Once you’ve made a mess and you’ve now got millions of objects you need to delete, how do you do that as fast as possible?
Characteristics of a delete request
Contrary to a PutObjectRequest, the DeleteObjectRequest carries a rather constant payload. If we look at the actual request, the only things varying is the object name (MyObject.txt in this case) and the x-amz-date header field, as set by the .NET AWS SDK:
DELETE http://improve-eu.dk.s3-eu-west-1.amazonaws.com/MyObject.txt HTTP/1.1
User-Agent: aws-sdk-dotnet/1.3.16.0 .NET Runtime/4.0 .NET Framework/4.0 OS/6.1.7601.65536
Authorization: AWS XYZ
x-amz-date: Tue, 15 Nov 2011 21:09:38 GMT
Host: improve-eu.dk.s3-eu-west-1.amazonaws.com
Content-Length: 0
Connection: Close
The result is equally static:
HTTP/1.1 204 No Content
x-amz-id-2: k5r8aSZ3lpcWe4V255z7v8yqbMSPQQ7COEAGwsnRwzLeXpaJkSgRXNMoOf9ATdH0
x-amz-request-id: DABA77DD2B542C43
Date: Tue, 15 Nov 2011 21:09:37 GMT
Server: AmazonS3
Looking at this particular request, it takes up 322 bytes, with the only really variable part, the object name, taking up 13 of those bytes. As such, a delete request takes up roughly 309 bytes + the object name. This means pipe width probably won’t be an issue – even with massive parallelization we won’t be able to saturate even a smaller line. Again, we’re forced to look into reducing latency and increasing parallelization to improve our mass delete performance.
Does object size & existence matter?
When uploading, the size of the object obviously matters, as shown in post on upload performance. For deletes, I’d assume object size wouldn’t matter. Just to be sure though, I made a test. Through four iterations, I created 1024 objects of 1KB, 1MB and 16MB size. I then, single-threaded, deleted each of those objects, one by one and recorded the total runtime. Once all the objects were deleted, I performed all of the delete requests again, even though the objects didn’t exist. I wanted to know whether the existence of an object had an impact on the request latency.
The tests were performed using an m1.large (100Mbps bandwidth reported by instance, usually more available) instance in the EU region, accessing a bucket also in the EU region. Once run, I discarded the best and worst results and took the average of the remaining two.
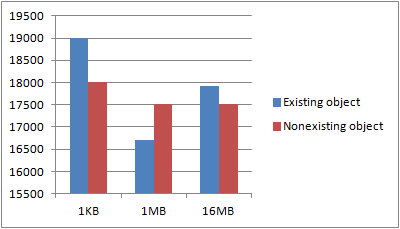
The first graphs shows some variance, which is to be expected. Key, however, is that neither the object size nor the existence of an object seems to have any general say in the performance. If we put this in a logarithmic scale, it’s a bit more apparent:
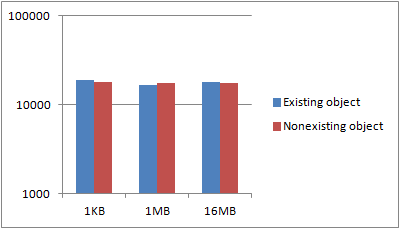
My guess is that Amazons S3 service is most likely handling a request by just marking the object, if it exists, as deleted, returning, and the asynchronously deleting the object from disk at a later time. As is usual database practice, the marking of an object as deleted and the existence check is probably done in the same query to the database, returning the number of rows affected. As such, performance is identical, no matter if an object exists or not, just as the size doesn’t matter as it’s physically deleted asynchronously.
I’ll use this fact in my testing as that means I can simply performance test deleting non-existing objects, sparing myself the need to upload deterministically named objects beforehand.
Multi-threaded deletes
The key to performance, as previously shown, is without doubt achieved by scaling out the number of threads.
The following test code spins up a given number of threads and lets them run for 30 seconds, before they’re all aborted. Each thread is continually looping, firing off as many DeleteObjectRequest’s as it can. After 30 seconds, the average request/sec is calculated and output. I ran four repetitions of each, discarded the top and bottom result and calculated the average of the remaining two.
private const string bucketName = "improve-eu.dk";
private const string serviceUrl = "s3-eu-west-1.amazonaws.com";
static void Main(string[] args)
{
var config = new AmazonS3Config().WithServiceURL(serviceUrl).WithCommunicationProtocol(Protocol.HTTP);
int numThreads = Convert.ToInt32(args[0]);
int count = 0;
var sw = new Stopwatch();
// Ensuring all connections have network connectivity
ServicePointManager.DefaultConnectionLimit = numThreads;
// The actual job each thread will be performing
var work = new ThreadStart(() =>
{
using (var s3Client = AWSClientFactory.CreateAmazonS3Client(ConfigurationManager.AppSettings["AccessKeyID"], ConfigurationManager.AppSettings["SecretAccessKey"], config))
{
var request = new DeleteObjectRequest()
.WithBucketName(bucketName)
.WithKey("xyz");
while (sw.ElapsedMilliseconds <= 30000)
{
s3Client.DeleteObject(request);
// Avoid extra counts while threads are spinning down
if(sw.ElapsedMilliseconds <= 30000)
count++;
}
}
});
// Warmup
using (var s3Client = AWSClientFactory.CreateAmazonS3Client(ConfigurationManager.AppSettings["AccessKeyID"], ConfigurationManager.AppSettings["SecretAccessKey"], config))
{
var request = new DeleteObjectRequest()
.WithBucketName(bucketName)
.WithKey("xyz");
s3Client.DeleteObject(request);
}
// Start X number of threads and let them upload as much as they can
var threads = new List<Thread>();
for (int j = 0; j < numThreads; j++)
threads.Add(new Thread(work));
sw.Start();
threads.ForEach(x => x.Start());
// Wait 30 secs, stop all threads, output reqs/sec result
Thread.Sleep(30000);
threads.ForEach(x => x.Abort());
Console.WriteLine((double)count / 30);
}
The following graph shows the results, testing with thread counts of 8, 16, 32, 64, 128, 256, being run on an m1.large instance, the more CPU-beefy c1.xlarge instance and finally the Danish Server 2003 Colo instance that I used in my last post:
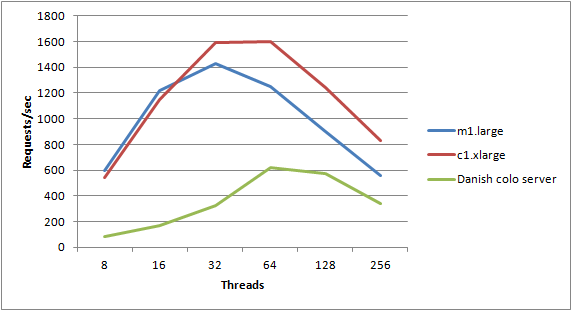
Results clearly show similar performance characteristics – both EC2 servers max out at 32 threads. The m1.large instance managed 1428 requests/sec while the c1.xlarge instance managed 1591 requests/sec. I could probably go higher using a compute cluster instance, but that’s not what I’m trying to show in this post. The colo instance went further and didn’t max out until I was running 64 threads – most likely due to the larger latency, and thus added benefit of more outstanding requests.
Disabling the Nagle algorithm
I considered, and tested, whether disabling the Nagle algorithm might have an impact. However – since each of these requests are fired on a single connection that’s closed, and hence flushed, immediately afterwards – disabling the Nagle algorithm has no measureable effect.
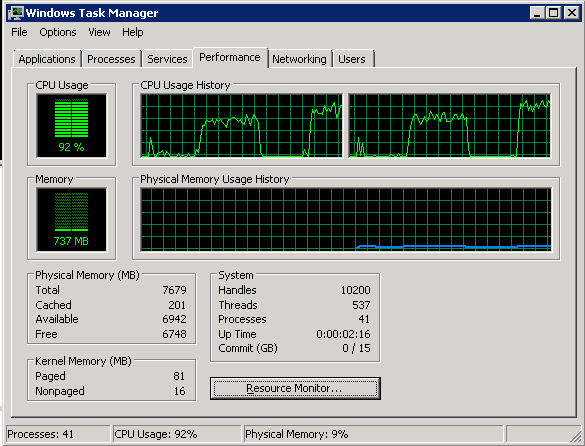
Can we lower the CPU usage?
While the EC2 CPU isn’t maxed at 32 threads, it’s way higher than I’d like it to be, even just at 64 threads:
However, the code we’re running is already in a rather tight loop without much to optimize:
while (sw.ElapsedMilliseconds <= 30000)
{
s3Client.DeleteObject(request);
// Avoid extra counts while threads are spinning down
if(sw.ElapsedMilliseconds <= 30000)
count++;
}
It’s basically just a loop, reusing the same request and letting the AmazonS3Client do its part to send off the object. Internally, AmazonS3Client.DeleteObject() is firing off the asynchronous BeginPutObject and then immediately waiting for EndPutObject afterwards. If we dig further in, there’s a lot of generic AWS SDK framework overhead in constructing the requests, checking for all sorts of conditions that may arise, but are not particularly relevant to our case. How about we ditch the SDK and create our own requests?
Following this guide on signing and authenticating REST requests, I constructed a method like this (minus the measuring and reformatting, this just shows the basic form):
var accessKeyID = "XYZ";
var secretAccessKey = "SecretXYZ";
using (var sha1 = new HMACSHA1())
{
while(true)
{
var webrequest = (HttpWebRequest)WebRequest.Create("http://improve-eu.dk.s3-eu-west-1.amazonaws.com/xyz");
webrequest.Method = "DELETE";
webrequest.ContentLength = 0;
webrequest.KeepAlive = false;
webrequest.AllowWriteStreamBuffering = false;
webrequest.AllowAutoRedirect = false;
var date = DateTime.UtcNow.ToString("R");
string stringToSign =
"DELETE" + "n" +
"n" +
"n" +
"n" +
"x-amz-date:" + date + "n" +
"/improve-eu.dk/xyz";
string signature = AWSSDKUtils.HMACSign(stringToSign, secretAccessKey, sha1);
webrequest.Headers.Add("x-amz-date", date);
webrequest.Headers.Add("Authorization", "AWS " + accessKeyID + ":" + signature);
webrequest.GetResponse().Close();
}
}
This tries to push through as many requests as possible in as little time as possible, with as little framework overhead as possible. Alas, I saw no noteworthy improvements in performance so I’m glad to report that the AWS SDK seems well optimized, even with it’s generic looks. A side result was that I shaved off the user-agent and thereby ended up with slightly smaller requests:
DELETE http://improve-eu.dk.s3-eu-west-1.amazonaws.com/xyz HTTP/1.1
x-amz-date: Wed, 16 Nov 2011 18:58:11 GMT
Authorization: AWS XYZ
Host: improve-eu.dk.s3-eu-west-1.amazonaws.com
Content-Length: 0
Connection: Close
This took me from a request size of 322 bytes down to 223 bytes on average. Sadly, this too had no noteworthy impact on performance.
Conclusion
Deletes carry a constant cost, both in payload size as well as execution time. We can’t batch them up and there’s no data to compress. As such, we’re left with just multi-threading and possibly optimizing the TCP/IP stack depending on the latency characteristics of the environment. The lower the latency, the fewer threads you should use. In my testing, a typical low-latency (e.g. EC2) environment seems to max out at 32 threads, where as a medium/high latency environment seems to max out at 64 concurrent threads.
Obviously there are steps between 32 and 64 threads and you may get better results at running just 50 threads – these are just ballpark test numbers. As always, your mileage may vary.