Since I originally posted my XmlOutput class I’ve received lots of great feedback. I’m happy that many of you have found it useful.
I have been using the class myself for most of my xml writing requirements lately (in appropriate scenarios) and I’ve ended up augmenting it a little bit. Nothing major, just a couple of helpful changes.
Automatic xml declaration
Instead of manually declaring our xml declaration each time:
XmlOutput xo = new XmlOutput()
.XmlDeclaration()
.Node("root").Within()
.Node("result").Attribute("type", "boolean").InnerText("true");
XmlOutput will instead add an XmlDeclaration with the default parameters:
var xo = new XmlOutput()
.Node("root").Within()
.Node("result").Attribute("type", "boolean").InnerText("true");
Note that this is a breaking change, meaning it will result in different output than the earlier version did. While you could make an XmlDocument without an XmlDeclaration earlier, you can no longer do this.
Checking for duplicate XmlDeclaration
XmlOutput will throw an InvalidOperationException in case an XmlDeclaration has already been added to the document. I do not allow for overwriting the existing XmlDeclaration as XmlOutput really is forward-only writing and since it might often be a flaw that the XmlDeclaration is overwritten.
IDisposable
Just as I used IDisposable to easily write indented text, I’ve done the same to XmlOutput. For smaller bits of xml, it might cause more bloat than good - but it’s optional when to use it. Using IDisposable will simply call EndWithin() in the Dispose method, making indented xml generation more readable.
using (xo.Node("user").Within())
{
xo.Node("username").InnerText("orca");
// Notice that we're not calling EndWithin() after this block as it's implicitly called in the Dispose method
using (xo.Node("numbers").Within())
for (int i = 0; i < 10; i++)
xo.Node("number").Attribute("value", i);
xo.Node("realname").InnerText("Mark S. Rasmussen");
}
InnerText & Attribute object values
Instead of explicitly requiring input values of type string, both InnerText and Attribute will now accept objects for the text values. This allows you to easily pass in integers, StringBuilders and so forth.
ToString override
Another breaking change - ToString will now return the OuterXml value of the XmlOutput object.
Making it easy to do it right
Jakob Andersen made a great post regarding how we might extend XmlOutput to return different kinds of interfaces after different operations. This would allow us to utilize IntelliSense as that’d only show the methods that were possible at the current state.
I started implementing it, but I kept running into walls after having thought it through. Let me start out by representing a state machine displaying the different interfaces involved:
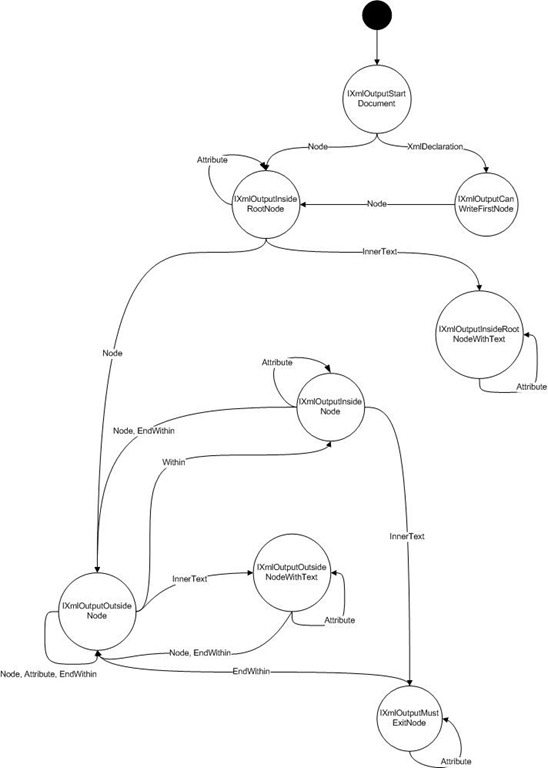
XmlOutput_State_Machine.zip - Visio diagram
So basically, calling a Create method will return an IXmlOutputStartDocument which only supports creating a Node and creating an XmlDeclaration. If you create an XmlDeclaration, you’ll get an IXmlOutputCanWriteFirstNode which only allows you to create a node as that’s the only valid option (ignoring read-only operations). Continuing on, creating a Node at that point will return you an IXmlOutputInsideRootNode which again supports creating either sibling nodes, attributes or innertext. If you call InnerText at this point, we get to a blind alley at the IXmlOutputInsideRootNodeWithText which only allows creating attributes.
Now, on paper, this seems great. The problem however becomes apparent when we start using it:
// xo is now an IXmlOutputCanWriteFirstNode
var xo = XmlOutput.Create()
.XmlDeclaration();
// We've created a root node and ignored the returned IXmlOutputInsideRootNode
xo.Node("root");
// This fails! Since xo is an IXmlOutputCanWriteFirstNode, we're not allowed to create attributes.
// Creating the root node above should've changed our type to IXmlOutputInsideRootNode, but it can't since
// xo is statically typed as an IXmlOutputCanWriteFirstNode
xo.Attribute("hello", "world");
One way to get around this is to create a new variable after each operation, but I don’t really think I’ll have to explain why this is a bad idea:
// xo1 is now an IXmlOutputCanWriteFirstNode
var xo1 = XmlOutput.Create()
.XmlDeclaration();
// xo2 is now an IXmlOutputCanWriteFirstNode
var xo2 = xo1.Node("root");
// xo3 is now an IXmlOutputInsideRootNode
var xo3 = xo2.Attribute("hello", "world");
Another issue is that we’ll need to have the types change based on the stack level. Imagine we create an IXmlOutputOutsideNode like this:
XmlOutput.Create -> Node –> Node
This will result in us having create a single node inside the root node. We are still within the root node scope (creating another Node will also be a child of the rootnode, but a sibling of the just created node). The problem is, at this point we’re able to call EndWithin() since the IXmlOutputOutsideNode interface allows it, but we can’t move out of the root node scope as we’re on the bottom of the stack. Unless we create interfaces like IXmlOutputOutsideNodeLevel1, Level2, LevelX interfaces, we can’t really support allowing and disallowing EndWithin depending on stack level - and this is a mess I don’t want to get into.
So what’s the conclusion? While the interface based help in regards to fluent interfaces is a great idea, it’s not really easy to implement, as least not as long as we need some kind of recursive functionality on our interfaces. If we had a simple linear fluent interface, it might be easier for us to support it, though we will still have the variable issue.
Code
using System;
using System.Collections.Generic;
using System.Xml;
namespace Improve.Framework.Xml
{
public class XmlOutput : IDisposable
{
// The internal XmlDocument that holds the complete structure.
XmlDocument xd = new XmlDocument();
// A stack representing the hierarchy of nodes added. nodeStack.Peek() will always be the current node scope.
Stack<XmlNode> nodeStack = new Stack<XmlNode>();
// Whether the next node should be created in the scope of the current node.
bool nextNodeWithin;
// The current node. If null, the current node is the XmlDocument itself.
XmlNode currentNode;
// Whether the Xml declaration has been added to the document
bool xmlDeclarationHasBeenAdded = false;
/// <summary>
/// Overrides ToString to easily return the current outer Xml
/// </summary>
/// <returns></returns>
public override string ToString()
{
return GetOuterXml();
}
/// <summary>
/// Returns the string representation of the XmlDocument.
/// </summary>
/// <returns>A string representation of the XmlDocument.</returns>
public string GetOuterXml()
{
return xd.OuterXml;
}
/// <summary>
/// Returns the XmlDocument
/// </summary>
/// <returns></returns>
public XmlDocument GetXmlDocument()
{
return xd;
}
/// <summary>
/// Changes the scope to the current node.
/// </summary>
/// <returns>this</returns>
public XmlOutput Within()
{
nextNodeWithin = true;
return this;
}
/// <summary>
/// Changes the scope to the parent node.
/// </summary>
/// <returns>this</returns>
public XmlOutput EndWithin()
{
if (nextNodeWithin)
nextNodeWithin = false;
else
nodeStack.Pop();
return this;
}
/// <summary>
/// Adds an XML declaration with the most common values.
/// </summary>
/// <returns>this</returns>
public XmlOutput XmlDeclaration() { return XmlDeclaration("1.0", "utf-8", ""); }
/// <summary>
/// Adds an XML declaration to the document.
/// </summary>
/// <param name="version">The version of the XML document.</param>
/// <param name="encoding">The encoding of the XML document.</param>
/// <param name="standalone">Whether the document is standalone or not. Can be yes/no/(null || "").</param>
/// <returns>this</returns>
public XmlOutput XmlDeclaration(string version, string encoding, string standalone)
{
// We can't add an XmlDeclaration once nodes have been added, as the standard declaration will already have been added
if (nodeStack.Count > 0)
throw new InvalidOperationException("Cannot add XmlDeclaration once nodes have been added to the XmlOutput.");
// Create & add the XmlDeclaration
XmlDeclaration xdec = xd.CreateXmlDeclaration(version, encoding, standalone);
xd.AppendChild(xdec);
xmlDeclarationHasBeenAdded = true;
return this;
}
/// <summary>
/// Creates a node. If no nodes have been added before, it'll be the root node, otherwise it'll be appended as a child of the current node.
/// </summary>
/// <param name="name">The name of the node to create.</param>
/// <returns>this</returns>
public XmlOutput Node(string name)
{
XmlNode xn = xd.CreateElement(name);
// If nodeStack.Count == 0, no nodes have been added, thus the scope is the XmlDocument itself.
if (nodeStack.Count == 0)
{
// If an XmlDeclaration has not been added, add the standard declaration
if (!xmlDeclarationHasBeenAdded)
XmlDeclaration();
// Add the child element to the XmlDocument directly
xd.AppendChild(xn);
// Automatically change scope to the root DocumentElement.
nodeStack.Push(xn);
}
else
{
// If this node should be created within the scope of the current node, change scope to the current node before adding the node to the scope element.
if (nextNodeWithin)
{
nodeStack.Push(currentNode);
nextNodeWithin = false;
}
nodeStack.Peek().AppendChild(xn);
}
currentNode = xn;
return this;
}
/// <summary>
/// Sets the InnerText of the current node using CData.
/// </summary>
/// <param name="text"></param>
/// <returns></returns>
public XmlOutput InnerText(object text)
{
return InnerText(text.ToString(), true);
}
/// <summary>
/// Sets the InnerText of the current node.
/// </summary>
/// <param name="text">The text to set.</param>
/// <returns>this</returns>
public XmlOutput InnerText(object text, bool useCData)
{
if (useCData)
currentNode.AppendChild(xd.CreateCDataSection(text.ToString()));
else
currentNode.AppendChild(xd.CreateTextNode(text.ToString()));
return this;
}
/// <summary>
/// Adds an attribute to the current node.
/// </summary>
/// <param name="name">The name of the attribute.</param>
/// <param name="value">The value of the attribute.</param>
/// <returns>this</returns>
public XmlOutput Attribute(string name, object value)
{
XmlAttribute xa = xd.CreateAttribute(name);
xa.Value = value.ToString();
currentNode.Attributes.Append(xa);
return this;
}
/// <summary>
/// Same as calling EndWithin directly, allows for using the using statement
/// </summary>
public void Dispose()
{
EndWithin();
}
}
}