In this post I’ll be looking at the internal storage mechanism that supports sparse columns. For an introduction to what sparse columns are and when they ought to be used, take a look here.
Sparse columns, whether fixed or variable length, or not stored together with the normal columns in a record. Instead, they’re all stored in a hidden variable length column at the very end of the record (barring the potential 14 byte structure that may be stored when using versioning).
Creating and finding a sparse vector
Let’s create a sample table and insert a couple of test rows:
CREATE TABLE Sparse
(
ID int,
A int SPARSE,
B int SPARSE,
C int SPARSE,
D int SPARSE,
E int SPARSE
)
INSERT INTO Sparse (ID, B, E) VALUES (1, 3, 1234)
INSERT INTO Sparse (ID, A, B) VALUES (45, 243, 328)
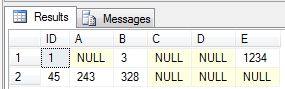
As you’d expect, a SELECT * yields the following result:
Now let’s use DBCC IND to find the lone data pages ID, and then check out the stored record using DBCC PAGE:
DBCC IND (X, 'Sparse', -1)

DBCC PAGE (X, 1, 4328, 3)
This gives us two records, the first one looking like this:
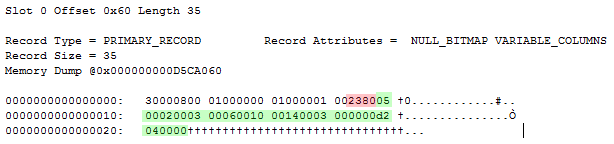
In a previous post I detailed how we identify complex columns like sparse vectors, so I won’t go into too much detail there. The two red bytes is the single entry in the variable length offset array, with a value of 0x8023 = 32.803. Once we flip the high order bit (identifying this column as a complex column) we get an offset value of 35. Thus we know that the remaining 20 bytes in the record is our sparse vector.
The sparse vector structure
So what do those 20 bytes contain? The sparse vector structure looks like this:
| Name | Bytes | Description |
| Complex column header | 2 | The header identifies the type of complex column that we’re dealing with. A value of 5 denotes a sparse vector. |
| Sparse column count | 2 | Number of sparse column values that are stored in the vector – only columns that have values are included in the vector. |
| Column ID set | 2 Number of sparse columns with values | Each sparse column storing a value will use two bytes to store the ID of the column (as seen in sys.columns). |
| Column offset table | 2 Number of sparse columns with values | Just like the record variable offset array, this stores two bytes per sparse column with a value. The value denotes the end of the actual value in the sparse vector. |
| Sparse data | Total length of all sparse column data values. |
It’s interesting to note that unlike the normal record structure, fixed length and variable length sparse columns are stored in exactly the same way – both have an entry in the offset table, even though the fixed length values don’t differ in length.
Looking at a record
Going back to our record structure, I’ve colored it according to separate the different parts of the vector:
0x05000200030006001000140003000000d2040000
Note that I’ve byte swapped the following byte references.
The first two bytes 0x0005 == 5 contains the complex column ID.
The next two bytes 0x0002 == 2 contains the number of sparse columns that are non-null, that is, they have a value stored in the sparse vector.
The purple part stores two bytes per column, namely the column IDs of the stored columns. 0x0003 == 3, 0x0006 == 6.
Next up we have the green part – again storing two bytes per column, this time the offsets in the sparse vector. 0x0010 == 16, 0x0014 == 20.
Finally we have the values themselves. We know that the first column has an ID of 3 and it’s data ends et offset 16. Since the first 12 bytes are made up of the header, the actual values are stored in bytes 13-16: 0x00000003 == 3. The second value ends at offset 20, meaning it’s stored in bytes 17-20: 0x000004d2 == 1.234.
Correlating sparse vector values with sys.columns
Now that we have the values, we just need to correlate them with the columns whose value they store. Let’s select the columns in our Sparse table:
SELECT
*
FROM
sys.columns
WHERE
object_id = OBJECT_ID('Sparse')
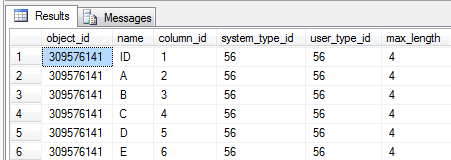
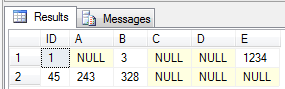
And there we have it – the value 3 was stored in column_id = 3 => B. The value 1.234 was stored in column_id = 6 => E. Coincidentally, that matches up with our originally select query:
The same procedure can be repeated for the second record, but I’m going to leave that as an exercise for the reader :)
Writing a sparse vector parser in C
Once we know the structure of the sparse vector, writing a parser in C# is surprisingly simple:
using System;
using System.Collections.Generic;
using System.Linq;
namespace OrcaMDF.Core.Engine
{
/// <summary>
/// Parses sparse vectors as stored in records for tables containing sparse columns.
/// </summary>
public class SparseVectorParser
{
public short ColumnCount { get; private set; }
public IDictionary<short, byte[]> ColumnValues { get; private set; }
public SparseVectorParser(byte[] bytes)
{
// First two bytes must have the value 5, indicating this is a sparse vector
short complexColumnID = BitConverter.ToInt16(bytes, 0);
if (complexColumnID != 5)
throw new ArgumentException("Input bytes does not contain a sparse vector.");
// Number of columns contained in this sparse vector
ColumnCount = BitConverter.ToInt16(bytes, 2);
// For each column, read the data into the columnValues dictionary
ColumnValues = new Dictionary<short, byte[]>();
short columnIDSetOffset = 4;
short columnOffsetTableOffset = (short)(columnIDSetOffset + 2 * ColumnCount);
short columnDataOffset = (short)(columnOffsetTableOffset + 2 * ColumnCount);
for(int i=0; i<ColumnCount; i++)
{
// Read ID, data offset and data from vector
short columnID = BitConverter.ToInt16(bytes, columnIDSetOffset);
short columnOffset = BitConverter.ToInt16(bytes, columnOffsetTableOffset);
byte[] data = bytes.Take(columnOffset).Skip(columnDataOffset).ToArray();
// Add ID + data to dictionary
ColumnValues.Add(columnID, data);
// Increment both ID and offset offsets by two bytes
columnIDSetOffset += 2;
columnOffsetTableOffset += 2;
columnDataOffset = columnOffset;
}
}
}
}
I won’t go into the code as it’s documented and follows the procedure we just went through. A quick test verifies that it achieves the same results as we just did by hand:
[TestFixture]
public class SparseVectorParserTests
{
[Test]
public void Parse()
{
byte[] bytes = new byte [] { 0x05, 0x00, 0x02, 0x00, 0x03, 0x00, 0x06, 0x00, 0x10, 0x00, 0x14, 0x00, 0x03, 0x00, 0x00, 0x00, 0xd2, 0x04, 0x00, 0x00 };
var parser = new SparseVectorParser(bytes);
Assert.AreEqual(2, parser.ColumnCount);
Assert.AreEqual(3, BitConverter.ToInt32(parser.ColumnValues[3], 0));
Assert.AreEqual(1234, BitConverter.ToInt32(parser.ColumnValues[6], 0));
}
}
You can check out the full code at the OrcaMDF Github repository.