In this post I want to walk through a number of SQL Server corruption recovery techniques for when you’re out of luck, have no backups, and the usual methods don’t work. I’ll be using the AdventureWorksLT2008R2 sample database as my victim.
A Clean Start
To start out, I’ve attached the downloaded database and it’s available on my SQL Server 2008 R2 instance, under the name of AWLT2008R2.

To ensure we’ve got a clean start, I’ll run DBCC CHECKDB with the DATA_PURITY flag set, just to make sure the database is OK.
DBCC CHECKDB (AWLT2008R2) WITH ALL_ERRORMSGS, DATA_PURITY
DBCC results for 'AWLT2008R2'.
Service Broker Msg 9675, State 1: Message Types analyzed: 14.
Service Broker Msg 9676, State 1: Service Contracts analyzed: 6.
Service Broker Msg 9667, State 1: Services analyzed: 3.
Service Broker Msg 9668, State 1: Service Queues analyzed: 3.
Service Broker Msg 9669, State 1: Conversation Endpoints analyzed: 0.
Service Broker Msg 9674, State 1: Conversation Groups analyzed: 0.
Service Broker Msg 9670, State 1: Remote Service Bindings analyzed: 0.
Service Broker Msg 9605, State 1: Conversation Priorities analyzed: 0.
DBCC results for 'sys.sysrscols'.
There are 805 rows in 9 pages for object "sys.sysrscols".
DBCC results for 'sys.sysrowsets'.
There are 125 rows in 1 pages for object "sys.sysrowsets".
DBCC results for 'SalesLT.ProductDescription'.
There are 762 rows in 18 pages for object "SalesLT.ProductDescription".
...
CHECKDB found 0 allocation errors and 0 consistency errors in database 'AWLT2008R2'.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Enter Corruption
As I don’t want to kill my disk drives just to introduce corruption, I’ll be using OrcaMDF’s Corruptor class instead. First up we need to shut down SQL Server:
SHUTDOWN WITH NOWAIT
Server shut down by NOWAIT request from login MSR\Mark S. Rasmussen.
SQL Server is terminating this process.
Once the instance has been shut down, I’ve located my MDF file, stored at D:\MSSQL Databases\AdventureWorksLT2008R2.mdf. Knowing the path to the MDF file, I’ll now intentially corrupt 5% of the pages in the database (at a database size of 5,312KB this will end up corrupting 33 random pages, out of a total of 664 pages).
Corruptor.CorruptFile(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf", 0.05);
At this point I have no idea about which pages were actually corrupted, I just know that 33 random pages just got overwritten by all zeros.
Uh Oh
After restarting the SQL Server instance and looking at the tree of databases, it’s obvious we’re in trouble…
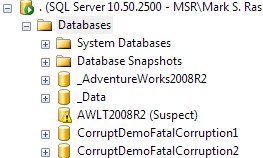
Running DBCC CHECKDB doesn’t help much:
DBCC CHECKDB (AWLT2008R2) WITH ALL_ERRORMSGS, DATA_PURITY
Msg 926, Level 14, State 1, Line 1
Database 'AWLT2008R2' cannot be opened. It has been marked SUSPECT by recovery.
See the SQL Server errorlog for more information.
What does the errorlog say?
- Starting up database ‘AWLT2008R2’.
- 1 transactions rolled forward in database ‘AWLT2008R2’ (13). This is an informational message only. No user action is required.
- Error: 824, Severity: 24, State: 2.
- SQL Server detected a logical consistency-based I/O error: incorrect pageid (expected 1:2; actual 0:0). It occurred during a read of page (1:2) in database ID 13 at offset 0x00000000004000 in file ‘D:\MSSQL Databases\AdventureWorksLT2008R2.mdf’. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.
- Error: 3414, Severity: 21, State: 1.
- An error occurred during recovery, preventing the database ‘AWLT2008R2’ (database ID 13) from restarting. Diagnose the recovery errors and fix them, or restore from a known good backup. If errors are not corrected or expected, contact Technical Support.
- CHECKDB for database ‘AWLT2008R2’ finished without errors on 2013-11-05 20:02:07.810 (local time). This is an informational message only; no user action is required.
- Recovery is complete. This is an informational message only. No user action is required.
This is officially not good. Our database failed to recover and can’t be put online at the moment, due to I/O consistency errors. We’ve also got our first hint:
incorrect pageid (expected 1:2; actual 0:0)
What this tells us is that the header of page 2 has been overwritten by zeros since SQL Server expected to find the value 1:2, but found 0:0 instead. Page 2 is the first GAM page in the database and is an essential part of the metadata.
SQL Server also wisely told us to either fix the errors or restore from a known good backup. And this is why you should always have a recovery strategy. If you ever end up in a situation like this, without a backup, you’ll have to continue reading.
DBCC CHECKDB
SQL Server recommended that we run a full database consistency check using DBCC CHECKDB. Unfortunately, given the state of our database, DBCC CHECKDB is unable to run:
DBCC CHECKDB (AWLT2008R2) WITH ALL_ERRORMSGS, DATA_PURITY
Msg 926, Level 14, State 1, Line 1
Database 'AWLT2008R2' cannot be opened. It has been marked SUSPECT by recovery.
See the SQL Server errorlog for more information.
In some cases you may be able to force the database online, by putting it into EMERGENCY mode. If we could get the database into EMERGENCY mode, we might just be able to run DBCC CHECKDB.
ALTER DATABASE AWLT2008R2 SET EMERGENCY
Msg 824, Level 24, State 2, Line 1
SQL Server detected a logical consistency-based I/O error: incorrect pageid
(expected 1:16; actual 0:0). It occurred during a read of page (1:16) in database
ID 13 at offset 0x00000000020000 in file 'D:\MSSQL Databases\AdventureWorksLT2008R2.mdf'.
Additional messages in the SQL Server error log or system event log may provide more
detail. This is a severe error condition that threatens database integrity and must
be corrected immediately. Complete a full database consistency check (DBCC CHECKDB).
This error can be caused by many factors; for more information, see SQL Server
Books Online.
Even worse, it seems that page 16 has also been hit by corruption. Page 16 is the root page of the sysallocunits base table, holding all of the allocation unit storage metadata. Without page 16 there is no way for SQL Server to access any of its metadata. In short, there’s no way we’re getting this database online!
Enter OrcaMDF
The OrcaMDF Database class won’t be able to open the database, seeing as it does not handle corruption very well. Even so, I want to try anyway, you never know. First off you’ll have to shut down SQL Server to release the locks on the corrupt MDF file.
SHUTDOWN WITH NOWAIT
If you then try opening the database using the OrcaMDF Database class, you’ll get a result like this:
var db = new Database(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
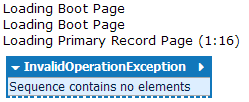
Interestingly the Database class didn’t puke on the boot page (ID 9) itself, so we know that that one’s OK, at least. But as soon as it hit page 16, things started to fall apart - and we already knew page 16 was corrupt.
RawDatabase
While the OrcaMDF Database class can’t read the database file either, RawDatabase can. RawDatabase doesn’t care about metadata, it doesn’t read anything but what you tell it to, and as a result of that, it’s much more resilient to corruption.
Given that we know the corruption has resulted in pages being zeroed out, we could easily gather a list of corrupted pages by just searching for pages whose logical page ID doesn’t match the one in the header:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf")
db.Pages
.Where(x => x.Header.PageID != x.PageID)
.Select(x => x.PageID)
.ToList()
.ForEach(Console.WriteLine);
2
4
5
16
55
...
639
649
651
662
663
This is only possible since we know the corruption caused pages to be zeroed out, so you’ll rarely be this lucky. However, sometimes you may be able to detect the exact result of the corruption, thus enabling you to pinpoint the corrupted pages, just like we did here. However, this doesn’t really help us much - all we have now is a list of some page ID’s that are useless to us.
Getting a List of Objects
For this next part we’ll need a working database, any database, on an instance running the same version that our corrupted database this. This could be the master database - literally any working database. First you’ll want to connect to the database using the Dedicated Administrator Connection.aspx). Connecting through the DAC allows us to query the base tables of the database.
The base table beneath sys.tables is called sys.sysschobjs, and if we can get to that, we can get a list of all the objects in the database, which might be a good start. Having connected to the working database, we can get the sys.sysschobjs details like so:
SELECT * FROM sys.sysschobjs WHERE name = 'sysschobjs'

The only thing I’m looking for here is the object id, provided by the id column. In contrast to all user tables, the system tables have their actual object id stored in the page header, which allows us to easily query for pages by their id. Knowing sys.sysschobjs has ID 34, let’s see if we can get a list of all the pages belonging to it (note that the .Dump() method is native to LinqPad - all it does is to output the resulting objects as a table):
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
db.Pages
.Where(x => x.Header.ObjectID == 34)
.Dump();
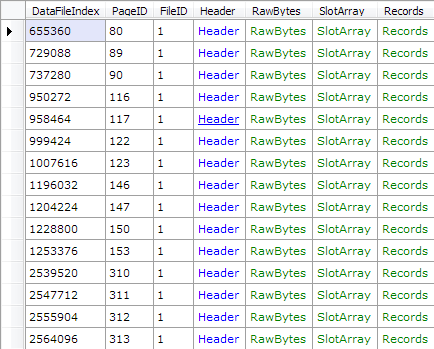
Now that we have a list of pages belonging to the sys.sysschobjs table, we need to retrieve the actual rows from there. Using sp_help on the working database, we can see the underlying schema of sys.sysschobjs:
sp_help 'sys.sysschobjs'
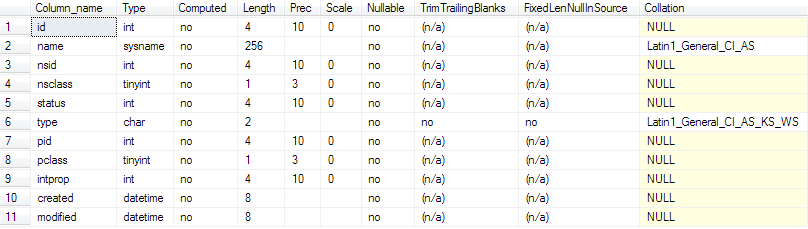
Once we have the schema of sys.sysschobjs, we can make RawDatabase parse the actual rows for us, after which we can filter it down to just the user tables, seeing as we don’t care about procedures, views, indexes and so forth:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
var pages = db.Pages.Where(x => x.Header.ObjectID == 34 && x.Header.Type == PageType.Data);
var records = pages.SelectMany(x => x.Records).Select(x => (RawPrimaryRecord)x);
var rows = RawColumnParser.Parse(records, new IRawType[] {
RawType.Int("id"),
RawType.NVarchar("name"),
RawType.Int("nsid"),
RawType.TinyInt("nsclass"),
RawType.Int("status"),
RawType.Char("type", 2),
RawType.Int("pid"),
RawType.TinyInt("pclass"),
RawType.Int("intprop"),
RawType.DateTime("created"),
RawType.DateTime("modified")
});
rows.Where(x => x["type"].ToString().Trim() == "U")
.Select(x => new {
ObjectID = (int)x["id"],
Name = x["name"]
}).Dump();

We just went from a completely useless suspect database, with no knowledge of the schema, to now having a list of each user table name & object id. Sure, if one of the pages belonging to sys.syschobjs was corrupt, we’d be missing some of the tables without knowing it. Even so, this is a good start, and there are ways of detecting the missing pages (we could look for broken page header references, for example).
Getting Schemas
As we saw for sys.sysschobjs, if we are to parse any of the user table data, we need to know the schema of the tables. The schema happens to be stored in the sys.syscolpars base table, and if we lookup in sys.sysschobjs for ‘sys.syscolpars’, we’ll get an object ID of 41. As we did before, we can get a list of all pages belonging to sys.syscolpars:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
db.Pages
.Where(x => x.Header.ObjectID == 41)
.Dump();
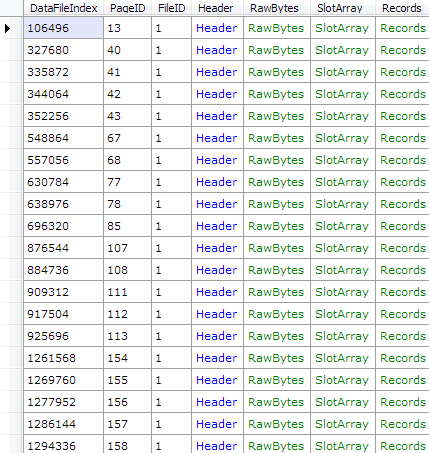
By looking up the schema of sys.syscolpars using sp_help, in the working database, we can parse the actual rows much the same way:
// Parse sys.syscolpars
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
var pages = db.Pages.Where(x => x.Header.ObjectID == 41 && x.Header.Type == PageType.Data);
var records = pages.SelectMany(x => x.Records).Select(x => (RawPrimaryRecord)x);
var rows = RawColumnParser.Parse(records, new IRawType[] {
RawType.Int("id"),
RawType.SmallInt("number"),
RawType.Int("colid"),
RawType.NVarchar("name"),
RawType.TinyInt("xtype"),
RawType.Int("utype"),
RawType.SmallInt("length"),
RawType.TinyInt("prec"),
RawType.TinyInt("scale"),
RawType.Int("collationid"),
RawType.Int("status"),
RawType.SmallInt("maxinrow"),
RawType.Int("xmlns"),
RawType.Int("dflt"),
RawType.Int("chk"),
RawType.VarBinary("idtval")
});
rows.Select(x => new {
ObjectID = (int)x["id"],
ColumnID = (int)x["colid"],
Number = (short)x["number"],
TypeID = (byte)x["xtype"],
Length = (short)x["length"],
Name = x["name"]
}).Dump();
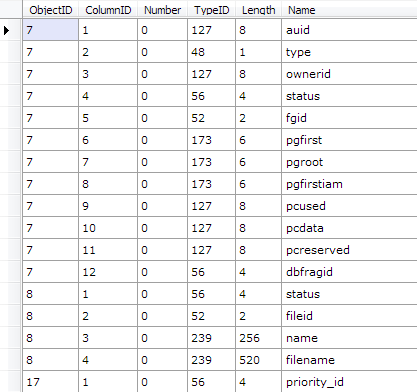
Recovering the Customer Table Schema
While there are 12 tables, none are probably more important than the Customer table. Based on parsing the sys.sysschobjs base table, we know that the customer table has an object ID of 117575457. Let’s try and filter down to just that object ID, using the code above:
rows.Where(x => (int)x["id"] == 117575457).Select(x => new {
ObjectID = (int)x["id"],
ColumnID = (int)x["colid"],
Number = (short)x["number"],
TypeID = (byte)x["xtype"],
Length = (short)x["length"],
Name = x["name"]
}).OrderBy(x => x.Number).Dump();

Running the following query in any working database, we can correlate the TypeID values with the SQL Server type names:
SELECT
*
FROM
sys.types
WHERE
system_type_id IN (56, 104, 231, 167, 36, 61) AND
system_type_id = user_type_id
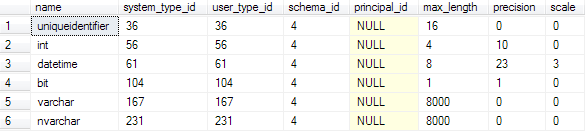
Using the output from syscolpars and the type names, we can now deduce the schema of the Customer table (note that the syscolpars lengths are physical, meaning a length of 16 for an nvarchar column means a logical length of 8):
CREATE TABLE Customer (
CustomerID int,
NameStyle bit,
Title nvarchar(8),
FirstName nvarchar(50),
MiddleName nvarchar(50),
LastName nvarchar(50),
Suffix nvarchar(10),
CompanyName nvarchar(128),
SalesPerson nvarchar(256),
EmailAddress nvarchar(50),
Phone nvarchar(25),
PasswordHash varchar(128),
PasswordSalt varchar(10),
rowguid uniqueidentifier,
ModifiedDate datetime
)
All we need now is to find the pages belonging to the Customer table. That’s slightly easier said than done however. While each object has an object ID, as can be verified using sys.sysschobjs, that object ID is not what’s stored in the page headers, except for system objects. Thus we can’t just query for all pages whose Header.ObjectID == 117575457, as the value 117575457 won’t be stored in the header.
Recovering the Customer Allocation Unit
To find the pages belonging to the Customer table, we’ll first need to find the allocation unit to which it belongs. Unfortunately we already know that page 16 is corrupt - the first page of the sys.sysallocunits table, containing all of the metadata. However, we might just be lucky enough for that first page to contain the allocation units for all of the internal tables, which we do not care about. Let’s see if there are any other pages belonging to sys.sysallocunits:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
db.Pages
.Where(x => x.Header.ObjectID == 7)
.Dump();
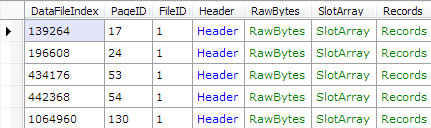
There are 5 other pages available. Let’s try and parse them out so we have as much of the allocation unit data available, as possible. Once again we’ll get the schema from the working database, using sp_help, after which we can parse the remaining rows using RawDatabase. By looking up ‘sysallocunits’ in sysschobjs, we know it has an object ID of 7:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
var pages = db.Pages.Where(x => x.Header.ObjectID == 7 && x.Header.Type == PageType.Data);
var records = pages.SelectMany(x => x.Records).Select(x => (RawPrimaryRecord)x);
var rows = RawColumnParser.Parse(records, new IRawType[] {
RawType.BigInt("auid"),
RawType.TinyInt("type"),
RawType.BigInt("ownerid"),
RawType.Int("status"),
RawType.SmallInt("fgid"),
RawType.Binary("pgfirst", 6),
RawType.Binary("pgroot", 6),
RawType.Binary("pgfirstiam", 6),
RawType.BigInt("pcused"),
RawType.BigInt("pcdata"),
RawType.BigInt("pcreserved"),
RawType.Int("dbfragid")
});
rows.Select(x => new {
AllocationUnitID = (long)x["auid"],
Type = (byte)x["type"],
ContainerID = (long)x["ownerid"]
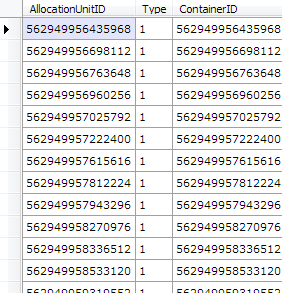
}).Dump();
By itself, we can’t use this data, but we’ll need it in just a moment. First we need to get a hold of the Customer table partitions as well. We do so by looking up the schema of sys.sysrowsets using sp_help, after which we can parse it. Looking up ‘sysrowsets’ in sysschobjs, we know that sys.sysrowsets has an object ID of 5:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
var pages = db.Pages.Where(x => x.Header.ObjectID == 5 && x.Header.Type == PageType.Data);
var records = pages.SelectMany(x => x.Records).Select(x => (RawPrimaryRecord)x);
var rows = RawColumnParser.Parse(records, new IRawType[] {
RawType.BigInt("rowsetid"),
RawType.TinyInt("ownertype"),
RawType.Int("idmajor"),
RawType.Int("idminor"),
RawType.Int("numpart"),
RawType.Int("status"),
RawType.SmallInt("fgidfs"),
RawType.BigInt("rcrows"),
RawType.TinyInt("cmprlevel"),
RawType.TinyInt("fillfact"),
RawType.SmallInt("maxnullbit"),
RawType.Int("maxleaf"),
RawType.SmallInt("maxint"),
RawType.SmallInt("minleaf"),
RawType.SmallInt("minint"),
RawType.VarBinary("rsguid"),
RawType.VarBinary("lockres"),
RawType.Int("dbfragid")
});
rows.Where(x => (int)x["idmajor"] == 117575457).Select(x => new {
RowsetID = (long)x["rowsetid"],
ObjectID = (int)x["idmajor"],
IndexID = (int)x["idminor"]
}).Dump();
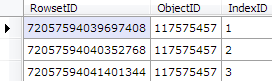
By filtering down to just the Customer table’s object ID, we’ve now got the three partitions that belongs to the table - one for each allocation unit type - ROW_OVERFLOW_DATA (3), LOB_DATA (2) and IN_ROW_DATA (1). We don’t care about LOB and SLOB for now, all we need is the IN_ROW_DATA partition - giving us a RowsetID value of 72057594039697408.
Now that we have the RowsetID, let’s lookup the allocation unit using the data we got from sys.sysallocunits earlier on:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
var pages = db.Pages.Where(x => x.Header.ObjectID == 7 && x.Header.Type == PageType.Data);
var records = pages.SelectMany(x => x.Records).Select(x => (RawPrimaryRecord)x);
var rows = RawColumnParser.Parse(records, new IRawType[] {
RawType.BigInt("auid"),
RawType.TinyInt("type"),
RawType.BigInt("ownerid"),
RawType.Int("status"),
RawType.SmallInt("fgid"),
RawType.Binary("pgfirst", 6),
RawType.Binary("pgroot", 6),
RawType.Binary("pgfirstiam", 6),
RawType.BigInt("pcused"),
RawType.BigInt("pcdata"),
RawType.BigInt("pcreserved"),
RawType.Int("dbfragid")
});
rows.Where(x => (long)x["ownerid"] == 72057594039697408).Select(x => new {
AllocationUnitID = (long)x["auid"],
Type = (byte)x["type"],
ContainerID = (long)x["ownerid"]
}).Dump();

Recovering the Customers
Now that we have the allocation unit ID, we can convert that into the object ID value, as stored in the page headers (big thanks goes out to Paul Randal who was kind enough to blog about the relationship between the allocation unit ID and the page header m_objId and m_indexId fields):
var allocationUnitID = 72057594041270272;
var indexID = allocationUnitID >> 48;
var objectID = (allocationUnitID - (indexID << 48)) >> 16;
Console.WriteLine("IndexID: " + indexID);
Console.WriteLine("ObjectID: " + objectID);
IndexID: 256
ObjectID: 51
Now that we have not only the object ID, but also the index ID, we can easily get a list of all the pages belonging to the Customer table:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
db.Pages
.Where(x => x.Header.ObjectID == 51 && x.Header.IndexID == 256)
.Dump();
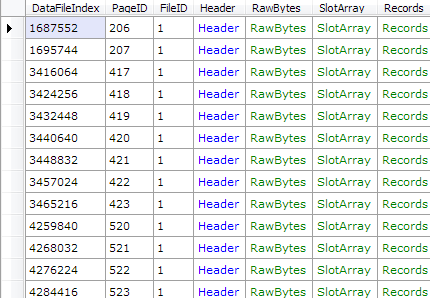
And since we already know the schema for the Customer table, it’s a simple matter of making RawDatabase parse the actual rows:
var db = new RawDatabase(@"D:\MSSQL Databases\AdventureWorksLT2008R2.mdf");
var pages = db.Pages.Where(x => x.Header.ObjectID == 51 && x.Header.IndexID == 256 && x.Header.Type == PageType.Data);
var records = pages.SelectMany(x => x.Records).Select(x => (RawPrimaryRecord)x);
var rows = RawColumnParser.Parse(records, new IRawType[] {
RawType.Int("CustomerID"),
RawType.Bit("NameStyle"),
RawType.NVarchar("Title"),
RawType.NVarchar("FirstName"),
RawType.NVarchar("MiddleName"),
RawType.NVarchar("LastName"),
RawType.NVarchar("Suffix"),
RawType.NVarchar("CompanyName"),
RawType.NVarchar("SalesPerson"),
RawType.NVarchar("EmailAddress"),
RawType.NVarchar("Phone"),
RawType.Varchar("PasswordHash"),
RawType.Varchar("PasswordSalt"),
RawType.UniqueIdentifier("rowguid"),
RawType.DateTime("ModifiedDate")
});
rows.Select(x => new {
CustomerID = (int)x["CustomerID"],
FirstName = (string)x["FirstName"],
MiddleName = (string)x["MiddleName"],
LastName = (string)x["LastName"],
CompanyName = (string)x["CompanyName"],
EmailAddress = (string)x["EmailAddress"]
}).Dump();
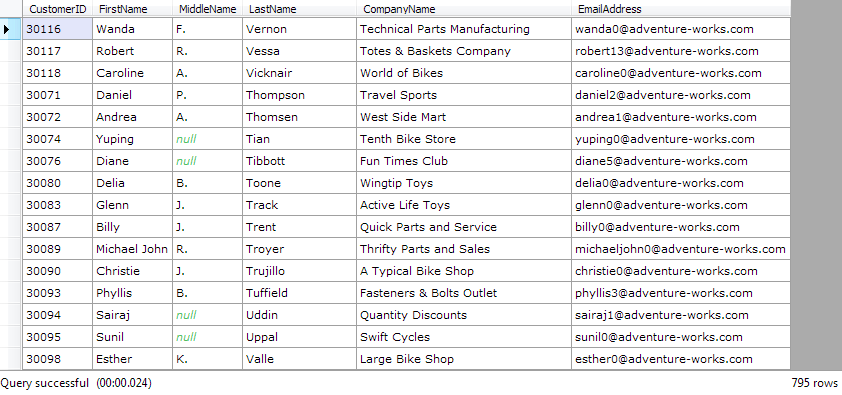
And there we have it. 795 customers were just recovered from an otherwise unrecoverable state. Now it’s just a matter of repeating this process for the other tables as well.
Summary
As I’ve just shown, even though all hope seems lost, there are still options. If you know what you’re doing, a tool like OrcaMDF, or another homebrewn solution, might come in as an invaluable out, during a disaster. This is not, and should never be, a replacement for a good recovery strategy. That being said, not a week goes by without someone posting on a forum somewhere about a corrupt database without any backups.
In this case we went from fatal corruption to recovering 795 customers from the Customer table. Looking at the database, before it was corrupted, there was originally 847 customers in the table. Thus 52 customers were lost due to the corruption. If the pages really are hit by corruption, nothing will get that data back, unless you have a backup. However, if you’re unlucky and end up with metadata corruption, and/or a database that won’t come online, this may be a viable solution.
Should you come across a situation where OrcaMDF might come in handy, I’d love to hear about it - nothing better to hear than success stories! If you don’t feel like going through this process yourself, feel free to contact me; I may be able to help.