core team themselves have voiced that NHibernate might be exacerbating the problem as they haven’t tamed the beast completely. I voiced my own concerns and suggestions on the architecture in the main performance thread. Currently the core team seems to be working on a band aid solution; adding a Lucene based cache to the site to improve performance. In my opinion the only way to really solve the issue is to fix the underlying problem – the N+1 one.
Back in January the Umbraco team posted the following: Umbraco 5: On performance and the perils of premature optimization. While I completely agree with the sentiment, avoiding N+1 issues is not premature optimization, that’s a requirement before releasing an RTM product.
The Umbraco team does deserve big kudos on owning up to the problem. They’re painfully aware of the issues people are dealing with, being unable to deploy due to crippling performance. I’m sure they’ll be improving on performance, I just hope it happens sooner than later. I did talk to Niels Hartvig and offered my help (regarding the database layer), should they want it. I’ve also had Alex Norcliffe look at my logs over email – a big thanks goes to the team, helping out even though they’re in a pinch themselves.
Band aid solutions while waiting for 5.2
As I had to get the website up and running for a trade show, I had no choice but to spin up a High-CPU Extra Large Instance on Amazon EC2. While this costs a minor fortune (compared to what hosting the site should’ve required), it gave me a temporary solution for the trade show. Startup times were still terrible but at least requesting pages went reasonably fast, even though some pages did hang for 5+ seconds, depending on the content shown.
Once the trade show was over, I downgraded the EC2 instance to an m1.large instance. It’s still expensive, but it’s a tad cheaper for development. However, there’s a bigger problem looming on the horizon – the site has to go live in a week or two.
The Umbraco team have said they expect a 5.2 performance release sometime during June, and 5.x being on par with 4.7 by the end of 2012. Unfortunately I don’t have the luxury of waiting for that.
What I’ve now done, to prepare for the launch, was to increase the output cache timeout to 24 hours by modifying web.config like so:
<caching>
<outputCacheSettings>
<outputCacheProfiles>
<add name="umbraco-default" duration="86400" varyByParam="*" location="ServerAndClient"/>
</outputCacheProfiles>
</outputCacheSettings>
</caching>
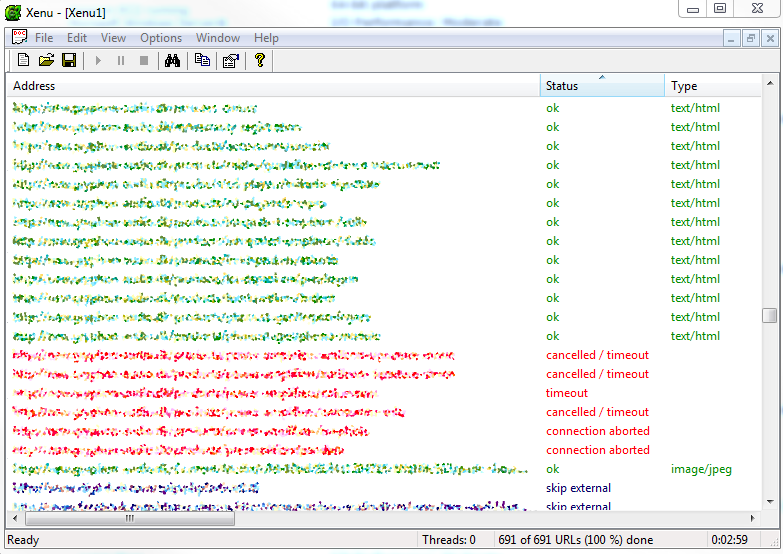
This essentially turns the website into a statically cached copy. Doing this results in each page being cached for 24 hours after it’s been visited last. While this is great, it still means those first visitors (for each page on the website) will be suffering from long waits. To fix that, I turn to Xenu’s Link Sleuth. Given the hostname, Xenu will crawl each page on the website, checking for broken links. As a side effect, every page on the site will be visited and thereby cached. By default, Xenu will use 30 concurrent threads to crawl the site. On my EC2 instance, that resulted in loads of timeouts as the instance simply couldn’t handle it:
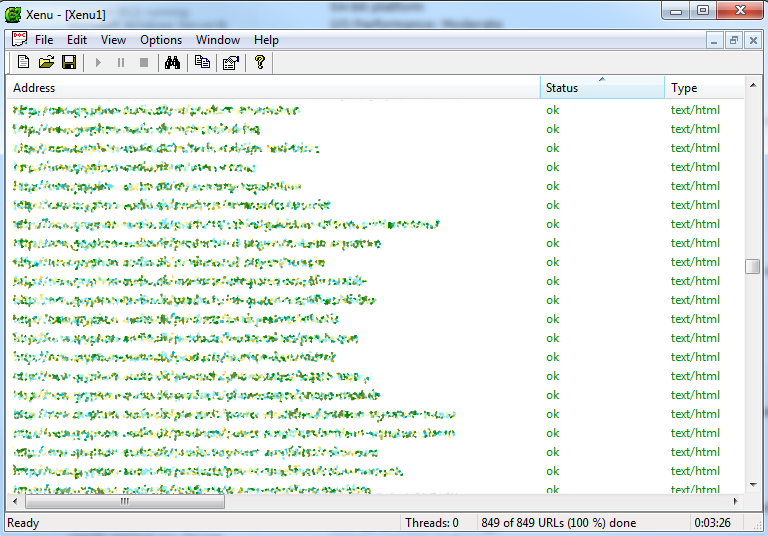
Pressing Ctrl+R forces Xenu to retry all the failed links, eventually resulting in all the links being visited successfully:
(Sorry for distorting the images – the site isn’t supposed to go completely public yet). For Xenu to find all the links on the site, you’ll have to make sure you’re using <a href /> tags. I had to replace a couple of:
<div onclick="window.open('http://xyz.com')">
With corresponding <a href /> implementations, otherwise Xenu blissfully ignored them.
Obviously fixing the performance issue like this comes with a severe cost – memory usage on the server as well as being unable to update the site from the back office. For now I can live with that as the main priority is getting the site live. When I update I’ll have to manually cycle the app pool as well as rerunning Xenu. Currently the site takes up about 500 megs of memory fully cached, so I’ve got some room to spare.
Thankfully there are no protected parts of the site so user-specific caching is not an issue – YMMV.