One of the first challenges I faced when starting out the development of OrcaMDF was parsing page headers. We all know that pages are basically split in two parts, the 96 byte header and the 8096 byte body of remaining bytes. Much has been written about headers and Paul Randal (b|t) has a great post describing the contents of the header as well. However, though the contents have been described, I’ve been completely unable to find any kind of details on the storage format. What data types are the individual fields, and what’s the order? Oh well, we’ve always got DBCC PAGE.
Firing up DBCC PAGE, I scoured for a random data page whose header I could dump, in this case page (1:101):
DBCC TRACEON (3604)
DBCC PAGE (TextTest, 1, 101, 2)
The result comes in two parts, first we’ve got the header contents as DBCC PAGE kindly parses for us, while the second part is a dump of the 96 bytes that make up the header data:
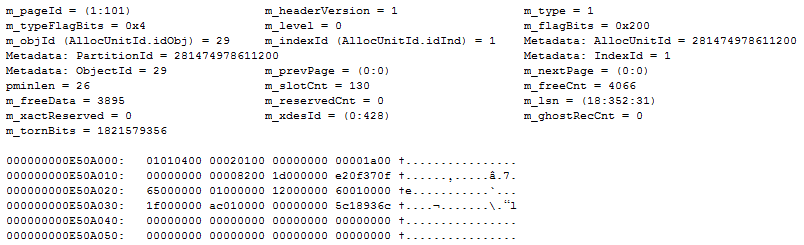
Armed with this, the hunt begins! What we’re looking for is a match between the parsed values and the bytes in the header. To make it easy, we need to spot some unique values so we don’t get a lot of ambiguity in where the value might be stored. Starting out with m_freeCnt, we see it has a value of 4066. The body size is 8060 bytes so it’s clear that the number can’t be a tinyint. It wouldn’t make sense to make it an int as that supporst way larger values than we need. An educated guess would be that m_freeCnt is probably stored as a smallint, leaving plenty of space for the 0-8060 range we need.
Now, 4066 represented in hex is 0x0FE2. Byte swapped, that becomes 0xE20F, and what do you know, we have a match!

And thus we have identified the first field of our header:
/*
Bytes Content
----- -------
00-27 ?
28-29 FreeCnt (smallint)
30-95 ?
*/
Continuing the search we see that m_freeData = 3895. In hex that’s 0x0F37 and 0x370F when swapped. And voilá, that’s stored right next to m_freeCnt:

Continuing on with this technique, we can map all the distinct header values where there’s no ambiguity as to where they’re stored. But what about a field like m_level? It has the same value as m_xactReserved, m_reservedCnt, m_ghostRecCnt, etc. How do we know which one of those zero values is really m_level? And how do we find out what the data type is? It could be anything from a tinyint to bigint!
Time to bring out the big guns! We’ll start out by shutting down MSSQL / SQL Server:
Then we’ll open up the .mdf file in Visual Studio:
This’ll open up the file in hex editor mode, allowing direct access to all the yummy data! As we know the page id was 101, we need to jump to byte offset 101 * 8192 = 827,392 to get to the first byte of page 101:
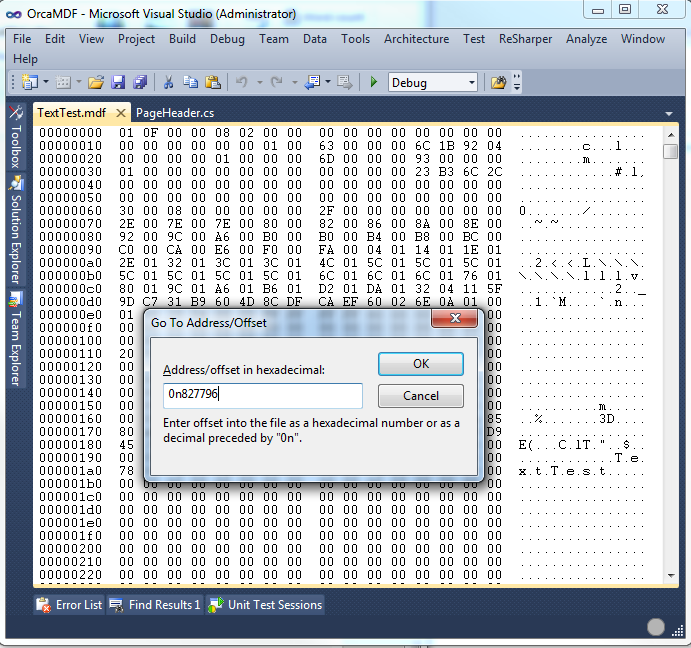
Looking at these bytes we see that they’re identical to our header contents, thus confirming we’ve jumped to the correct offset:
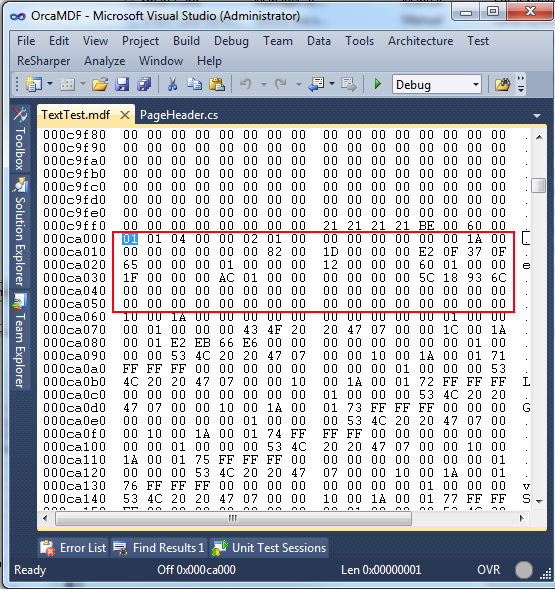
Now I’m going to ask you to do something that will make sheep loving people cry – write some gibberish in there and save the file! Please do not do this to a database with any kind of important data in it. Before:

After:

Oh the horrors! Now restart MSSQL / SQL Server and rerun the DBCC PAGE query from before:
DBCC TRACEON (3604)
DBCC PAGE (TextTest, 1, 101, 2)
And notice the header we get as a result:

Several values have changed! m_xactReserved had an ambiguous value of 0 before, now it’s at 30,806. Converting that to byte swapped hex we get a value of 0x5678. Looking at the header, we’ve now pinpointed yet another field and datatype (smallint):

And thus we can update our header reference table:
/*
Bytes Content
----- -------
00-27 ?
28-29 FreeCnt (smallint)
30-49 ?
50-51 XactReserved (smallint)
30-95 ?
*/
Continuing down this path, messing up the header, correlating messed up values with values parsed by DBCC PAGE, it’s possible to locate all the fields and their corresponding data types. If you see the following message, you know you’ve messed it up properly:

You should be proud of yourself. No go clean up the mess you’ve made!
Jumping forward, I’ve compiled a reference to the page header structure:
/*
Bytes Content
----- -------
00 HeaderVersion (tinyint)
01 Type (tinyint)
02 TypeFlagBits (tinyint)
03 Level (tinyint)
04-05 FlagBits (smallint)
06-07 IndexID (smallint)
08-11 PreviousPageID (int)
12-13 PreviousFileID (smallint)
14-15 Pminlen (smallint)
16-19 NextPageID (int)
20-21 NextPageFileID (smallint)
22-23 SlotCnt (smallint)
24-27 ObjectID (int)
28-29 FreeCnt (smallint)
30-31 FreeData (smallint)
32-35 PageID (int)
36-37 FileID (smallint)
38-39 ReservedCnt (smallint)
40-43 Lsn1 (int)
44-47 Lsn2 (int)
48-49 Lsn3 (smallint)
50-51 XactReserved (smallint)
52-55 XdesIDPart2 (int)
56-57 XdesIDPart1 (smallint)
58-59 GhostRecCnt (smallint)
60-95 ?
*/
I’m not sure what lies in the remaining bytes of the header as DBCC PAGE doesn’t seem to parse stuff there, and it seems to be zeroed out for all pages I’ve tested. I’m assuming it’s reserved bytes for future usage. Once we’ve got the format, parsing becomes a simple task of reading each field, field by field:
HeaderVersion = header[0];
Type = (PageType)header[1];
TypeFlagBits = header[2];
Level = header[3];
FlagBits = BitConverter.ToInt16(header, 4);
IndexID = BitConverter.ToInt16(header, 6);
PreviousPage = new PagePointer(BitConverter.ToInt16(header, 12), BitConverter.ToInt32(header, 8));
Pminlen = BitConverter.ToInt16(header, 14);
NextPage = new PagePointer(BitConverter.ToInt16(header, 20), BitConverter.ToInt32(header, 16));
SlotCnt = BitConverter.ToInt16(header, 22);
ObjectID = BitConverter.ToInt32(header, 24);
FreeCnt = BitConverter.ToInt16(header, 28);
FreeData = BitConverter.ToInt16(header, 30);
Pointer = new PagePointer(BitConverter.ToInt16(header, 36), BitConverter.ToInt32(header, 32));
ReservedCnt = BitConverter.ToInt16(header, 38);
Lsn = "(" + BitConverter.ToInt32(header, 40) + ":" + BitConverter.ToInt32(header, 44) + ":" + BitConverter.ToInt16(header, 48) + ")";
XactReserved = BitConverter.ToInt16(header, 50);
XdesID = "(" + BitConverter.ToInt16(header, 56) + ":" + BitConverter.ToInt32(header, 52) + ")";
GhostRecCnt = BitConverter.ToInt16(header, 58);
You can also see the full source of the header parsing at GitHub.
Wan’t more?
If this isn’t enough for you, you should go and vote for one or more of my OrcaMDF related sessions at the PASS Summit.